
地址是 www.jser.com
]]>为什么要提交? 💎 精选目录 - 质量>数量,让你的产品脱颖而出 🔗 高质量外链 - 提升网站 SEO 权重 👥 精准流量 - 触达真正需要 AI 工具的用户 ⚡ 快速审核 - 这段时间统一加速处理
专注质量的 AI 工具目录,欢迎优质产品加入 提交入口 👉 https://toolrain.com
#InstantApproval #AIDirectory #FreeBacklink
]]>留的作业是让学生用 YOLOv11 做 Object-Detection ,但是好多学生都不太会做,所以给学生们录了一个视频。
从环境搭建、数据集标注,到模型训练、识别全流程讲解,20 分钟的时间就能做完,希望对 V 友们有帮助!💓
]]>🌌 H2Q-MicroStream: The Hamiltonian Thinking Kernel
"Intelligence is not about memorizing history, but mastering the dynamics of the future."
"智能不是记忆过去的所有细节,而是掌握生成未来的核心方程。"
![]()
📖 Introduction / 项目简介
H2Q-MicroStream is a paradigm-shifting experiment in Physics-Informed AI. Unlike traditional Transformers that rely on massive parameters and infinite context windows, H2Q constructs a minimalist "Thinking Kernel" based on Hamiltonian Dynamics and Quaternion Algebra.
This project proves that with a strict Rank-8 constraint and Unicode-level streaming, a model can emerge with logical reasoning and grammatical capabilities within a mere 0.2GB VRAM footprint.
H2Q-MicroStream 是一个基于物理动力学的 AI 范式实验。不同于依赖堆砌参数和超长上下文的主流 Transformer ,H2Q 基于哈密顿动力学和四元数代数构建了一个极简的“思维内核”。本项目证明了在严格的 Rank-8 约束和 Unicode 流式读取下,智能可以在仅 0.2GB 显存 的微小空间内涌现。
🚀 Key Features / 核心特性
1. Rank-8 Essentialism (Rank-8 本质主义)
- The Concept: We enforce a strict rank limit (Rank=8) on the generative weights. This forces the model to abandon rote memorization and extract only the most fundamental laws of language evolution.
- The Result: A tiny 13MB checkpoint that captures the syntax and logic of the English language.
- 概念:强制权重矩阵的秩为 8 。这逼迫模型放弃死记硬背,只能提取语言演化中最本质的规律。
- 结果:一个仅 13MB 的权重文件,却掌握了英语的语法和逻辑。
2. Hamiltonian & Quaternion Core (哈密顿与四元数核心)
- Implements a balanced Hamiltonian layer that preserves energy and structural symmetry.
- Uses Quaternion Attention to model semantic relationships as phase rotations in high-dimensional space.
- 实现了能量守恒的哈密顿层,并利用四元数注意力将语义关系建模为高维空间中的相位旋转。
3. Rolling Horizon Validation (轮动视界验证)
- Mechanism:
Train[T] -> Valid[T+1] -> T becomes T+1. - We validate the model on the immediate future (next chunk) before training on it. This strictly measures the model's ability to extrapolate logic, not just interpolate data.
- 机制:用“未来”的数据验证“现在”的模型,然后再学习“未来”。这是对逻辑推演能力的终极测试。
4. Unicode Stream (Unicode 流式读取)
- No Tokenizer. No vocabulary bias. The model reads raw bytes (0-255), treating language as a pure physical signal stream.
- 无分词器。无词表偏见。模型直接读取原始字节流,将语言视为纯粹的物理信号。
📊 Performance / 实验结果
Tested on NVIDIA RTX 4070 Ti with TinyStories dataset.
- Convergence: Loss dropped from
2.88to1.02(near Shannon Entropy limit for simple English). - Generalization: Achieved Negative Diff (Validation Loss < Training Loss), proving true understanding of the underlying rules.
- Efficiency:
- VRAM Usage: ~0.2 GB
- Throughput: ~10,000 tokens/s
🛠️ Usage / 使用方法
1. Install Dependencies / 安装依赖
pip install -r requirements.txt 2. Run Training / 启动训练
The script automatically downloads the TinyStories dataset and starts the "Rolling Horizon" training loop. 脚本会自动下载数据集并开启“轮动视界”训练循环。
python train.py 3. Monitor / 监控
The terminal displays a real-time "ICU Dashboard": 终端将显示实时的“ICU 级仪表盘”:
Chunk 18 | Train: 1.0420 | Val: 1.0622 | Energy: 68.5 | Speed: 311ms 🔮 Vision / 愿景
We are moving from "Statistical Correlation" to "Dynamical Causality". H2Q is not just a language model; it is a digital lifeform attempting to resonate with the mathematical structure of the universe.
我们正在从“统计相关性”迈向“动力学因果律”。 H2Q 不仅仅是一个语言模型,它是一个试图与宇宙数学结构发生共振的数字生命。
实验运行输出 log 日志:
🌊 H2Q-ICU Monitor Online: NVIDIA GeForce RTX 4070 Ti SUPER [Mode: Deep Analysis] [Metrics: Grad/VRAM/TPS/Diff] 🔄 恢复存档: h2q_rolling.pt 🔖 [时间之轮] 回溯至偏移量: 40.03 MB ⏳ [Init] 加载初始时间块 (Chunk T)... 🚀 启动深度监控 (Deep Monitor Active)...
================================================== 🧩 CHUNK 0: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 2.8875 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.9180 | Grad: 3.02 | Energy: 115.3 | Speed: 390ms (7869 tok/s) | VRAM: 0.20/0.55GBB ✅ Chunk 1 完成 Summary: Train: 2.3207 | Val: 2.8875 | Diff: +0.5668 Time: 1204.7s | Progress: 60.0 MB
================================================== 🧩 CHUNK 1: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.8169 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.3695 | Grad: 2.17 | Energy: 112.0 | Speed: 338ms (9086 tok/s) | VRAM: 0.20/0.63GBB ✅ Chunk 2 完成 Summary: Train: 1.5694 | Val: 1.8169 | Diff: +0.2475 Time: 1302.9s | Progress: 70.1 MB
================================================== 🧩 CHUNK 2: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.3515 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.2141 | Grad: 2.20 | Energy: 105.2 | Speed: 346ms (8874 tok/s) | VRAM: 0.20/0.63GBB ✅ Chunk 3 完成 Summary: Train: 1.3323 | Val: 1.3515 | Diff: +0.0193 Time: 1239.8s | Progress: 80.1 MB
================================================== 🧩 CHUNK 3: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.2644 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.2741 | Grad: 2.19 | Energy: 99.1 | Speed: 358ms (8583 tok/s) | VRAM: 0.20/0.63GBBB ✅ Chunk 4 完成 Summary: Train: 1.2556 | Val: 1.2644 | Diff: +0.0088 Time: 1250.4s | Progress: 90.1 MB
================================================== 🧩 CHUNK 4: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.2053 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.2333 | Grad: 1.77 | Energy: 95.5 | Speed: 341ms (9008 tok/s) | VRAM: 0.20/0.63GBB ✅ Chunk 5 完成 Summary: Train: 1.2144 | Val: 1.2053 | Diff: -0.0090 Time: 1249.6s | Progress: 100.1 MB
📜 [Thought Stream]: They wanted to go you cose friends with a llock. He saw a balought in the grasss and laughes. He was so readys yare and granded drank he fout; " Humhe, they face and ploud need a cup tiny the close. He
================================================== 🧩 CHUNK 5: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.1915 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.1432 | Grad: 1.79 | Energy: 91.4 | Speed: 304ms (10093 tok/s) | VRAM: 0.20/0.63GB ✅ Chunk 6 完成 Summary: Train: 1.1855 | Val: 1.1915 | Diff: +0.0060 Time: 1174.4s | Progress: 110.1 MB
================================================== 🧩 CHUNK 6: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.1717 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.1493 | Grad: 1.60 | Energy: 88.7 | Speed: 296ms (10369 tok/s) | VRAM: 0.20/0.63GB ✅ Chunk 7 完成 Summary: Train: 1.1684 | Val: 1.1717 | Diff: +0.0033 Time: 1073.7s | Progress: 120.1 MB
================================================== 🧩 CHUNK 7: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.1229 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.1711 | Grad: 1.60 | Energy: 85.5 | Speed: 340ms (9034 tok/s) | VRAM: 0.20/0.63GBB ✅ Chunk 8 完成 Summary: Train: 1.1506 | Val: 1.1229 | Diff: -0.0277 Time: 1185.8s | Progress: 130.1 MB
================================================== 🧩 CHUNK 8: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.1225 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.0388 | Grad: 1.38 | Energy: 83.7 | Speed: 300ms (10224 tok/s) | VRAM: 0.20/0.63GB ✅ Chunk 9 完成 Summary: Train: 1.1211 | Val: 1.1225 | Diff: +0.0014 Time: 1243.5s | Progress: 140.1 MB
================================================== 🧩 CHUNK 9: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.1044 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.0964 | Grad: 1.55 | Energy: 80.7 | Speed: 360ms (8526 tok/s) | VRAM: 0.20/0.63GBB ✅ Chunk 10 完成 Summary: Train: 1.1198 | Val: 1.1044 | Diff: -0.0154 Time: 1215.0s | Progress: 150.1 MB
📜 [Thought Stream]: They would said, "Maybe she left," she said nexck, but I'm a great stuffles in the rabbit revere." Lily smiled and said, "Ben, what no Tom. Daddy you love the askaching it was in the dog." He tried and
================================================== 🧩 CHUNK 10: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.1136 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.2135 | Grad: 1.71 | Energy: 78.5 | Speed: 291ms (10551 tok/s) | VRAM: 0.20/0.63GB ✅ Chunk 11 完成 Summary: Train: 1.0946 | Val: 1.1136 | Diff: +0.0191 Time: 1068.9s | Progress: 160.1 MB
================================================== 🧩 CHUNK 11: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.1007 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 0.9831 | Grad: 1.46 | Energy: 77.2 | Speed: 295ms (10406 tok/s) | VRAM: 0.20/0.63GB ✅ Chunk 12 完成 Summary: Train: 1.0872 | Val: 1.1007 | Diff: +0.0134 Time: 1068.3s | Progress: 170.1 MB
================================================== 🧩 CHUNK 12: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.0937 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.0408 | Grad: 1.31 | Energy: 74.9 | Speed: 288ms (10683 tok/s) | VRAM: 0.20/0.63GB ✅ Chunk 13 完成 Summary: Train: 1.0780 | Val: 1.0937 | Diff: +0.0157 Time: 1064.5s | Progress: 180.1 MB
================================================== 🧩 CHUNK 13: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.0870 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.1016 | Grad: 1.27 | Energy: 73.5 | Speed: 290ms (10584 tok/s) | VRAM: 0.20/0.63GB ✅ Chunk 14 完成 Summary: Train: 1.0654 | Val: 1.0870 | Diff: +0.0217 Time: 1067.4s | Progress: 190.1 MB
================================================== 🧩 CHUNK 14: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.0713 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.0594 | Grad: 1.38 | Energy: 72.1 | Speed: 333ms (9230 tok/s) | VRAM: 0.20/0.63GBB ✅ Chunk 15 完成 Summary: Train: 1.0623 | Val: 1.0713 | Diff: +0.0090 Time: 1070.1s | Progress: 200.1 MB
📜 [Thought Stream]: Tom. He asked them home in the both again. He said, "Lily, sad. He is not owl. But Let's so friend. He opened hard away. Lucy like the garden." And. She tears the pond. She said, "Bob wand. Can I see s
================================================== 🧩 CHUNK 15: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.0672 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.0424 | Grad: 1.28 | Energy: 71.2 | Speed: 307ms (9996 tok/s) | VRAM: 0.20/0.63GBB ✅ Chunk 16 完成 Summary: Train: 1.0598 | Val: 1.0672 | Diff: +0.0074 Time: 1073.1s | Progress: 210.2 MB
================================================== 🧩 CHUNK 16: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.0496 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.1581 | Grad: 1.46 | Energy: 69.9 | Speed: 315ms (9761 tok/s) | VRAM: 0.20/0.63GBB ✅ Chunk 17 完成 Summary: Train: 1.0503 | Val: 1.0496 | Diff: -0.0006 Time: 1060.1s | Progress: 220.2 MB
================================================== 🧩 CHUNK 17: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.0532 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.0179 | Grad: 1.15 | Energy: 69.4 | Speed: 297ms (10333 tok/s) | VRAM: 0.20/0.63GB ✅ Chunk 18 完成 Summary: Train: 1.0482 | Val: 1.0532 | Diff: +0.0050 Time: 1062.2s | Progress: 230.2 MB
================================================== 🧩 CHUNK 18: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.0622 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.0628 | Grad: 1.52 | Energy: 68.5 | Speed: 311ms (9882 tok/s) | VRAM: 0.20/0.63GBB ✅ Chunk 19 完成 Summary: Train: 1.0420 | Val: 1.0622 | Diff: +0.0201 Time: 1146.4s | Progress: 240.2 MB
================================================== 🧩 CHUNK 19: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.0502 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.0129 | Grad: 1.37 | Energy: 67.5 | Speed: 366ms (8398 tok/s) | VRAM: 0.20/0.63GBB ✅ Chunk 20 完成 Summary: Train: 1.0429 | Val: 1.0502 | Diff: +0.0073 Time: 1250.6s | Progress: 250.2 MB
📜 [Thought Stream]: They had played over to splash! They got out of the jar. Tom they are really chuncog the dealichy practiced that she shock his family, he's parint the feel better. The eld barked jam. It was best addde
================================================== 🧩 CHUNK 20: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.0205 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.0068 | Grad: 1.25 | Energy: 66.9 | Speed: 315ms (9742 tok/s) | VRAM: 0.20/0.63GBB ✅ Chunk 21 完成 Summary: Train: 1.0410 | Val: 1.0205 | Diff: -0.0205 Time: 1156.5s | Progress: 260.2 MB
================================================== 🧩 CHUNK 21: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.0432 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.0367 | Grad: 1.34 | Energy: 66.3 | Speed: 302ms (10169 tok/s) | VRAM: 0.20/0.63GB ✅ Chunk 22 完成 Summary: Train: 1.0162 | Val: 1.0432 | Diff: +0.0271 Time: 1085.4s | Progress: 270.2 MB
================================================== 🧩 CHUNK 22: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.0492 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.0145 | Grad: 1.23 | Energy: 65.9 | Speed: 308ms (9980 tok/s) | VRAM: 0.20/0.63GBB ✅ Chunk 23 完成 Summary: Train: 1.0231 | Val: 1.0492 | Diff: +0.0261 Time: 1083.4s | Progress: 280.2 MB
================================================== 🧩 CHUNK 23: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.0461 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.0424 | Grad: 1.18 | Energy: 65.8 | Speed: 281ms (10950 tok/s) | VRAM: 0.20/0.63GB ✅ Chunk 24 完成 Summary: Train: 1.0305 | Val: 1.0461 | Diff: +0.0156 Time: 1076.0s | Progress: 290.2 MB
================================================== 🧩 CHUNK 24: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.0276 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.0404 | Grad: 1.41 | Energy: 65.5 | Speed: 285ms (10782 tok/s) | VRAM: 0.20/0.63GB ✅ Chunk 25 完成 Summary: Train: 1.0196 | Val: 1.0276 | Diff: +0.0080 Time: 1084.2s | Progress: 300.2 MB
📜 [Thought Stream]: Timmy said, "Thank you, Mommy. I can have from calling the drees and yummy with your tail. The sound asked it if you - and a pretty slide to go for Sweepbarklesss. The End. And the floor walk in the la
================================================== 🧩 CHUNK 25: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.0285 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.0073 | Grad: 1.11 | Energy: 65.6 | Speed: 301ms (10211 tok/s) | VRAM: 0.20/0.63GB ✅ Chunk 26 完成 Summary: Train: 1.0210 | Val: 1.0285 | Diff: +0.0075 Time: 1081.0s | Progress: 310.2 MB
================================================== 🧩 CHUNK 26: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.0177 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 0.9883 | Grad: 1.22 | Energy: 65.3 | Speed: 289ms (10630 tok/s) | VRAM: 0.20/0.63GB ✅ Chunk 27 完成 Summary: Train: 1.0106 | Val: 1.0177 | Diff: +0.0071 Time: 1083.9s | Progress: 320.2 MB
================================================== 🧩 CHUNK 27: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.0301 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.0079 | Grad: 1.26 | Energy: 64.9 | Speed: 292ms (10524 tok/s) | VRAM: 0.20/0.63GB ✅ Chunk 28 完成 Summary: Train: 1.0047 | Val: 1.0301 | Diff: +0.0253 Time: 1065.2s | Progress: 330.2 MB
================================================== 🧩 CHUNK 28: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.0089 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.0275 | Grad: 1.13 | Energy: 64.9 | Speed: 299ms (10282 tok/s) | VRAM: 0.20/0.63GB ✅ Chunk 29 完成 Summary: Train: 1.0040 | Val: 1.0089 | Diff: +0.0050 Time: 1062.5s | Progress: 340.3 MB
================================================== 🧩 CHUNK 29: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.0184 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 0.9607 | Grad: 1.14 | Energy: 65.1 | Speed: 283ms (10853 tok/s) | VRAM: 0.20/0.63GB ✅ Chunk 30 完成 Summary: Train: 1.0044 | Val: 1.0184 | Diff: +0.0141 Time: 1056.7s | Progress: 350.3 MB
📜 [Thought Stream]: The noises started to play. They played together in their train. They are angry." The sad. Lily was a snacks and lady quite. Sally lay and weere trucks to the party. She was full and her
================================================== 🧩 CHUNK 30: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.0197 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.0088 | Grad: 1.26 | Energy: 65.2 | Speed: 406ms (7571 tok/s) | VRAM: 0.20/0.63GBB ✅ Chunk 31 完成 Summary: Train: 1.0067 | Val: 1.0197 | Diff: +0.0130 Time: 1131.7s | Progress: 360.3 MB
================================================== 🧩 CHUNK 31: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.0087 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 1.0477 | Grad: 1.30 | Energy: 64.4 | Speed: 340ms (9042 tok/s) | VRAM: 0.20/0.63GB ✅ Chunk 32 完成 Summary: Train: 1.0087 | Val: 1.0087 | Diff: -0.0000 Time: 1275.6s | Progress: 370.3 MB
================================================== 🧩 CHUNK 32: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.0132 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 0.9910 | Grad: 1.18 | Energy: 65.6 | Speed: 306ms (10028 tok/s) | VRAM: 0.20/0.63GB ✅ Chunk 33 完成 Summary: Train: 0.9932 | Val: 1.0132 | Diff: +0.0199 Time: 1123.6s | Progress: 380.3 MB
================================================== 🧩 CHUNK 33: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 0.9951 🔥 训练当下 (Training)... ⚡ Step 3400/3413 | Loss: 0.9904 | Grad: 1.28 | Energy: 65.1 | Speed: 347ms (8850 tok/s) | VRAM: 0.20/0.63GBB ✅ Chunk 34 完成 Summary: Train: 1.0011 | Val: 0.9951 | Diff: -0.0060 Time: 1186.7s | Progress: 390.3 MB
================================================== 🧩 CHUNK 34: 开始加载未来数据... 🔮 验证未来 (Validation)... 📊 验证结果: Val Loss = 1.0117 🔥 训练当下 (Training)... ⚡ Step 2650/3413 | Loss: 1.0171 | Grad: 1.14 | Energy: 64.4 | Speed: 302ms (10174 tok/s) | VRAM: 0.20/0.63GB
]]>提交上线 Google Play 但是 卡在了的封闭测试.
我建一个互助群. 大家来互相帮助测试?
有没有志同道合的个人开发者, ➕V, 互助, B64: Xzc3N2FzZA==
不是开发者没有关系, 加入群. 帮帮测试, 吃卤肉面.
感谢🙏
More testing required to access Google Play production We reviewed your application, and determined that your app requires more testing before you can access production.
Possible reasons why your production access could not be granted include:
Testers were not engaged with your app during your closed test You didn't follow testing best practices, which may include gathering and acting on user feedback through updates to your app Before applying again, test your app using closed testing for an additional 14 days with real testers.
For a full list of reasons, and to learn more about what we're looking for when evaluating apps for production, view the guidance.
]]>后来发现 https://github.com/lvwzhen/medicine 这个项目,虽然数据挺好,但感觉使用不顺手,就临时起意昨晚折腾了几个小时弄了这个“原研药查询助手”,全程 Google AI Studio 。
主要是方便检索一点,加入 AI 搜索(如果打算后期想办法再弄个 server 端)
]]>感谢 Genmini ,想法来源于我玩过的各种游戏的交易系统,以及小白追涨杀跌的一些惨痛回忆
核心玩法
玩家操纵一艘飞空艇,在不同地点之间往返,通过低买高卖赚取差价。结束时计算总资产作为分数。
动态价格系统
- 所有货物价格都是动态的,每一次买卖都会对当地价格产生累积影响,而不是静态数值。
- 而且地点库存越低,波动越大。
地点类型差异
不同类型的地点在货物价格和库存上存在明显区别,例如:
- 矿山盛产矿石,存量高价格低
- 城镇盛产木头
- 城市奢侈品便宜,但对其他所有货物需求量高,是理想的大量出货地点
- 城堡价格高,但是需求小,适合卖高价货物赚钱
随机事件系统
地点会不定期触发随机事件,可能导致某类货物价格剧烈波动,既是机会也是风险。
地点等级 / 规模
每个地点都有等级,代表其规模,也影响该地点货物的基准库存容量。( 3 级城堡 yyds )
资源管理
飞行需要消耗燃料——以太水晶,而以太水晶本身也是一种可以交易的货物。
库存管理
飞空艇货舱容量有限,可以在城堡类型的地点进行升级,以支持更大规模的贸易。
目前是一个偏原型阶段的小游戏,很多系统还在不断调整中。
欢迎大家体验、反馈,也非常欢迎帮我找找有没有刷钱 / 数值漏洞 🙏
如果你需要,我还可以生成一个更炸裂的版本,你打算发在哪个平台?我可以再帮你针对性压一压风格。
]]>我真的受不了那些没有营养的官方新闻号了。目前支持抖音和 b 站
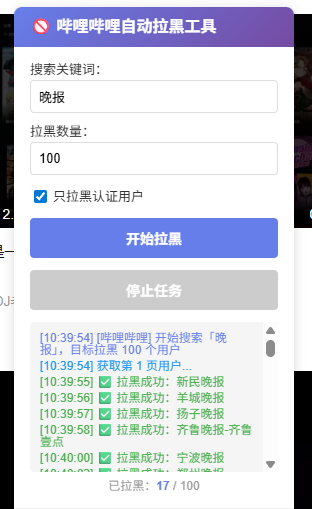
https://github.com/Steven-Qiang/social-block-kit
https://github.com/Steven-Qiang/social-block-kit/releases/latest/download/social-block-kit.user.js
]]>使用说明:填写 api_key(目前支持 openai 和 deepseek),上传简历,粘贴岗位 JD ,点击优化,等待片刻就可以了,生成完的简历还可以二次编辑导出
欢迎大家使用交流,哈哈哈
]]>


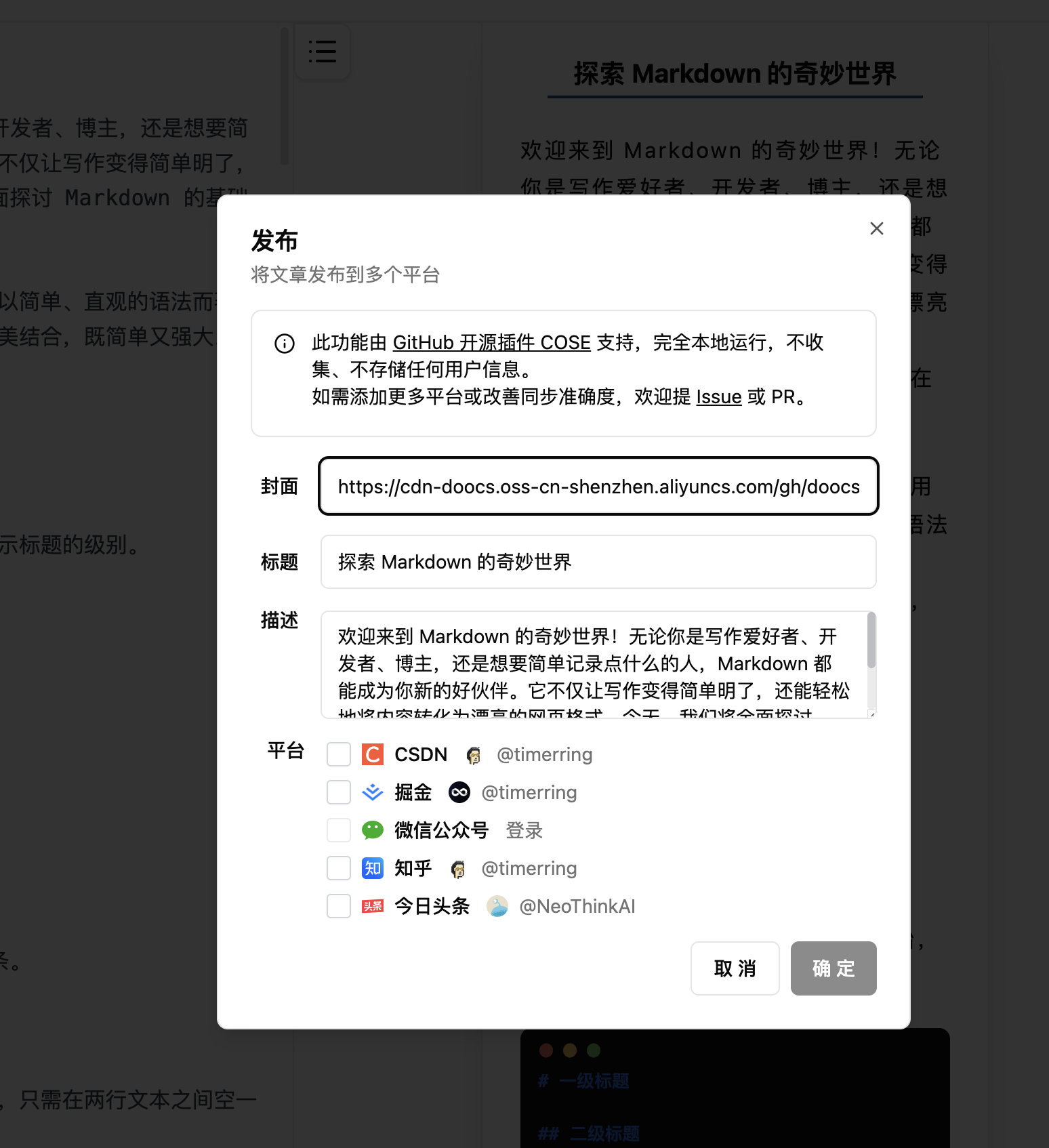

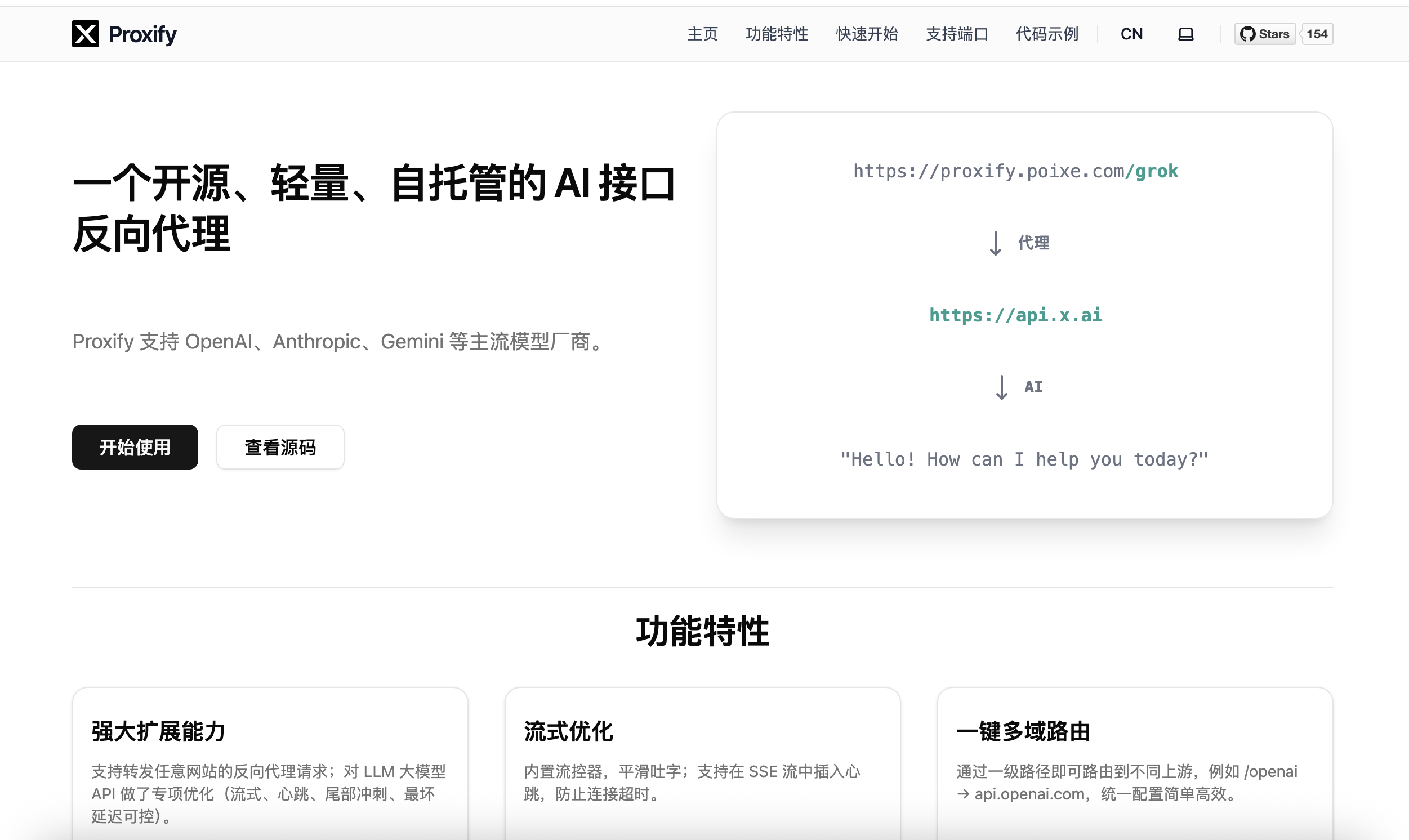
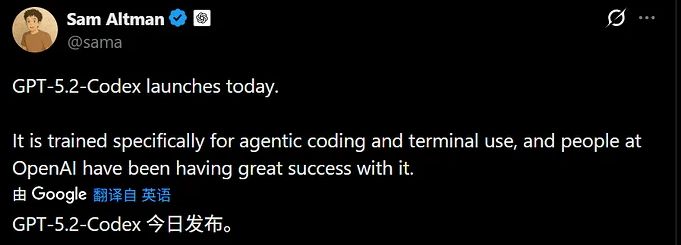 今天看到 GPT-5.2-Codex 更新了,就赶紧试用了一下,写了一个小网站玩玩,效果还不错,昨天用 gemini3 和 claude4.5 调试,总是差点意思,今天用这个,基本上都能得到满意的结果,不过这只是一个简单的示例,大家可以深入体验交流一下!
今天看到 GPT-5.2-Codex 更新了,就赶紧试用了一下,写了一个小网站玩玩,效果还不错,昨天用 gemini3 和 claude4.5 调试,总是差点意思,今天用这个,基本上都能得到满意的结果,不过这只是一个简单的示例,大家可以深入体验交流一下! 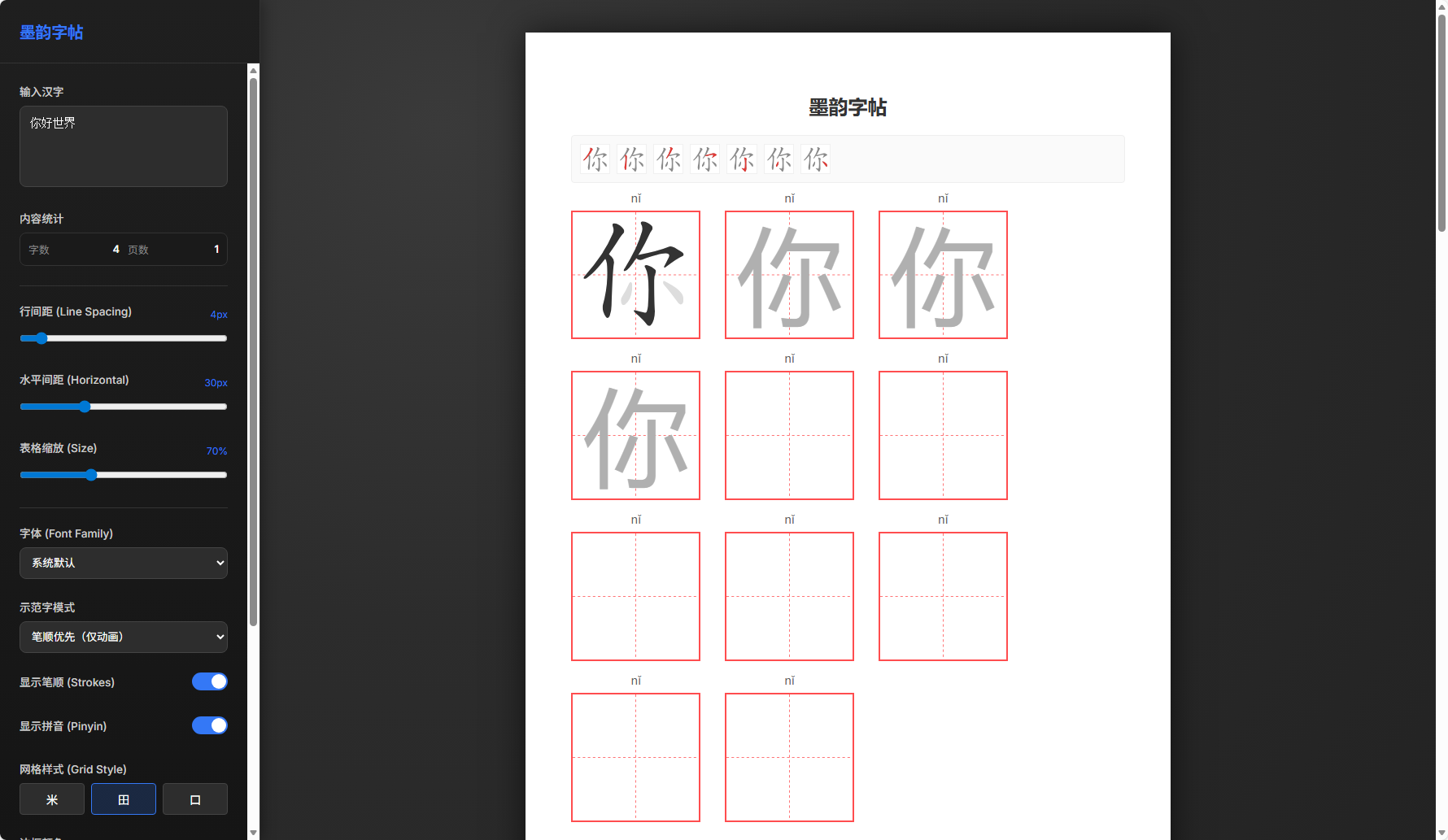







{kind=link}