
let mid = Math.floor(l + (r - l) / 2)
有时候如果不+1 就死循环了
let mid = Math.floor(l + (r - l) / 2 + 1)
求教,什么时候需要+1 ,什么时候不需要加 1 ]]>
我也看过之前的刷题的帖子,t/910785 ,我也是觉得这种如果没有额外的项目去做,练练手保持一下感觉也是不错的。 另外说一下,访问 leetcode.com 隔一段时间刷新就会跳到 leetcode.cn ,很烦。
]]> ]]>
]]>每次打开 leetcode ,面对近两千道题目,顿时感觉意义全无。我们为什么需要刷算法呢,而且为什么要去刷那些 difficult 难度的题?
]]>
我的代码:
public class Solution { public ListNode detectCycle(ListNode head) { if(head == null || head.next == null) return null; ListNode fast = head; ListNode slow = head; while(fast != slow){ if(fast == null || fast.next == null){ return null; } slow = slow.next; fast = fast.next.next; } fast = head; while( fast != slow){ fast = fast.next; slow = slow.next; } return fast; } } 无法通过的 case:
输入 [3,2,0,-4] 1 输出 tail connects to node index 0 预期结果 tail connects to node index 1 可以通过的代码:
public class Solution { public ListNode detectCycle(ListNode head) { if(head == null || head.next == null) return null; ListNode fast = head; ListNode slow = head; while(true){ if(fast == null || fast.next == null){ return null; } slow = slow.next; fast = fast.next.next; if(fast == slow) break; } fast = head; while( fast != slow){ fast = fast.next; slow = slow.next; } return fast; } } 有没有什么方案可以有代码提示+补全+调试方便的
]]>这道题目为什么贪心算法是最优解?怎么证明。
]]>
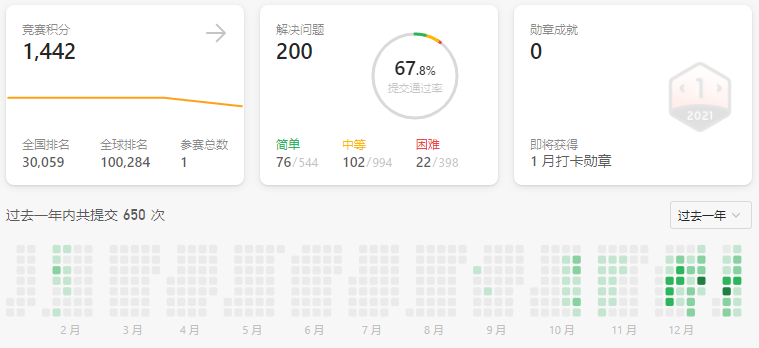

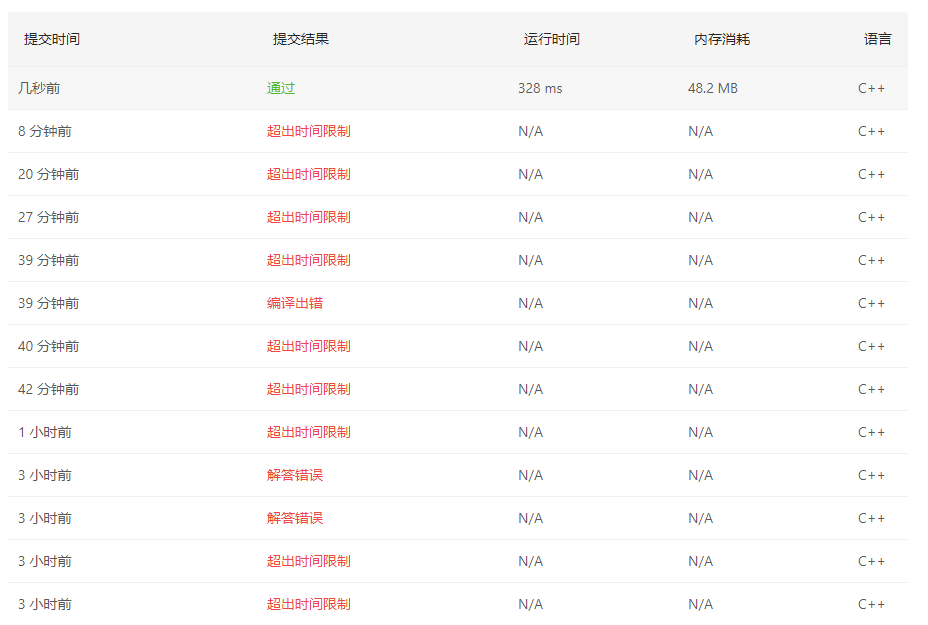
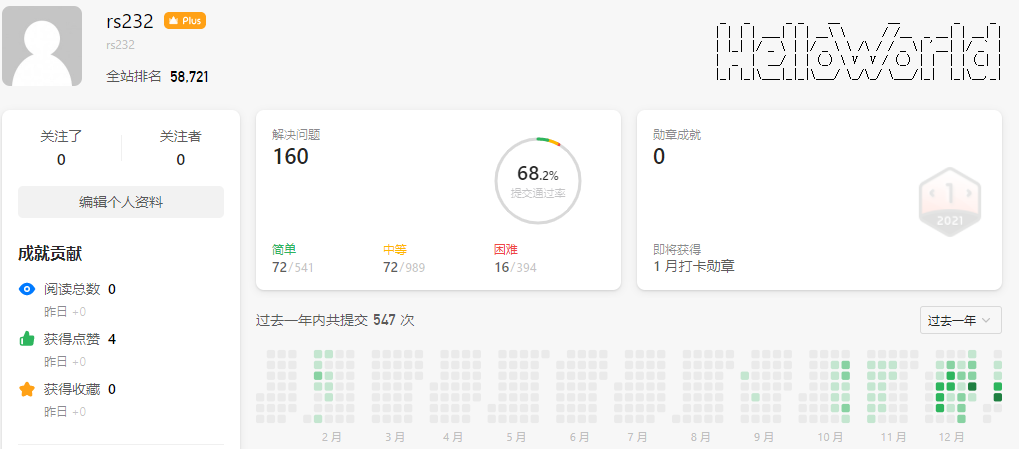 ]]>
]]>