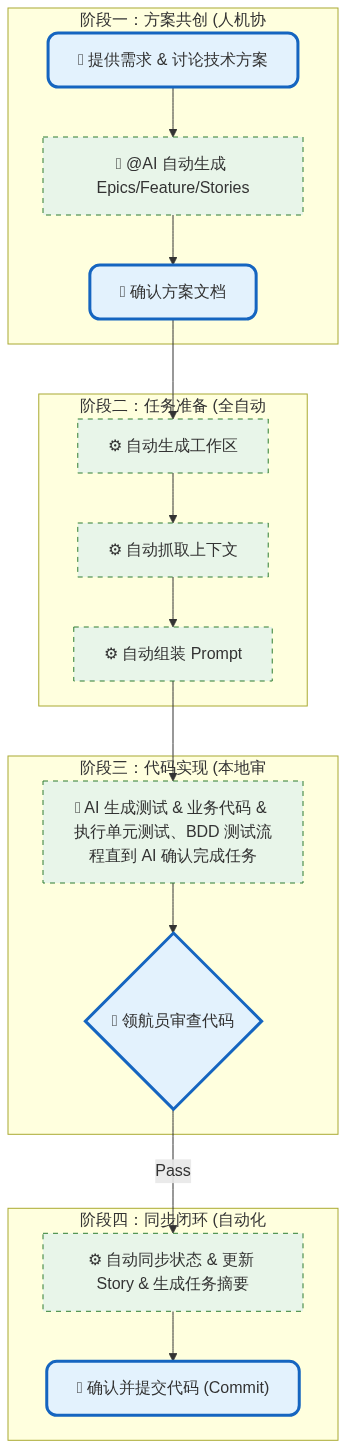
目前可以支持将本地的文件夹、镜像、以及 物理 USB 设备 通过网络共享给多个设备使用。在一些运维、签名场景下还不错。


但回到 Go 时,虽然 go mod 很好,但项目初始化、结构规范、构建优化这些事,总是要手动操作。
所以,我把 Cargo 的部分理念带到 Go 生态中,倒反天罡,做了 gocar:简化 Go 项目“创建-构建”流程的命令行工具。它不替代 go 命令,而是作为补充,提供更一致、更便捷的起点。
# 1. 创建一个简化布局的项目 gocar new my-server # gocar new my-server --mode project 将创建遵循标准布局的项目 # 2. 进入目录 cd my-server # 3. 构建(发布模式,优化体积,激进的设置了 CGO=0 ) gocar build --release # 4. 运行 gocar run 或者 ./bin/my-server # 输出示例: Hello, gocar! A golang package manager. 2025-12-15 13:51:49 比如我让 AI 写段代码实现一个需求,这时,我需要让另外一个 AI 去点评一下。比如这方案是否最好。
]]>今天,我们想向你推荐一款名为ACP ( AI-Config-Plaza ) 的开源项目。它就像一个“AI 配置管家”,通过统一管理、社区共享和一键同步,让 AI 工具配置这件事变得简单高效。
ACP 是一个专注于 AI 编程工具配置管理的开源平台,核心目标是解决开发者在使用各类 AI 工具(如 Claude Code 、GitHub Copilot 、Cursor 、OpenAI Codex 等)时的配置痛点。它通过“统一管理+社区共享”的模式,让你告别重复配置,轻松复用优质资源,降低工具切换成本。
项目采用全栈架构,包含前端交互平台、命令行工具( CLI )和后端服务,支持多语言(中英文),并完全开源,欢迎开发者参与共建。
无论是 AI Agent 的角色定义(如Agents.md)、自定义提示词( Prompt )模板,还是 MCP ( Model Context Protocol )服务配置,ACP 都能统一管理。每种配置都可设置名称、描述、标签和权限(公开/私有),还能跟踪点赞数和下载量,让你的配置资源更有序。
ACP 允许你将多个相关配置(比如“一个 Agent 配置+三个 Prompt 模板+一套 MCP 服务”)打包成“解决方案( Solution )”,并与特定 AI 工具绑定。例如,你可以创建一个“Python Web 开发解决方案”,包含适配 Cursor 的全套配置,其他开发者一键即可复用,无需从零开始。
ACP 提供了简洁的命令行工具,让配置在本地与平台间无缝同步:
acp apply即可拉取配置到本地项目;--ide vscode)和目标目录(如--dir ./my-project);acp locale切换中英文界面,适配不同使用习惯。举个例子,只需几步就能将“Python Web 开发解决方案”应用到本地:
# 登录(首次使用) acp login # 应用配置到指定项目,适配 Cursor acp apply --ide cursor --dir ~/projects/my-python-app CLI 会自动生成对应工具的目录结构,比如 Cursor 的配置会生成.cursor/commands/(存放 Prompt )、AGENTS.md( Agent 配置)和mcp.json( MCP 服务),无需手动调整路径。
ACP 内置社区协作机制:你可以将自己的优质配置设为公开,供其他开发者参考;也能通过搜索、筛选,快速找到社区中高赞的配置方案。点赞、收藏功能让优质资源一目了然,个人中心还能管理自己发布的配置和收藏,跟踪使用数据。
无论你用的是 Claude Code 、GitHub Copilot 还是 Cursor ,ACP 都能无缝适配。它定义了统一的配置导入/导出格式,当你从一个工具切换到另一个时,只需通过 CLI 重新应用对应方案,无需重新配置,真正实现“一次配置,多工具复用”。
访问: https://ai-config-plaza.com
通过 npm 全局安装 CLI ,快速同步配置:
# 使用 npm npm install -g @ai-config-plaza/acp-cli # 使用 pnpm pnpm add -g @ai-config-plaza/acp-cli # 使用 yarn yarn global add @ai-config-plaza/acp-cli 详细使用文档可查看CLI 文档。
ACP 是一个开源项目,我们欢迎所有开发者参与贡献:
CONTRIBUTING文档,前端采用 React+TypeScript+Tailwind CSS ,后端基于.NET ,技术栈友好。GLM-4.6:说是 Claude Sonnet 4.5 和 GPT-5 ,但价格仅需要 Sonnet 1/7
Qwen3-Code:SWE-bench Live 测试中得分 54.7 ,超越 GPT-4.1 ( 48.6 ),中文 API 文档理解准确率达 92%
DeepSeek-V3.2-Exp:说是被 GLM4.6 超过,但在 Vercel 、Windsurf 等编程平台接入
MiniMax M2:每 token 成本仅为 Claude Sonnet 的 8%、在 Terminal-Bench 测试中得分 37.5 ,专为 Agent 工作流设计
]]>可以留下 base64 编码后的邮箱参与抽奖,送电子书。也可以通过这个链接 3 折购买: https://leanpub.com/db_from_scratch_go_zh/c/888
]]>BloomFilter:布隆过滤器,一种基于多哈希函数和位数组的概率型数据结构,具有高效空间利用与快速查询特性;
// 1 、初始化 BloomFilter int size = 1000000; // 1 、容量 double fpp = 0.01; // 2 、误判率 BloomFilter<Long> bloomFilter = BloomFilter.create(Funnels.LONG, size, fpp); // 2 、添加元素 bloomFilter.put(999L); // 3 、判定元素是否存在 bloomFilter.mightContain(999L); 前缀数,一种哈希树的变种,利用公共前缀来节省存储空间和提高查询效率;
// 1 、初始化 前缀树 Trie trie = new Trie(); // 2 、插入单词 trie.insert("apple"); // 3 、查询完整单词 trie.search("app"); // 4 、前缀匹配检查 trie.startsWith("app"); /** * Excel 导出:Object 转换为 Excel */ ExcelTool.writeFile(filePath, shopDTOList); /** * Excel 导入:Excel 转换为 Object */ List<ShopDTO> shopDTOList = ExcelTool.readExcel(filePath, ShopDTO.class); /** * Excel 导出(流式方式):Object 转换为 Excel */ ExcelTool.writeExcel(filePath, new Supplier<>() { @Override public UserDTO get() { // 流式获取数据 ... return new UserDTO(); } }); /** * Excel 导入(流式方式):Excel 转换为 Object */ ExcelTool.readExcel(filePath, new Consumer<UserDTO>() { @Override public void accept(UserDTO userDTO) { logger.info("item: " + userDTO); } }); XXL-TOOL 是一个 Java 工具类库,致力于让 Java 开发更高效。包含 “日期、集合、字符串、IO 、缓存、并发、Excel 、Emoji 、Response 、Pipeline 、Http 、Json 、JsonRpc 、Encrypt 、Auth 、ID 、Serializer 、验证码、限流器、BloomFilter...” 等数十个模块。
| 模块 | 说明 |
|---|---|
| Core 模块 | 包含 集合、缓存、日期、反射、断言、……等基础工具。 |
| Cache 模块 | 一个高性能的 Java 缓存工具,支持多种缓存类型( FIFO 、LFU 、LRU 等)、锁分桶优化、缓存过期策略(写后过期、访问后过期...)、缓存定时清理、缓存加载器、缓存监听器、缓存信息统计...等功能。 |
| IO 模块 | 一系列处理 IO (输入/输出)操作的工具,包括 FileTool 、CsvTool 、IOTool...等。 |
| Concurrent 模块 | 一系列并发编程工具,具备良好的线程安全、高并发及高性能优势,包括 MessageQueue (高性能内存队列,30W+ TPS )、CyclicThread (后台循环线程)、TimeWheel (时间轮组件)、TokenBucket (令牌桶/限流器)等。 |
| Http 模块 | 一系列处理 Http 通讯、IP 、Cookie 等相关工具。 |
| Json 模块 | json 序列化、反序列化工具封装,基于 Gson 。 |
| JsonRpc 模块 | 一个轻量级、跨语言远程过程调用实现,基于 json 、http 实现(对比传统 RPC 框架:XXL-RPC)。 |
| Excel 模块 | 一个灵活的 Java 对象和 Excel 文档相互转换的工具。一行代码完成 Java 对象和 Excel 之间的转换。 |
| Emoji 模块 | 一个灵活可扩展的 Emoji 表情编解码库,可快速实现 Emoji 表情的编解码。 |
| Response 模块 | 统一响应数据结构体,标准化数据结构、状态码等,降低协作成本。 |
| Pipeline 模块 | 高扩展性流程编排引擎。 |
| Error 模块 | 异常处理相关工具,包括通用业务异常封装、异常工具类等; |
| Freemarker 模块 | 模板引擎工具,支持根据模板文件实现 动态文本生成、静态文件生成 等,支持邮件发送、网页静态化场景。 |
| Crypto 模块 | 一系列处理编解码、加解密的工具,包括 Md5Tool 、Sha256Tool 、HexTool 、Base64Tool...等。 |
| Auth 模块 | 一系列权限认证相关工具,包括 JwtTool...等。 |
| ID 模块 | 一系列 ID 生成工具,支持多种 ID 生成策略,包括 UUID 、Snowflake 、Date 、Random 等。 |
| Serializer 模块 | 一系列序列化、反序列化工具,支持扩展多种序列化格式,包括 jdk 、protobuf 、hessian 等。 |
| Captcha 模块 | 一个验证码工具,支持随机字符验证码、数字验证码、中文验证码等多形式。支持自定义验证码生成算法、宽高、颜色、文字字体/大小/间距、背景颜色、边框宽度/边框、干扰策略…等。 |
| DataStructure 模块 | 一系列数据结构工具,包括 BloomFilter 、Trie/前缀树...等; |
| ... | ... |
| 模块 | 工具 | 说明 |
|---|---|---|
| core | StringTool | 字符串工具,提供字符串校验及操作相关能力 |
| core | DateTool | 日期时间工具,提供日期时间转换及操作相关能力 |
| core | AssertTool | 断言工具,提供有效性校验能力 |
| core | CollectionTool | 集合工具,提供集合操作能力 |
| core | ArrayTool | 数组工具,提供集合操作能力 |
| core | MapTool | Map 工具,提供 Map 操作能力 |
| core | ObjectTool | Object 工具,提供 Object 操作能力 |
| core | PropTool | Prop 工具,提供 Properties 文件操作能力 |
| core | ReflectionTool | Java 反射工具,提供 Java 反射操作能力 |
| core | ClassTool | Class 类工具,提供 Class 类操作能力 |
| core | TypeTool | Type 工具,提供 Type 操作能力 |
| auth | JwtTool | JWT 工具,提供 JWT 生成及解析能力 |
| cache | CacheTool | 一个高性能的 Java 缓存工具,支持多种缓存类型( FIFO 、LFU 、LRU 等)、锁分桶优化、缓存过期策略(写后过期、访问后过期...)、缓存定时清理、缓存加载器、缓存监听器、缓存信息统计...等功能。 |
| concurrent | CyclicThread | 后台循环线程,支持精准、线程安全的周期性循环执行能力 |
| concurrent | MessageQueue | 高性能内存队列,单机支持 30W+ TPS |
| concurrent | TimeWheel | 时间轮组件,提供定时任务执行能力 |
| concurrent | TokenBucket | 令牌桶/限流器组件,提供令牌桶限流能力 |
| emoji | EmojiTool | Emoji 表情工具,提供 Emoji 表情编解码能力 |
| crypto | Base64Tool | Base64 工具,提供 Base64 编解码能力 |
| crypto | HexTool | Hex 工具,提供 Hex 编解码能力 |
| crypto | Md5Tool | MD5 工具,提供 MD5 编码能力 |
| crypto | SHA256Tool | SHA256 工具,提供 SHA256 编码能力 |
| excel | ExcelTool | 一个基于注解的 Excel 与 Java 对象 相互转换及导入导出工具;一行代码完成 Java 对象和 Excel 之间的转换。 |
| exception | BizException | 通用业务异常 |
| exception | ThrowableTool | 异常处理工具 |
| freemarker | FtlTool | 模板引擎工具, 支持根据模板文件实现 动态文本生成、静态文件生成 等,支持邮件发送、网页静态化场景。 |
| json | GsonTool | Json 序列化及反序列化工具,基于 Gson |
| http | CookieTool | Cookie 工具,提供 Cookie 读写操作能力 |
| http | HttpTool | 一个高性能 HTTP 请求库,API 简洁易用、使用高效方便且性能优越;支持 “常规 Http 请求、Java 对象请求、接口&注解编程” 三种使用方式。 |
| http | IPTool | IP 工具,提供 IP 地址及端口号相关校验、生成及操作相关能力 |
| io | IOTool | IO 工具,提供丰富 IO 读写操作能力 |
| io | FileTool | 一个高性能 File/文件 操作工具,支持丰富文件操作 API ;针对大文件读写设计分批操作、流式读写能力,降低内存占用、提升文件操作性能。 |
| io | CsvTool | Csv 工具,提供 Csv 文件读写操作能力 |
| jsonrpc | JsonRpcClient | 轻量级 RPC 通讯工具,客户端实现;基于 json 、http 实现 |
| jsonrpc | JsonRpcServer | 轻量级 RPC 通讯工具,服务端实现;基于 json 、http 实现 |
| pipeline | PipelineExecutor | Pipeline 执行工具,提供 pipeline 注册管理以及执行相关能力 |
| pipeline | Pipeline | Pipeline 工具,提供 pipeline 定义及执行相关能力 |
| response | Response | 标准响应结果封装,统一服务端数据返回格式 |
| response | ResponseCode | 标准响应码定义,统一服务端响应码体系 |
| response | PageModel | 标准分页结果封装,统一服务端分页数据格式 |
| id | DateIdTool | ID 生成工具,根据日期趋势递增生成 ID ; |
| id | RandomIdTool | ID 生成工具,随机数字、字母、混合字符生成工具; |
| id | SnowflakeIdTool | ID 生成工具,雪花算法 ID 生成工具; |
| id | UUIDTool | ID 生成工具,UUID 生成工具; |
| captcha | CaptchaTool | 验证码工具,提供验证码生成能力; |
| datastructure | BloomFilter | 布隆过滤器,一种基于多哈希函数和位数组的概率型数据结构,具有高效空间利用与快速查询特性; |
| datastructure | Trie | 前缀数,一种哈希树的变种,利用公共前缀来节省存储空间和提高查询效率; |
| ... | ... |
✅ 完全免费,下载即使用
✅ 每天 10 万次额度,个人用不完
✅ 真正的微信原生弹窗 + 声音提醒
✅ 支持多用户
✅ 提供免费服务https://push.hzz.cool(请勿滥用)
✅ 跳转稳定,自带消息详情页面 (默认使用https://push.hzz.cool/detail, 可自己部署后使用参数替换)
✅ 可无限换皮肤 (使用项目wxpushSkin)
获取 appid 、appsecret
关注测试公众号,获取 userid(微信号),新增测试模板(注意模版内容填写格式 内容: {{content.DATA}}) 获取 template_id(模板 ID)
将以上获取到的参数代入下面使用即可
./go-wxpush_windows_amd64.exe -port "5566" -title "测试标题" -content "测试内容" -appid "xxx" -secret "xxx" -userid "xxx-k08" -template_id "xxx-Ks_PwGm--GSzllU" -base_url "https://push.hzz.cool"与命令行参数名称一致 /wxsend?appid=xxx&secret=xxx&userid=xxx-k08&template_id=xxx-Ks_PwGm--GSzllU&base_url=https://push.hzz.cool&cOntent=保持微笑,代码无 bug !服务启动成功后会自带消息详情页界面(即消息模板跳转的页面),访问地址 http://127.0.0.1:5566/detail ,如有公网地址,可设置 base_url 参数为对应的 host 即可(无需加/detail)。
服务部署成功后,您可以通过构造 URL 发起 GET 请求来推送消息。
http://127.0.0.1:5566/wxsend | 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
port | String | 否 | 指定启动端口(仅针对命令行) |
title | String | 是 | 消息的标题。 |
content | String | 是 | 消息的具体内容。 |
appid | String | 否 | 临时覆盖默认的微信 AppID 。 |
secret | String | 否 | 临时覆盖默认的微信 AppSecret 。 |
userid | String | 否 | 临时覆盖默认的接收用户 OpenID 。 |
template_id | String | 否 | 临时覆盖默认的模板消息 ID 。 |
base_url | String | 否 | 临时覆盖默认的跳转 URL 。 |
基础推送
向默认配置的所有用户推送一条消息:
http://127.0.0.1:5566/wxsend?title=服务器通知&cOntent=服务已于北京时间%2022:00%20 重启 临时覆盖用户
向一个临时指定的用户推送消息:
http://127.0.0.1:5566/wxsend?title=私人提醒&cOntent=记得带钥匙&userid=temporary_openid_here 除了 GET 请求,服务也支持 POST 方法,更适合用于自动化的 Webhook 集成。
请求地址
http://127.0.0.1:5566/wxsend 请求方法
POST 请求头 (Headers)
{ "Content-Type": "application/json" } 请求体 (Body)
请求体需要是一个 JSON 对象,包含与 GET 请求相同的参数。
{ "title": "Webhook 通知", "content": "这是一个通过 POST 请求发送的 Webhook 消息。" } 使用示例 (cURL)
curl --location --request POST 'http://127.0.0.1:5566/wxsend' \ --data-raw '{ "title": "来自 cURL 的消息", "content": "自动化任务已完成。" }' 如果消息成功发送给至少一个用户,服务会返回 "errcode": 0 状态码。
如果发生错误(如 token 错误、缺少参数、微信接口调用失败等),服务会返回相应的状态码和错误信息。
]]>每天,我们都会在浏览器上工作,搜索信息、浏览网页内容、下订单、整理表格、填写表单、等等。
一方面,我们会打开几十个上百个浏览器标签,而切换和管理标签页已经是一件不可能的事情,很多时候需要推倒重来,只关注眼前的标签页。
另一方面,很多任务是重复性的,需要我们一遍又一遍地执行,比如填写表单、整理表格、填写验证码、等等。这个过程是伴随着无趣和低效的。
那么, 如果 AI 来做会怎么样呢? 我之前有做一款整理标签页的插件,智能整理庞杂的标签页为他们分组。 随着 Tool Call 和 MCP 的发展,意识到 AI Agent 可以做越来越多事情,很快这个插件成了现在的浏览器插件 AIPex 。 AIPex 支持使用自然语言来控制浏览器,并且在优化了上下文工程之后,可以做到快速和精准的完成任务。
通过这篇文章,我希望能解答这些问题:
从 ChatGPT 问世之后,就有过很多团队做了 AI 浏览器的尝试,最早就看到了 ChatGPT for Google , 能够在谷歌搜索结果旁展示 AI 的回答,这瞬间吸引了几百万的用户注册。而后随着 Sider 和 Monica 的发布,不仅能够增强谷歌的搜索结果, 也能在页面随时唤起 AI 助手,并且针对视频网站、chat pdf 、图片网站做了专门的优化,AI 能随时加入到内容的生成、修订和分析中,大大地加强了用户体验, 至今我也是此类插件的忠实用户。以 Sider 来说,光 chrome 就有 600w 的用户,可以说是 AI 浏览器插件第一名了吧。
之后,随着 Tool Use 和 MCP 的出现和广泛使用,AI 浏览器不仅是能够查询、在对话框内生成文字和图像,也能通过工具调用浏览器的能力,完成更复杂的任务。 从去年Browser Use提出这个概念,到今年Claude for Chrome、Comet、ChatGPT Atlas的出现,各家都发布了 Agentic Browser ,最大的特点就是能够自动地帮你完成任务。 从 Query 到 Action ,用户操作能被动浏览转向主动自动化。
? 你说的趋势没错。 但我仍然不觉得 AI 浏览器是必然。
1 传统浏览器的根本瓶颈:它只“展示”,不“完成”
传统浏览器的角色是:打开网页、展示信息、等人点击、复制、判断、跳转。但真正的目标从来不是“看网页”,而是:找到合适的产品 、完成报税 / 订票 / 填表、对比方案并做出决策、把信息转化为结果
人在浏览器里做的,其实是流程执行者,而不是“阅读者”。AI 浏览器的核心升级是:
? 从「页面渲染工具」 → 「任务完成工具」
2 现代网络的内容爆炸
现实问题是:页面越来越复杂(多步骤、弹窗、验证码、选项)、信息密度越来越高(比价、条款、评论、政策)、任务越来越流程化(申请、注册、比对、提交)。 而人类:点击慢、记忆有限、易出错、不擅长重复流程。
👉 不是人不聪明,而是人类不适合当“网页流程引擎”
自主执行任务的 AI 浏览器,本质是:不疲劳、不遗漏步骤、能并行执行、能持续优化路径。
3 信息时代的关键瓶颈已从“获取信息”转向“执行决策”
过去的问题是:
现在的问题是:
举例:
选一个最划算的航班 + 行李规则 + 改签条款
给 20 家供应商发定制邮件并跟进
按公司政策完成一次报销 / 采购流程
这些都不是“搜一下就行”,而主要是理解目标、权衡约束、执行步骤。
传统模式是
人 → 指挥 → 软件 → 等反馈 → 人再操作 AI 浏览器模式:
人 → 设定目标与边界 AI → 自主规划 + 执行 + 汇报结果 4 为什么是浏览器?
电脑是作为人与信息的媒介而诞生, 而浏览器基本覆盖 90%的工作和生活系统,能够连接到 SaaS 、政务、金融、内容平台, 不用等待各家提供接口,而是可以直接在“人类界面”层完成任务,这是目前我认为 目前最现实、阻力最小、扩展性最大的 AI 自动化落地路径。
一句话总结为什么我们需要 AI 浏览器
我们需要能够自主执行任务的 AI 浏览器,是因为人类的价值不在点击网页,而在设定目标、判断结果和承担责任。
AI 浏览器实现的关键在于如何高效地理解页面,这里有如下路径
直接读取 document / HTML
把 DOM 节点序列化成文本
交给 LLM 理解 + 生成操作
HTML / DOM → serialize → LLM → action Playwright / Puppeteer 也是 DOM 的思路,他们在处理 DOM 上做了很多脏活累活,能够拿到一个比较干净的 DOM 树表示。 但这个方案有以下问题
❌ DOM ≠ 用户看到的界面
❌ div 套 div ,DOM 不是语义表达会导致语义缺失
❌ LLM token 爆炸
把网页当成“截图”,用 OCR + Vision Model 识别:按钮、文本、输入框,再让 AI 通过坐标点击
Screenshot → Vision Model → UI elements → click(x,y) 目前来说 OpenAI 也有个 computer-use-agent(cua)模型,能够根据截图和任务生成动作。 优点在于这种方式比较通用,不依赖于浏览器对于网页的表达,可以推广到任何浏览器、任何操作系统的自动化。 这个方案虽然通用,但是成本和延迟高,目前即使是 ChatGPT Atlas 也不会使用 cua 去做自动化。
原理(重点)
浏览器内部其实已经有一棵 “给读屏软件用的语义树”:
role:button / textbox / link
name:人类可读名称
state:disabled / checked / expanded
hierarchy:真实 UI 结构
DOM → Accessibility Tree → Semantic UI Graph → LLM 为什么它非常适合 AI ?
| 维度 | DOM | Accessibility Tree |
|---|---|---|
| 是否语义化 | ❌ | ✅ |
| 是否贴近用户感知 | ❌ | ✅ |
| 是否稳定 | ❌ | ✅ |
| token 密度 | 高 | 低 |
| 可操作性 | 间接 | 直接 |
目前来说,有以下实现浏览器自动化的的产品形态,我们逐一分析:
Agent 浏览器是指独立的 AI 浏览器应用,如Comet、ChatGPT Atlas等。这些产品重新构建了浏览器,将 AI 能力深度集成到浏览器内核中。
优势:
劣势:
典型代表: Comet、ChatGPT Atlas、Dia
插件/扩展式是指基于现有浏览器( Chrome 、Edge 等)开发的扩展程序,如 AIPex 。这种方式在现有浏览器基础上添加 AI 自动化能力。
优势:
劣势:
典型代表: AIPex、Claude for Chrome
| 特性 | Agent 浏览器 | 插件/扩展式 |
|---|---|---|
| 迁移成本 | 高(需迁移数据) | 零(保留所有数据) |
| 开发成本 | 极高(需构建浏览器) | 中(基于现有 API ) |
| 用户体验 | 需适应新界面 | 无需改变习惯 |
| 生态兼容 | 无法使用现有扩展 | 完全兼容 |
| 深度集成 | 高 | 中 |
| 市场接受度 | 低(需改变习惯) | 高(即插即用) |
从实际落地角度来看,插件/扩展式是目前最现实、阻力最小、用户接受度最高的路径。用户不需要放弃已经建立的工作流和习惯,就能获得 AI 自动化能力。这也是 AIPex 选择扩展式路径的核心原因。
与Comet、ChatGPT Atlas等需要安装全新浏览器的方案不同,AIPex 是 Chrome/Edge 扩展,
"Your browser already works!" —— 你的浏览器已经很好用了,我们只是让它更智能。
对于一个能够阅读、执行任务的 AI Agent 来说,隐私和安全是至关重要的。 AIPex 采用MIT 开源协议,完全透明、可审计、可扩展:
与ChatGPT Atlas、Dia等需要付费订阅且数据需要上传到服务器的方案相比,AIPex 在隐私和安全方面都有明显优势。
AIPex 在上下文工程方面做了大量优化,这是其能够高效、准确完成任务的核心技术优势:
无障碍树 + 搜索召回机制:
智能快照去重:
Search-based Element Retrieval:
在处理网页内容时,AIPex 并没有使用基于 embedding 的 RAG 技术,相比于代码,网页是随时变化的,静态的 embedding 很难适应分析网页这个场景。 与 Claude Code 以及 Cline 的方案一致,AIPex 并不会去 embedding 存储你的网页,而是使用了优化后的 search ,让大模型去判断需要哪些元素, 既不是把全部页面内容给大模型,也不是基于 embedding 的 RAG 技术。
这些技术创新使得 AIPex 能够在保持高准确性的同时,大幅降低计算成本和响应时间。
AIPex 与**Claude Agent Skills**无缝集成,为浏览器自动化开辟了无限可能:
这意味着你不仅可以使用 AIPex ,还可以利用整个 Claude Agent Skills 生态系统,这使得你的任务可复用、可分享、并且更加快捷高效。
AIPex 会在任务需要确认时,智能地提示用户进行确认,这保证了如支付、确认提交等关键和敏感操作的安全性。
AIPex 能够理解网页和用户动作,所以对一些细化场景做了针对性的优化,比如撰写用户指引文档(《如何在 vercel 上创建域名?》)。
以前,如果你想要为自己的系统撰写用户文档,你需要
回到用户视角,保证文档不出现技术术语
手动录制每一步,并为每一步撰写描述文档
手动截屏每一步,并打上关键标注
将每一步的文档进行整理和排版,并最终形成文档
但是现在,你只需要打开 AIPex 用户指引功能,然后录制你的操作,AIPex 就会自动为你生成用户指引文档。
这个效率提升是革命性的,作为人你不需要再关注排版、用户视角、技术术语,这些 AIPex 都为你准备好了, 而你只需要关心最终的产物,并且可以随时更新。 还有很多类似于"撰写用户指引"这种细分场景,比如端到端测试、录制产品 demo ,AIPex 可以为这些细分场景提供更好的解决方案,敬请期待。
起初我只是想做一个浏览器内的 raycast ,能够在任何位置唤起,帮助我 切换标签(类似 Arc 浏览器的 Command + T 快捷键, 选择标签切换)、整理标签页面(我经常需要处理 40+个标签页,手动整理非常麻烦)、任何位置唤起 AI 助手(不管是发邮件、发推特,还是进行询问),于是我开发了 AIPex 的第一个版本。 这个版本能优化我遇到的多标签的问题,可以在一些页面对 AI 提问,但我觉得还不够酷。
去年此时 Anthropic 提出了 Computer Use Operator 的概念, 紧接着Browser Use也出现了提出了 AI 浏览器自动化的概念。 随着技术发展,主要是 tool use 和 mcp 的发展,出现了一些 chrome 的 mcp ,比如说mcp-chrome、playwright-mcp、browserMCP以及devtools-mcp项目。 我在 cursor 里进行了尝试,最大的问题是他们都是用的无头浏览器,这样就无法复用用户的登录状态,甚至无法再无介入的情况下帮我发一篇小红书。 其实这种 mcp client 、servers 分离也有上下文浪费的问题,cursor 无法针对性的进行上下文优化。
所以我就想做一个 chrome 扩展,能够直接在浏览器中使用,并且能够复用用户的登录状态,自然语言控制浏览器行为,并且针对浏览器做针对性的上下文优化。 在这之前我其实还搞不懂什么是 MCP ,什么是 tool use ,什么是 Agent Loop 。在于 cursor 老师搏斗一周之后,有了 AIPex 的第一个版本,涵盖了 80+个浏览器工具, 当时开源了 AIpex 代码并录制了第一个 demo 视频《帮我使用谷歌研究 MCP 》,AIPex 会打开谷歌、填入 MCP 、点击查询、进一步点入子链接进行研究,并最终生成一篇关于 MCP 的报告。
我将这个 demo 分享给了我的领导、同事和朋友们,他们都非常感兴趣,想搞清楚这里面做了什么。一开始我只是以业余时间做的玩具对待 AIPex ,Glace是第一个进行贡献的朋友, 对于 AIPex 他有无限的热情和想法,他希望借助 AIPex 的能力解决工作中遇到的实际问题,比如撰写用户文档、界面端到端测试等等。 我会和他沟通产品形态和需求,相同的是我和他虽然都是 typescript 纯小白,但都无比相信 cursor 老师的代码水平。 Glace 的高能量也进一步影响了我,让我知道 AIPex 是有趣的、有价值的,推动我去进而进一步优化 AIPex 。
随着越来越多同事和朋友了解到 AIPex ,也收到了更多的需求和修改建议,比较严重的是第一版本的 UI 是比较丑陋的,几乎是混用原生组件和第三方组件, 导致 UI 风格不好看、不统一,并且存在一些 bug 。Ken在国庆时完全用 ai elements 重构了 AIPex 的 UI ,这部分代码量更改已经占了当时的 1/2 , 最终效果非常惊艳才有了现在的 AIPex UI 。后来Claude Agent Skills一出现,Ken 也在一周内的时间就 1:1 复刻了 Skill 并整合到 AIPex 中, Skill 能够使用 prompt + 脚本 记录本次成功的执行过程,下一次再使用时,AIPex 就能根据 Skill 表现的更加一致、更加快速。
目前,k8s/golang/supabase/tidb contributor卡神也加入了我们,在研读了市面上如gemini-cli、openai-agents-sdk、spring-ai等主流 AI Agent 实现方式后,对我们的开源仓库进行重构,AIPex 的开源代码变得更加易懂、更加规范、更易于维护,卡神会继续协助我们做开源社区的运营。
我们依旧是一个 4 个人的小团队,我和 Glace 主要负责产品,Ken 是资深前端,对于 AIPex 这种富前端模型的 Agent 是至关重要的。 卡神是资深的开源贡献者,对于我们项目的开源路线和社区运营是非常重要的。 目前我们都是在业余时间为 AIPex 添砖加瓦, 产品方面目标是继续开发更契合的垂直场景,比如说录制产品 demo 、端到端测试、UI 比对等等,每一种垂直场景都是针对不同的人群解决问题。 营销方面我们没有太多的资金投入,我在尝试优化 SEO , SEO 我其实一年来一直在研究,有做过 AI 导航站有拿到过一定的成绩,但在 AIPex 上还没有太好的效果。 当前目标是能够拿到稳定可观的 MRR ,如果有合作意向,也可以在 https://www.claudechrome.com/zh/contact 联系到我们。
]]>目前可以支持将本地的文件夹、镜像、以及 物理 USB 设备 通过网络共享给多个设备使用。在一些运维、签名场景下还不错。
目前在跳板机上装的雷池来做 WAF 的,但是他的免费版只有最基础的数据展示,客户端、响应状态、外部来源域名/页面、受访域名/页面 这四个维度的数据需要升级到专业版( 3600 人民币/年)
所以就想问下大家有没有什么项目能补齐这四个维度的短板,我部署到内网主机上,我的内网 nginx 已经记录了完整的日志,现在只需要有个项目能读取到这些日志展示出来就大功告成了。
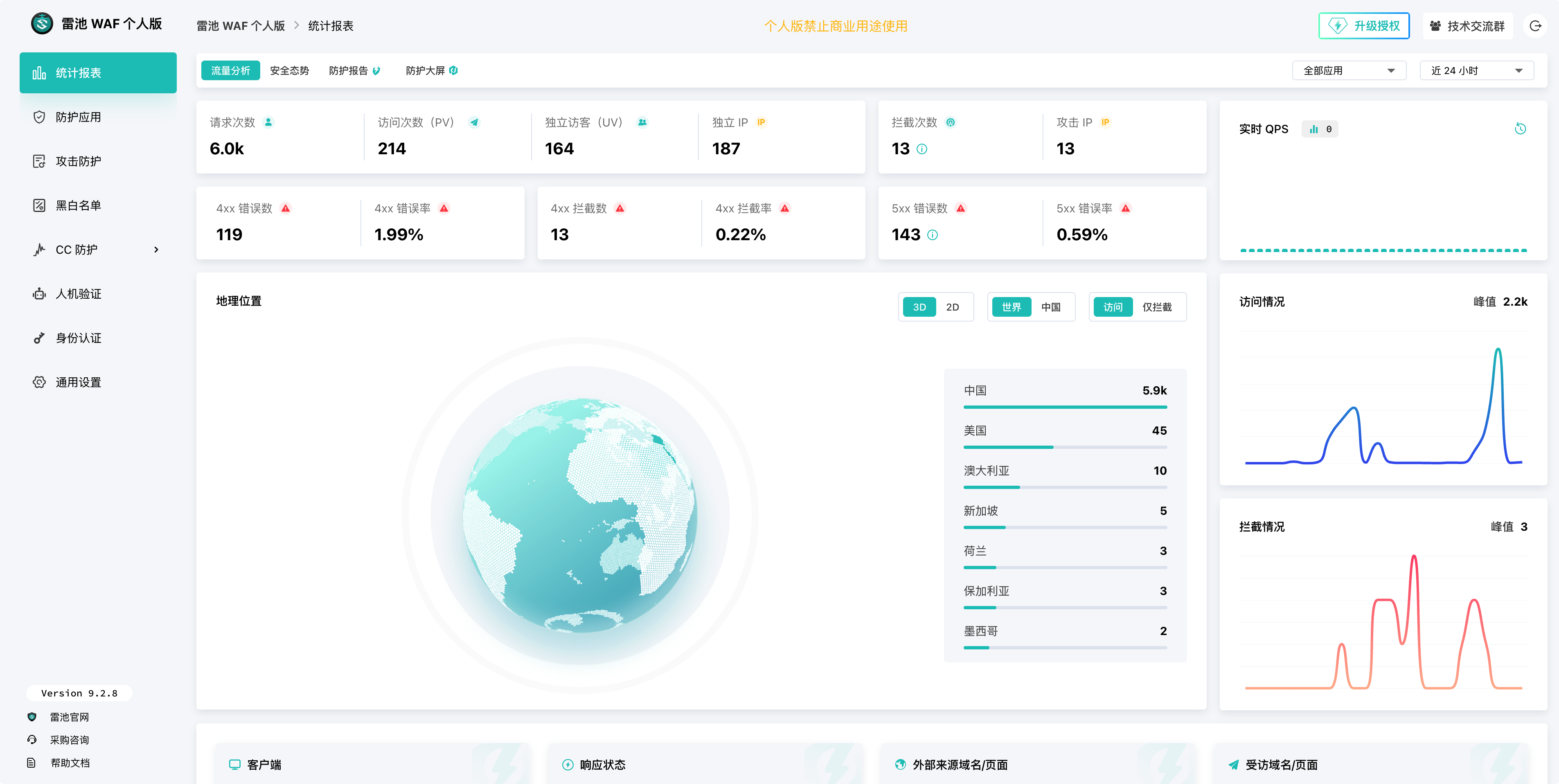
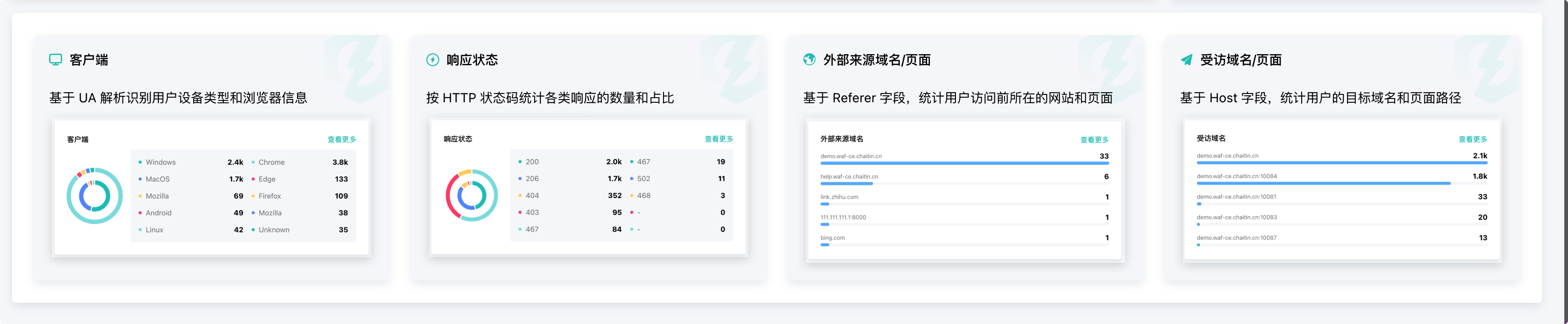
他的付费版,四个维度的看版是这样的: 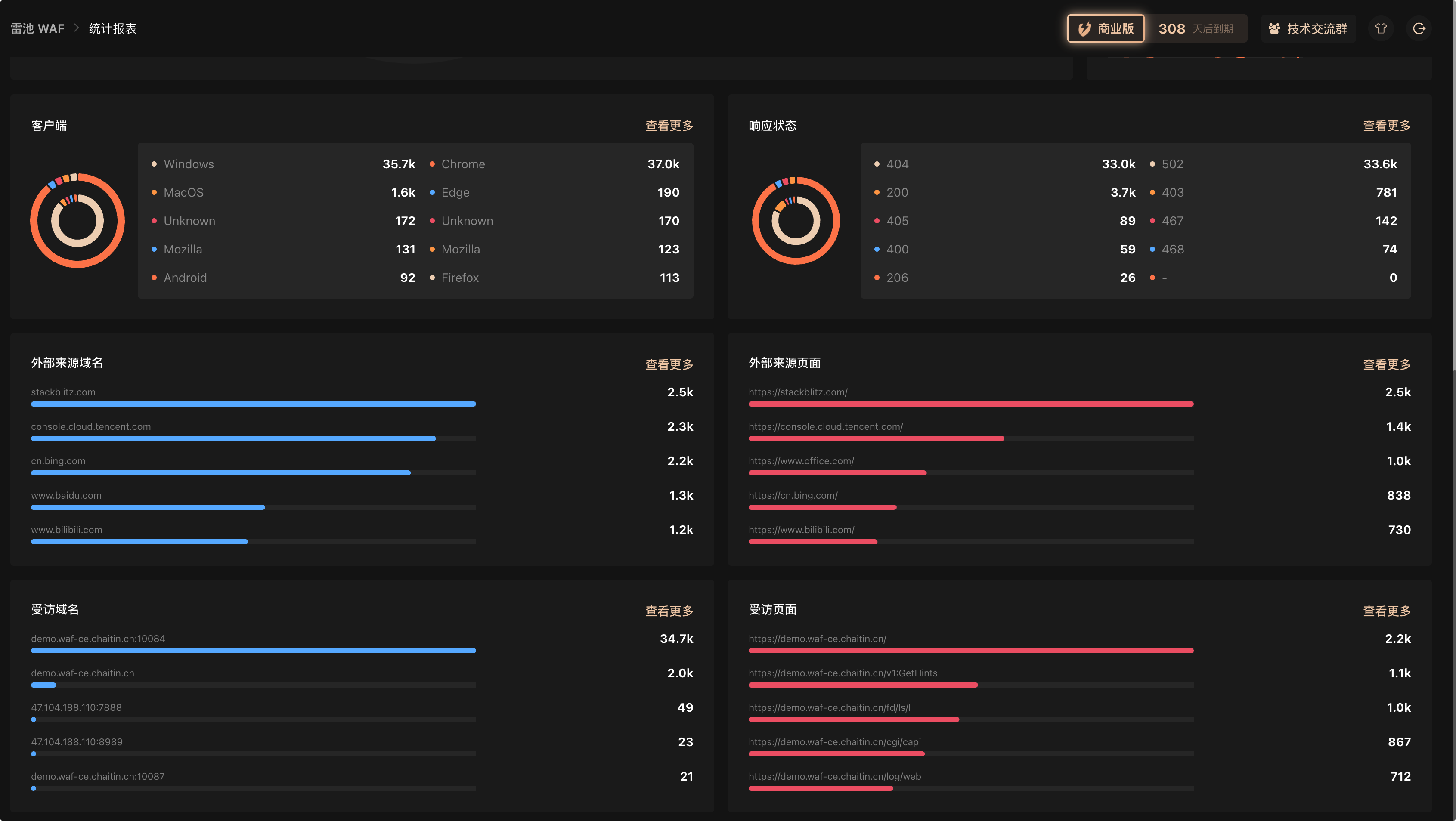
核心痛点:不是单个节点的检测,而是测所有节点然后标记出来方便在使用时区分避免选到垃圾节点。
注意:因为是模拟真实浏览器去检测的所以速度慢一点,因为简单爬取的方式容易被 CF 墙或接口限制
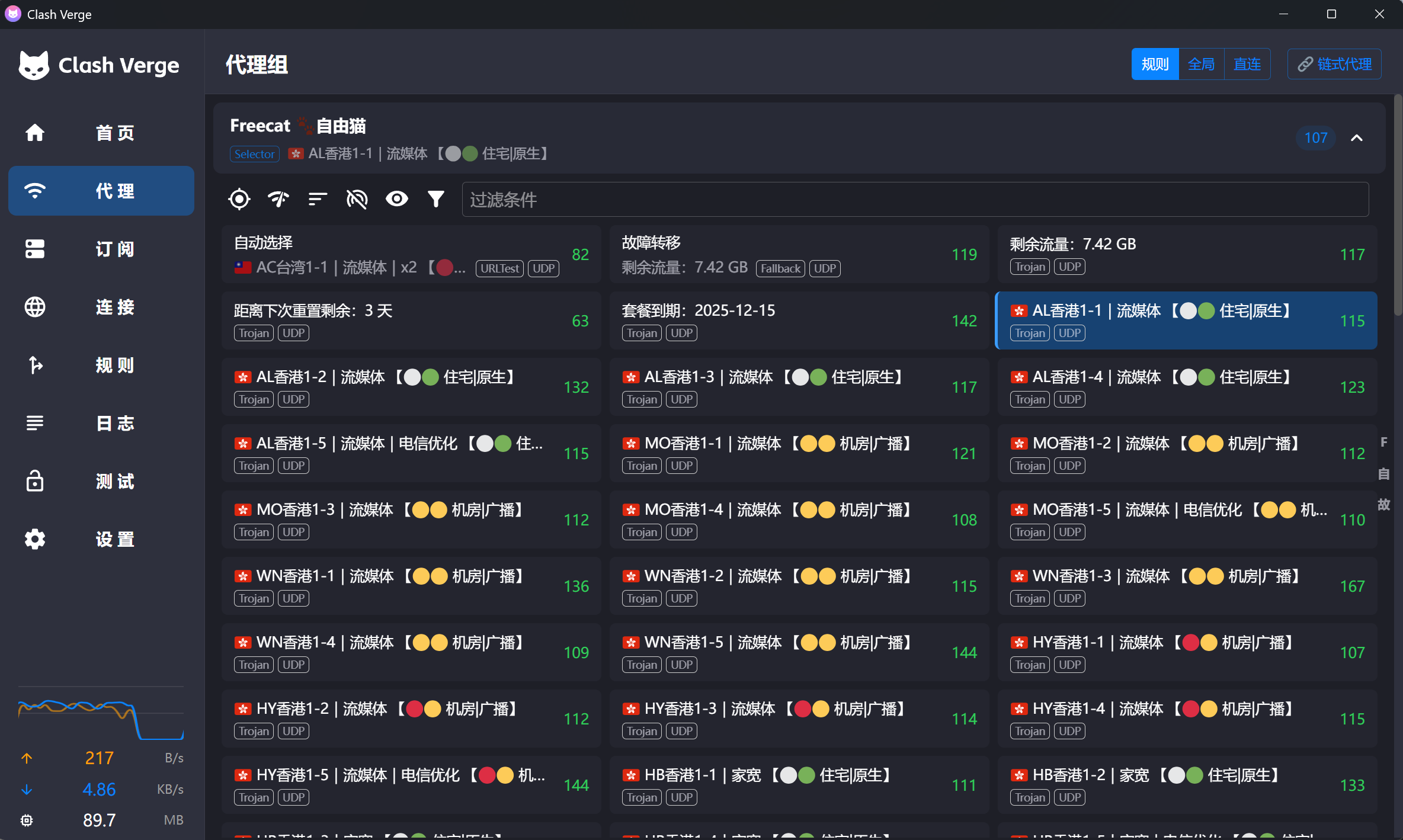
开源地址: https://github.com/tombcato/clash-ip-checker
主要功能: 通过 Clash 外部控制自动切换 Clash 节点,基于 Playwright 模拟调用 IPPure ,检测结果自动修改配置在节点名后加 Emoji 标记,最后输出 yaml 文件手动导入 Clash 即可
使用说明见 README: https://github.com/tombcato/clash-ip-checker/blob/main/README.md
标记:[🟢🟡 属性|来源]
觉得好用的话求个 Star ![🌟] 有 bug 欢迎提 issue !
]]>我用 windows 机器能正常编译,用 m 芯片的 macos 在编译 c/c++代码的时候会直接报错。
libc++abi: Terminating due to typed operator new being invoked before its static initializer… likely happening in code with -ftyped-cxx-new-delete enabled and statically linking against libc++abi.try disabling TMO with -fno-typed-cxx-new-delete 。 我问了 ai ,说是 ndk 21 版本在 m 芯片有兼容性问题,按照给的解决方案在 cmakelists 里加上对应的编译参数,没效果。 如果直接升级 ndk 版本,会报一堆其他新的错误。
我对 ndk 方面不太了解。有大佬遇到过这个问题吗?
]]>这阵子经历过 AI 编码个各种折磨后,一直在琢磨怎么让 AI 更好好写代码。现阶段的 AI 编码有几个让人很不爽的点:
- 直接 Chat:聊着聊着 AI 就“失忆”了,或者上下文太多导致逻辑漂移,项目越往后,上下文就越多,AI 很容易失控。
- 重型 Spec 工具:也用过 Spec 类型的,有些也很强,但要让我手写一堆 Markdown 文档来约束 AI ,说实话,太累、太麻烦了,坚持不下来。
所以我自己搞了个开源工具:TheConn。
核心思路是:不把 AI 当聊天对象,也不把它当法官,把它当船员。 TheConn 就是《星际迷航》里的“舰桥指挥台”。我们负责当 Navigator (领航员) 定目标、下指令,AI 工具负责把我的意图“翻译”成 AI 编码器能精准执行的 Context 。
为什么要造这个轮子?几个核心逻辑:
1. 大部分情况下需要“锁死”上下文,让 AI 不跑飞
平常用 AI 开发的多的同学应该有体会:对话轮次多了,AI 就会开始胡编; 随便给 AI 个简单任务,他能给你生成两个代码文件,6 、7 个 Markdown 文档(???黑人问号???)。
TheConn 引入了 “上下文护栏 (Context Guardrails)” 机制。它不是一股脑把所有历史丢给 AI ,而是根据你当前的 Task ,动态裁剪和组装最小且最精确的上下文。物理上杜绝了 AI 因为信息过载而产生的幻觉。
2. 不用手写 Spec ,流程自动生成
很多工具为了稳,强迫使用者先写一堆文档(这个真的很不适合我这种怕麻烦又懒的人)。
TheConn 走的是“无感生成”路子。 只需要跟着 Chat 的自然交互流程(@TheConn 自带的预定义 Prompt )走,工具会调用对应的专用模板自动生成类似 Spec/Plan 的结构化数据。 交互上是在对 AI 下命令,实际上工具会帮我把文档和规范都写好了。 既有了文档驱动的严谨,又没有写文档的痛苦。
3. 把 DDD 、BDD 、TDD 、敏捷开发“偷偷”塞进去
这一块是我设计的核心。这么做的原因很简单:如果让人类主动去执行这些繁琐的方法论,很难落地(尤其团队不大的情况下);但如果把它做成工具的默认路径,我们就能就在不知不觉中完成了高质量的工程开发。
- 敏捷:Chat 自然交互,让 AI 根据工具 Prompt 自动产生 Epics 、Features 、Stories 规划;要开始进入开发的时候,也是 Chat 自然交互,让 AI 生成对应 Story 的 AI Task 和上下文清单,之后直接把这个 Task 给 AI 就行了。
- DDD: 这个其实不包含在这个项目里,但是是一个比较重要的需求整理分析的手段(配合会议录音可以有比较好的效果)。
- BDD:通过 Chat 自然交互生成 Task 时,工具会自动规划 BDD 用例,并且会自动生成 BDD 依赖的 feature 文件。在生成业务代码前,Task 引导 AI 先生成 BDD 验证用例代码。
- TDD:在生成业务代码前,Task 引导 AI 先生成单元测试代码。
4. 本质是“协议层”的胜利
TheConn 最底层的价值,其实是建立了一套 “人类意图 <-> AI 指令” 的标准协议。 它充当了一个中间层( Middleware )。人类模糊的战略意图,经过这个协议层,被编译成 AI 只能严格执行的战术指令。这比单纯的 Prompt Engineering 要稳固得多,因为协议是确定性的。
代码全开源, 配合命令行工具可以快速集成到现有项目, 欢迎体验。 👉 GitHub 地址
(还在快速迭代中,欢迎提 Issue 咱们一起讨论 AI 编程的最佳实践!)
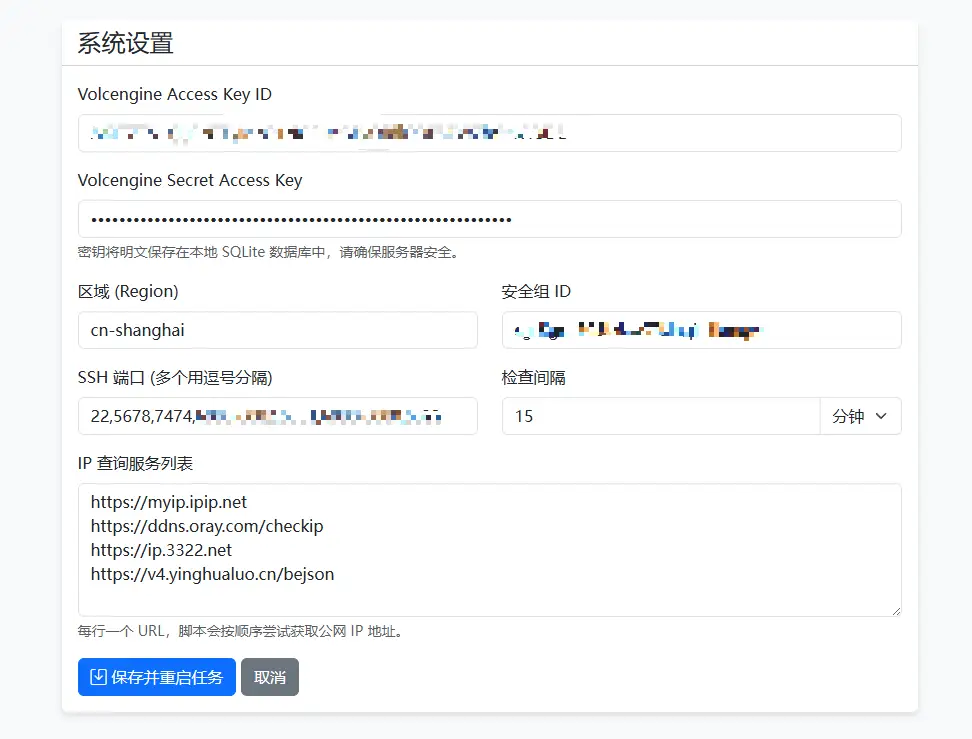
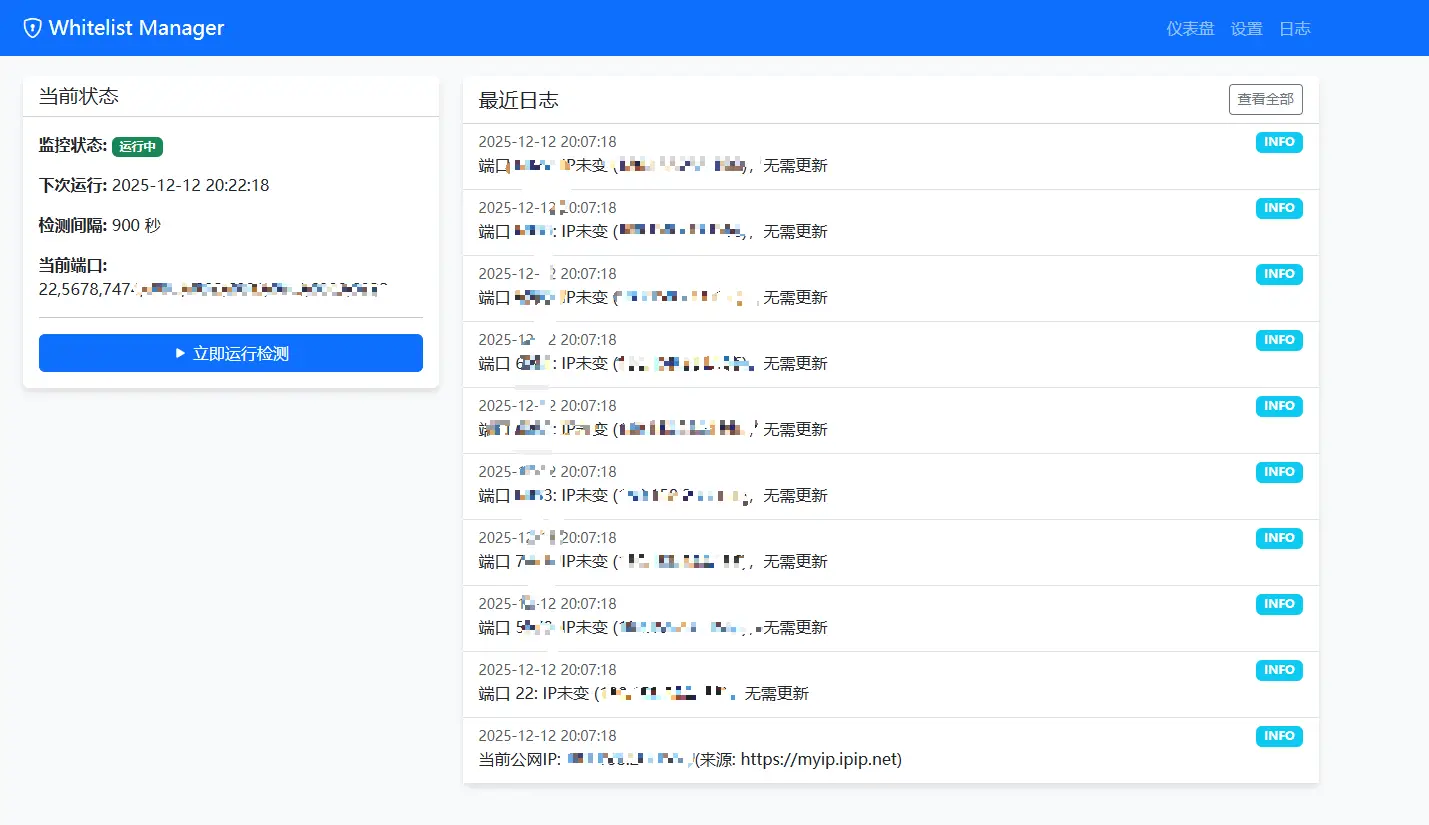
程序会获取当前的 ip ,更新火山引擎安全组中特定端口的白名单,保证只有当前网络环境可以访问。
我是结合 wireguard 用,在其他地方想访问的话,就使用 wireguard 。
目前只支持火山引擎,我也不确定我的需求别人需不需要,如果需要的话,我后面再加其他厂商的。
github: https://github.com/zhongjidalao/volcengine-whitelist-manager
来试试我们刚开源的小玩意儿吧,TADA ,一个全新的任务管理系统。
是的,我们又造了一个轮子。
在这个轮子中,我们在尝试解决这些问题:
😭 “我这个月到底干了啥,我该怎么把月报编出来?”
🤯 “一个月后我得规划一次团建,到底有哪些活?”
😫 “日报的头我开好了,谁来帮我把后面补充亿下?”
🤬 “我想在任务备注里面插个表格,我不想要 markdown 那种丨丨丨丨的表格”
没戳,这就是我们想解决的问题.
💬 说人话 建任务 - "下周三下午提醒我催张三交方案,标红,打上‘工作’和‘紧急’的标签"。
✨ 任务报告 一键生成 - 选时间范围,自动分析你完成了啥、进行中啥、遇到啥困难,Markdown 格式直接贴钉钉。
📝 任务备注 = 轻量级文档 - 编辑器支持表格、图片、代码块,项目复盘不用再开新文档。《对,这是我们的另一个轮子😂》
✍️ 代笔人: / → Enter, 行云流水,让 AI 帮我补充亿点。彻底解决“开头:史家之绝唱;结尾:史铁生;中间:史”。
Github 地址: https://github.com/LoadShine/tada
在线体验: https://loadshine.github.io/tada
我们还有桌面端哦,很小的哦,真的不试试吗铁铁,不要钱的。
]]> ]]>
]]> ]]>
]]>server address: 142.250.191.42
1 、Basic Ping Tests (Connectivity & Baseline Latency) Run these commands from the affected server/client in Silicon Valley. ping(base) [root@usa-gg-test01 ~]# ping aiplatform.googleapis.com PING aiplatform.googleapis.com (142.250.191.42) 56(84) bytes of data. 64 bytes from nuq04s42-in-f10.1e100.net (142.250.191.42): icmp_seq=1 ttl=118 time=2.67 ms 64 bytes from nuq04s42-in-f10.1e100.net (142.250.191.42): icmp_seq=2 ttl=118 time=2.62 ms 64 bytes from nuq04s42-in-f10.1e100.net (142.250.191.42): icmp_seq=3 ttl=118 time=2.64 ms
2 、python code test Using the model:gemini-3-pro-preview
import requests import json import time
def stream_gemini_content(): api_key='xxx' url = "https://aiplatform.googleapis.com/v1/publishers/google/models/gemini-3-pro-preview:streamGenerateContent?alt=sse"
headers = { "x-goog-api-key": api_key, "Content-Type": "application/json" } data = { "contents": [{ "role": "user", "parts": [{ "text": "请讲一个 200 字的故事,不要用推理,直接回答。" }] }], "generationConfig": { "thinkingConfig": { "includeThoughts": False } } } print(f"begin requests: {url} ...") start_time = time.time() first_token_time = None last_chunk_time = None try: with requests.post(url, headers=headers, json=data, stream=True) as response: if response.status_code != 200: print(f"status: {response.status_code}") print(response.text) return print("-" * 50) for line in response.iter_lines(): if not line: continue decoded_line = line.decode('utf-8').strip() if not decoded_line.startswith("data: "): continue json_str = decoded_line[6:] if json_str == "[DONE]": break try: now = time.time() if first_token_time is None: first_token_time = now print(f"\n[total] frist token TTFT: {(now - start_time) * 1000:.2f} ms") print("-" * 50) last_chunk_time = now chunk_data = json.loads(json_str) candidates = chunk_data.get("candidates", []) total_elapsed = (now - start_time) * 1000 chunk_gap = (now - last_chunk_time) * 1000 if last_chunk_time else 0 last_chunk_time = now if candidates: cOntent= candidates[0].get("content", {}) parts = content.get("parts", []) if parts: text_chunk = parts[0].get("text", "") print(text_chunk, end="", flush=True) except Exception as e: pass except Exception as e: pass end_time = time.time() print("\n\n" + "-" * 50) print(f"total time: {(end_time - start_time) * 1000:.2f} ms") if name == "main": stream_gemini_content()
代码测试非常慢,200 个字故事就超过 17s 了
]]>我就想知道这个问题有没有答案:两种不同的自然语言 prompt 对代码生成质量有无影响?
spec kit 自带 prompt 是英语,这就导致了中英混合,那么中英文混合 prompt 对代码质量有无影响?
]]>由于担心开新号冲会员会被封号,想用主力账号开通。
不知道有同行开过 gemini 会员吗?我担心主力 g 家账号开通 Gemini 会员,如果被封号,反而会连累我多年的 gmail 。
]]>马一龙牛批(破音
]]> ]]>
]]>尝试用 censys 找源站 IP 没找到,所以只能从 CF 的入口着手
直接 curl 会触发 CF 的 403,这里用 tls 指纹解决了
然后用 URL 混淆突破了缓存,但是只要请求的频率稍稍快一点,就会触发 429 error code: 1015
这里查了官方文档说是请求超过回源限制了,但是返回的 Retry-After 是 0
已经使用了代理,但是是同一个 C 段内的 64 个 IP ,机房 IP
目前尝试了几种情况 结果是这样
1.TLS 验证,代理轮询,间隔 5 秒,模拟 IOS => 可以正常访问
2.TLS 验证,代理轮询,间隔 5 秒,随机模拟 IOS/SAFARI/CHROME => 偶尔报 429-1015 错误
3.TLS 验证,不使用代理,间隔 5 秒 随机模拟 => 成功 8 次后 返回 2 次 429-1015 ,成功 13 次,失败 1 ,成功 3 ,后面几分钟成功率基本在 90%以上,20 分钟后成功率 50%左右
4.TLS 验证,代理轮询,间隔 500 毫秒,随机模拟 IOS/SAFARI/CHROME => 偶尔报 429-1015 错误,成功率 40%左右
如果用那种住宅 IP 代理服务的话延迟达不到要求,尝试过几个都是 500ms 左右才会返回结果
有大佬做过相关的东西吗,求思路,孩子没招了
]]> ) ]]>
) ]]>刚刚注册了火山引擎,AI 大模型服务好像是在火山方舟里,以前没搞过这块,目前处于懵逼中。。。
哪位老兄做过类似的?说说怎么做的呗
]]> ┌──────────────────────────┐ │ 硬件 / 电路 / 芯片 │ │ (FPGA / ASIC / 驱动开发) │ └──────────▲───────────────┘ │ ┌──────────┴──────────┐ │ 汇编 / 裸 C │ │(自己写启动代码那种) │ └──────────▲──────────┘ │ ┌──────────┴──────────┐ │ 系统级开发 │ │ C / C++ / Rust │ │(内核/DB/编译器/RTOS)│ └───────▲────▲───────┘ │ │ ┌──────────┘ └──────────┐ │ │ ┌───────────┴───────────┐ ┌─────────┴─────────┐ │ 高性能服务端 │ │ 安全 / 密码学 │ │ Rust / C++ / Go │ │ Rust / C │ └──────────▲────────────┘ └────────▲──────────┘ │ │ │ │ (互相看不顺眼) ┌──────────┴──────────┐ │ │ 正常业务后端开发 │ │ │ Go / Java / C# │◄────────────┘ │(微服务 / CRUD / RPC)│ └──────────▲──────────┘ │ ┌─────────────┴─────────────┐ │ 脚本 & 应用层 │ │ Python / Ruby / PHP / Node│ │(Web, 运维脚本, AI glue) │ └─────────────▲─────────────┘ │ ┌─────────────┴─────────────┐ │ 前端工程化 │ │ TypeScript / React / Vue │ │(构建工具 / 工程体系 / DX) │ └─────────────▲─────────────┘ │ ┌─────────────┴─────────────┐ │ 传统切图仔形象 │ │ HTML / CSS / jQuery │ │ (我真没写这么说的是后端) │ └─────────────▲─────────────┘ │ ┌─────────────┴─────────────┐ │ 低代码 / no-code │ │ “会点拖拽就能上线页面” │ └─────────────▲─────────────┘ │ ┌─────────────┴─────────────┐ │ 产品 / 运营 / PM │ │ “这个很简单吧,一天能做完” │ └─────────────▲─────────────┘ │ ┌─────────────┴─────────────┐ │ 甲方 / 老板 │ │ “这不过就是改几行” │ └────────────────────────────┘ 我看 cursor 和 codex 都有 web 端,不知道好用不,有没有 v 友可以分享一下。感谢感谢。
]]>Phone Agent 是一个基于 AutoGLM 构建的手机端智能助理框架,它能够以多模态方式理解手机屏幕内容,并通过自动化操作帮助用户完成任务。
]]>声明:个人案例,不代表所有人 我平时的邮件客户端:
主邮箱是 Gmail ,偏偏昨天服务器崩了,最要命的是当时正等着收 Gmail 的验证码,越着急越无力…
今天想了想,干脆以后换成 Outlook 客户端,虽然交互和 UI 不好,但至少不用代理就能正常收发邮件。甚至把所有账号都迁到 Outlook 算了。
至于转发,不会考虑,绕来绕去很累。
]]>