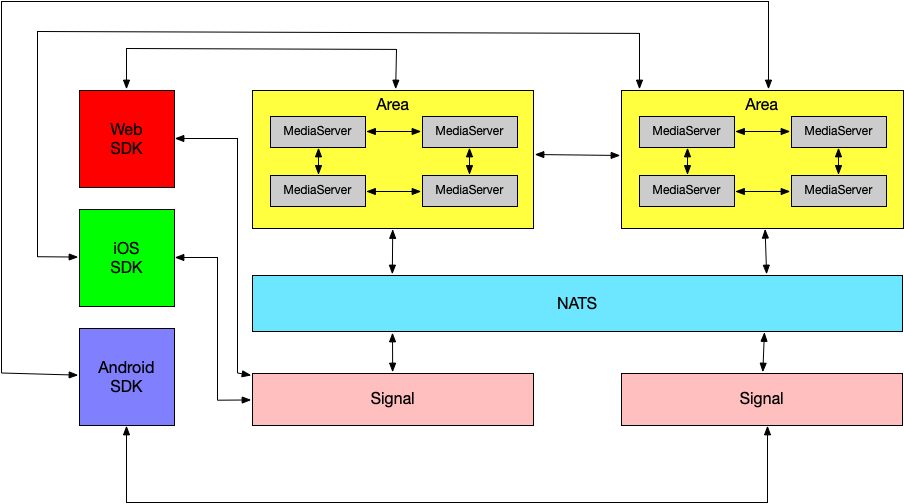
本文将教你如何通过声网视频 SDK 在 iOS 平台上实现一个视频通话应用。为此你需要先注册一个声网开发者账号,开发者每个月可获得 10000 分钟的免费使用额度,可实现各类实时音视频场景。
一、 通过开源 Demo ,体验视频通话
可能有些人,还不了解我们要实现的功能最后是怎样的。所以我们在 GitHub 上提供一个开源的基础视频通话示例项目,在开始开发之前你可以通过该示例项目体验视频通话的体验效果。
Agora 在 https://github.com/AgoraIO/Basic-Video-Call/tree/master/One-to-One-Video 上提供开源的实时音视频通话示例项目 Agora-iOS-Tutorial-Objective-C-1to1 与 Agora-iOS-Tutorial-Swift-1to1 。 
二、 视频通话的技术原理
我们在这里要实现的是一对一的视频通话。你可以理解为是两个用户通过加入同一个频道,实现的音视频的互通。而这个频道的数据,会通过声网的 Agora SD-RTN 实时网络来进行低延时传输的。 下图展示在 App 中集成 Agora 视频通话的基本工作流程: 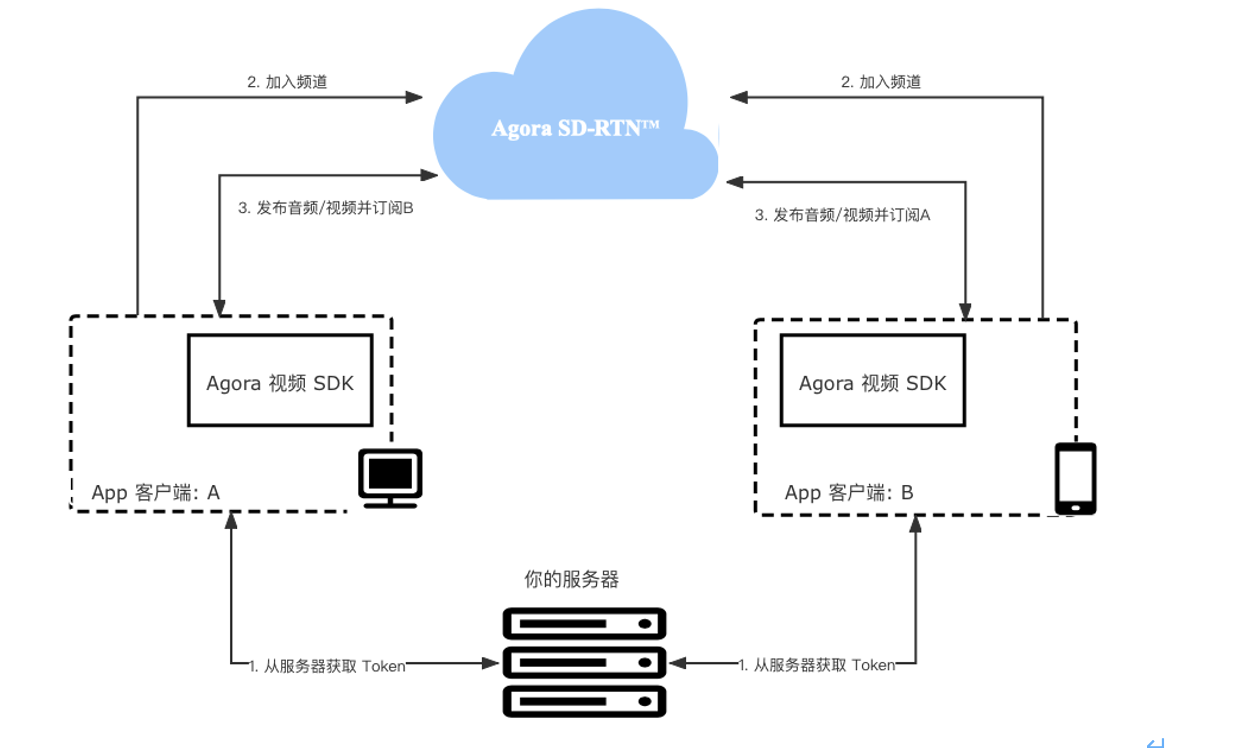
如图所示,实现视频通话的步骤如下:
- 获取 Token:当 app 客户端加入频道时,你需要使用 Token 验证用户身份。在测试或生产环境中,从 app 服务器中获取 Token 。
- 加入频道:调用 joinChannel 创建并加入频道。使用同一频道名称的 app 客户端默认加入同一频道。频道可理解为专用于传输实时音视频数据的通道。
- 在频道内发布和订阅音视频流:加入频道后,app 客户端均可以在频道内发布和订阅音视频。
App 客户端加入频道需要以下信息:
- App ID:Agora 随机生成的字符串,用于识别你的 App ,可从 Agora 控制台获取,( Agora 控制台链接: https://console.agora.io/)。详细方法可见这篇教程(这篇教程链接: https://www.agora.io/cn/community/blog-119-category-21344 )。
- 用户 ID:用户的唯一标识。你需要自行设置用户 ID ,并确保它在频道内是唯一的。
- Token:在测试或生产环境中,app 客户端从你的服务器中获取 Token 。在本文介绍的流程中,你可以从 Agora 控制台获取临时 Token 。临时 Token 的有效期为 24 小时。
- 频道名称:用于标识视频通话频道的字符串。
三、 开发环境
声网 Agora SDK 的兼容性良好,对硬件设备和软件系统的要求不高,开发环境和测试环境满足以下条件即可:
- Xcode 9.0 或以上版本
- 支持语音和视频功能的真机
- App 要求支持 iOS 8.0 或以上版本的 iOS 设备
以下是本文的开发环境和测试环境:
开发环境
• macOS 11.6 版本 • Xcode Version 13.1
测试环境
• iPhone7 (iOS 15.3)
如果你此前还未接触过声网 Agora SDK ,那么你还需要做以下准备工作:
• 注册一个声网账号,进入后台创建 AppID 、获取 Token , • 下载声网官方最新的视频通话 SDK ;(视频通话 SDK 链接: https://docs.agora.io/cn/Video/downloads?platform=iOS )
四、 项目设置
1. 实现视频通话之前,参考如下步骤设置你的项目:
a) 如需创建新项目, Xcode 里,打开 Xcode 并点击 Create a new Xcode project 。(创建 iOS 项目链接: https://developer.apple.com/documentation/xcode/creating-an-xcode-project-for-an-app ) b) 选择平台类型为 iOS 、项目类型为 Single View App ,并点击 Next 。 c) 输入项目名称( Product Name )、开发团队信息( Team )、组织名称( Organization Name )和语言( Language )等项目信息,并点击 Next 。 注意:如果你没有添加过开发团队信息,会看到 Add account… 按钮。点击该按钮并按照屏幕提示登入 Apple ID ,完成后即可选择你的 Apple 账户作为开发团队。 d) 选择项目存储路径,并点击 Create 。
2. 集成 SDK
选择如下任意一种方式获取最新版 Agora iOS SDK 。
方法一:使用 CocoaPods 获取 SDK a) 开始前确保你已安装 Cocoapods 。参考 Getting Started with CocoaPods 安装说明。( Getting Started with CocoaPods 安装说明链接: https://guides.cocoapods.org/using/getting-started.html#getting-started ) b) 在终端里进入项目根目录,并运行 pod init 命令。项目文件夹下会生成一个 Podfile 文本文件。 c) 打开 Podfile 文件,修改文件为如下内容。注意将 Your App 替换为你的 Target 名称。
方法二:从官网获取 SDK a) 前往 SDK 下载页面,获取最新版的 Agora iOS SDK ,然后解压。(视频通话 SDK 链接: https://docs.agora.io/cn/Video/downloads?platform=iOS ) b) 根据你的需求,将 libs 文件夹中的动态库复制到项目的 ./project_name 文件夹下( project_name 为你的项目名称)。 c) 打开 Xcode ,进入 TARGETS > Project Name > Build Phases > Link Binary with Libraries 菜单,点击 + 添加如下库(如:)。在添加 AgoraRtcEngineKit.framework 文件时,还需在点击 + 后点击 Add Other…,找到本地文件并打开。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RMM224bm-1663063848743)(upload://gOFc9CzhWzmOk7Ef4Dh0QVyu5kp.png)]
共需要添加 11 个库文件: i. AgoraRtcEngineKit.framework ii. Accelerate.framework iii. AudioToolbox.framework iv. AVFoundation.framework v. CoreMedia.framework vi. CoreML.framework vii. CoreTelephony.framework viii. libc++.tbd ix. libresolv.tbd x. SystemConfiguration.framework xi. VideoToolbox.framework 注意: 如需支持 iOS 9.0 或更低版本的设备,请在 Xcode 中将对 CoreML.framework 的依赖设为 Optional 。
d) 打开 Xcode ,进入 TARGETS > Project Name > General > Frameworks, Libraries, and Embedded Content 菜单。 e) 点击 + > Add Other… > Add Files 添加对应动态库,并确保添加的动态库 Embed 属性设置为 Embed & Sign 。添加完成后,项目会自动链接所需系统库。
注意:
- 根据 Apple 官方要求,app 的 Extension 中不允许包含动态库。如果项目中的 Extension 需要集成 SDK ,则添加动态库时需将文件状态改为 Do Not Embed 。
- Agora SDK 默认使用 libc++ (LLVM),如需使用 libstdc++ (GNU),请联系 sales@agora.io 。SDK 提供的库是 FAT Image ,包含 32/64 位模拟器、32/64 位真机版本。
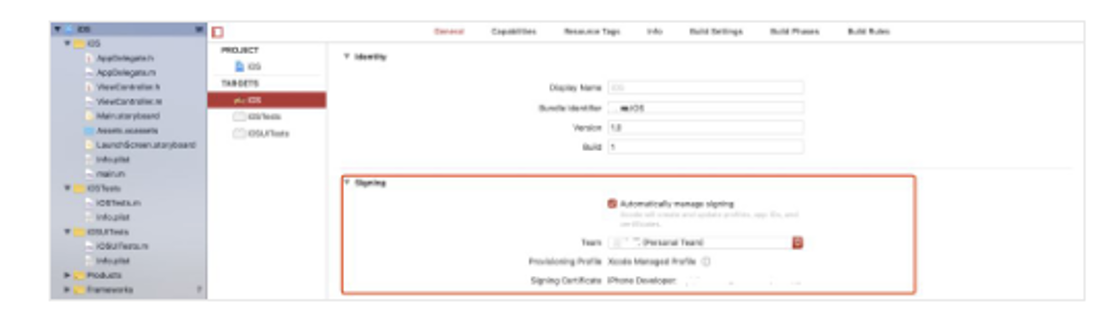
3. 权限设置
-
Xcode 进入 TARGETS > Project Name > General > Signing 菜单,选择 Automatically manage signing ,并在弹出菜单中点击 Enable Automatic 。
-
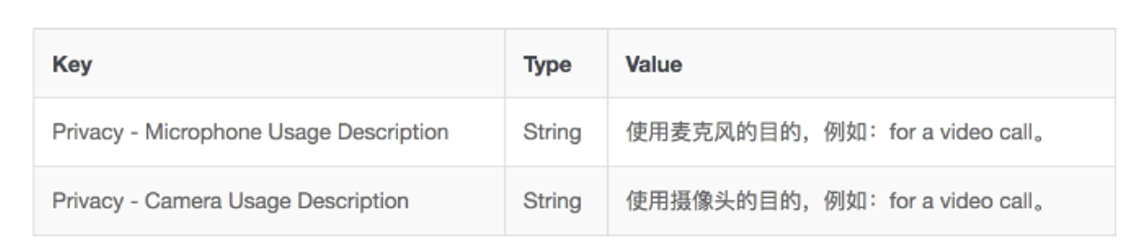
添加媒体设备权限 根据场景需要,在 info.plist 文件中,点击 + 图标开始添加如下内容,获取相应的设备权限:
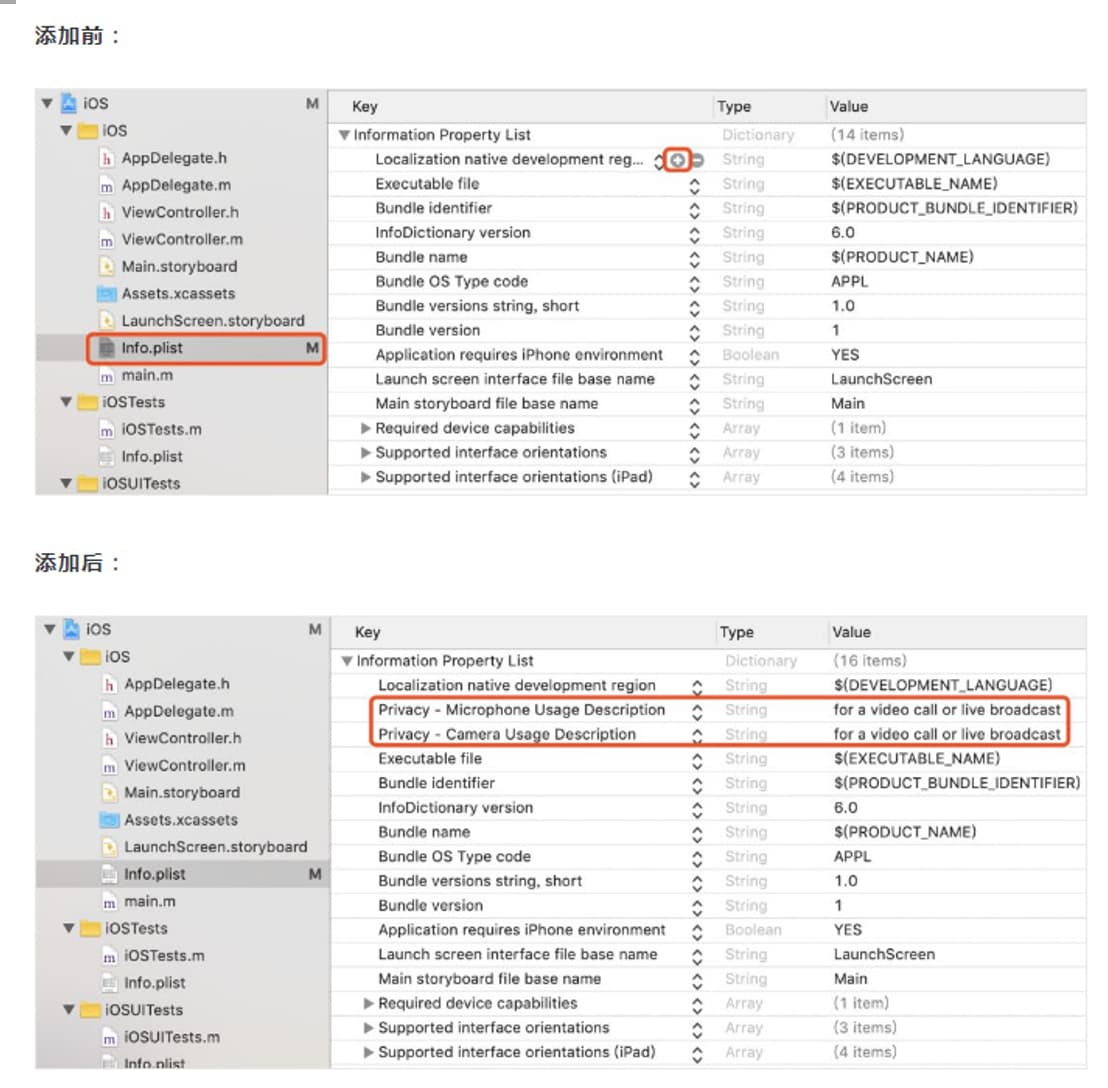
4. 导入 Agora 相关的类
在项目中导入 AgoraRtcEngineKit 类:
// Objective-C // ViewController.h // 导入 AgoraRtcKit 类 // 自 3.0.0 版本起,AgoraRtcEngineKit 类名更换为 AgoraRtcKit // 如果获取的是 3.0.0 以下版本的 SDK ,请改用 #import <AgoraRtcEngineKit/AgoraRtcEngineKit.h> #import <AgoraRtcKit/AgoraRtcEngineKit.h> // 声明 AgoraRtcEngineDelegate ,用于监听回调 @interface ViewController : UIViewController <AgoraRtcEngineDelegate> // 定义 agoraKit 变量 @property (strong, nonatomic) AgoraRtcEngineKit *agoraKit; // Swift // ViewController.swift // 导入 AgoraRtcKit 类 // 自 3.0.0 版本起,AgoraRtcEngineKit 类名更换为 AgoraRtcKit // 如果获取的是 3.0.0 以下版本的 SDK ,请改用 import AgoraRtcEngineKit import AgoraRtcKit class ViewController: UIViewController { ... // 定义 agoraKit 变量 var agoraKit: AgoraRtcEngineKit? } 5. 设置 Agora 账号信息
在 AppID.swift 文件中,将你的 AppID 填写到 let AppID ,可替换“Your App ID”;
// Objective-C // AppID.m // Agora iOS Tutorial Objective-C #import <Foundation/Foundation.h> NSString *const appID = <#Your App ID#>; // Swift // AppID.swift // Agora iOS Tutorial let AppID: String = Your App ID 五、 客户端实现
本节介绍如何使用 Agora 视频 SDK 在你的 App 里实现视频通话的几个小贴士:
1. 创建用户界面
根据场景需要,为你的项目创建视频通话的用户界面。我们推荐你在项目中添加元素:本地视频窗口、远端视频窗口。 你可以参考以下代码创建一个基础的用户界面。
// Objective-C // ViewController.m // 导入 UIKit #import <UIKit/UIKit.h> @interface ViewController () // 定义 localView 变量 @property (nonatomic, strong) UIView *localView; // 定义 remoteView 变量 @property (nonatomic, strong) UIView *remoteView; @end @implementation ViewController ... - (void)viewDidLoad { [super viewDidLoad]; // 调用初始化视频窗口函数 [self initViews]; // 后续步骤调用 Agora API 使用的函数 [self initializeAgoraEngine]; [self setupLocalVideo]; [self joinChannel]; } // 设置视频窗口布局 - (void)viewDidLayoutSubviews { [super viewDidLayoutSubviews]; self.remoteView.frame = self.view.bounds; self.localView.frame = CGRectMake(self.view.bounds.size.width - 90, 0, 90, 160); } - (void)initViews { // 初始化远端视频窗口 self.remoteView = [[UIView alloc] init]; [self.view addSubview:self.remoteView]; // 初始化本地视频窗口 self.localView = [[UIView alloc] init]; [self.view addSubview:self.localView]; } // Swift // ViewController.swift // 导入 UIKit import UIKit class ViewController: UIViewController { ... // 定义 localView 变量 var localView: UIView! // 定义 remoteView 变量 var remoteView: UIView! override func viewDidLoad() { super.viewDidLoad() // 调用初始化视频窗口函数 initView() // 后续步骤调用 Agora API 使用的函数 initializeAgoraEngine() setupLocalVideo() joinChannel() } // 设置视频窗口布局 override func viewDidLayoutSubviews() { super.viewDidLayoutSubviews() remoteView.frame = self.view.bounds localView.frame = CGRect(x: self.view.bounds.width - 90, y: 0, width: 90, height: 160) } func initView() { // 初始化远端视频窗口 remoteView = UIView() self.view.addSubview(remoteView) // 初始化本地视频窗口 localView = UIView() self.view.addSubview(localView) } } 2. 实现视频通话逻辑
现在,我们已经将 Agora iOS SDK 集成到项目中了。接下来我们要在 ViewController 中调用 Agora iOS SDK 提供的核心 API 实现基础的视频通话功能。你可以在 Agora-iOS-Tutorial-Objective-C-1to1/Agora-iOS-Tutorial-Swift-1to1 示例项目的 VideoChatViewController.m/VideoChatViewController.swift 文件中查看完整的源码和代码逻辑。
API 调用时序见下图:
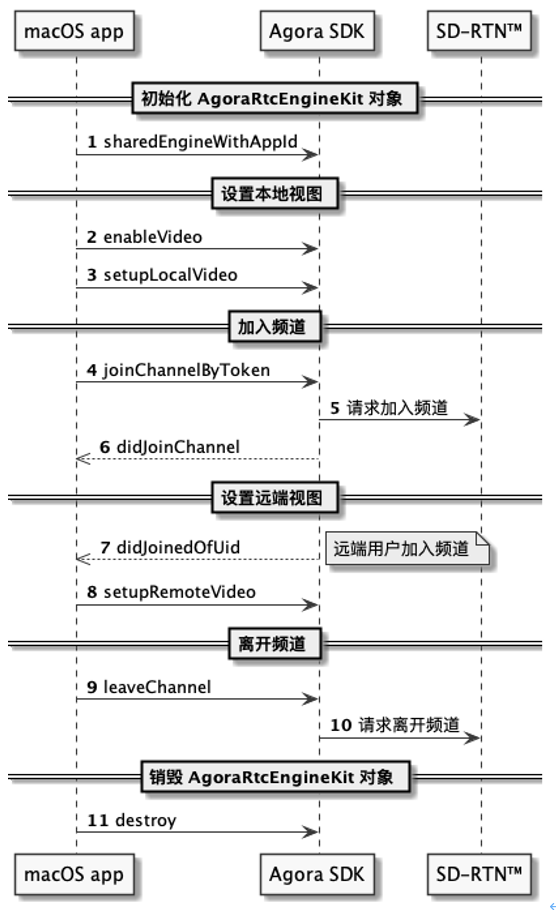
按照以下步骤实现该逻辑:
a) 初始化 AgoraRtcEngineKit 对象 在调用其他 Agora API 前,需要创建并初始化 AgoraRtcEngineKit 对象。调用 sharedEngineWithAppId 方法,传入获取到的 App ID ,即可初始化 AgoraRtcEngineKit 。
// Objective-C - (void)initializeAgoraEngine { // 输入 App ID 并初始化 AgoraRtcEngineKit 类。 self.agoraKit = [AgoraRtcEngineKit sharedEngineWithAppId:appID delegate:self]; } // Swift func initializeAgoraEngine() { // 输入 App ID 并初始化 AgoraRtcEngineKit 类。 agoraKit = AgoraRtcEngineKit.sharedEngine(withAppId: AppID, delegate: self) } 你还可以根据场景需要,在初始化时注册想要监听的回调事件,如本地用户加入频道,及解码远端用户视频首帧等。
b) 设置本地视图 成功初始化 AgoraRtcEngineKit 对象后,需要在加入频道前设置本地视图,以便在通话中看到本地图像。参考以下步骤设置本地视图: · 调用 enableVideo 方法启用视频模块。 · 调用 setupLocalVideo 方法设置本地视图。
// Objective-C // 启用视频模块。 [self.agoraKit enableVideo]; - (void)setupLocalVideo { AgoraRtcVideoCanvas *videoCanvas = [[AgoraRtcVideoCanvas alloc] init]; videoCanvas.uid = 0; videoCanvas.view = self.localVideo; videoCanvas.renderMode = AgoraVideoRenderModeHidden; // 设置本地视图。 [self.agoraKit setupLocalVideo:videoCanvas]; } // Swift // 启用视频模块。 agoraKit.enableVideo() func setupLocalVideo() { let videoCanvas = AgoraRtcVideoCanvas() videoCanvas.uid = 0 videoCanvas.view = localVideo videoCanvas.renderMode = .hidden // 设置本地视图。 agoraKit.setupLocalVideo(videoCanvas) } c) 加入频道 频道是人们在同一个视频通话中的公共空间。完成初始化和设置本地视图后(视频通话场景),你就可以调用 joinChannelByToken 方法加入频道。你需要在该方法中传入如下参数:
- channelId: 传入能标识频道的频道 ID 。输入频道 ID 相同的用户会进入同一个频道。
- token: 传入能标识用户角色和权限的 Token 。你可以设置如下值: a) nil 。 b) 控制台中生成的临时 Token 。一个临时 Token 的有效期为 24 小时,详情见获取临时 Token 。 c) 你的服务器端生成的正式 Token 。适用于对安全要求较高的生产环境,详情见生成 Token 。若项目已启用 App 证书,请使用 Token 。 d) uid: 本地用户的 ID 。数据类型为整型,且频道内每个用户的 uid 必须是唯一的。若将 uid 设为 0 ,则 SDK 会自动分配一个 uid ,并在 joinSuccessBlock 回调中报告。 e) joinSuccessBlock:成功加入频道回调。joinSuccessBlock 优先级高于 didJoinChannel ,2 个同时存在时,didJoinChannel 会被忽略。需要有 didJoinChannel 回调时,请将 joinSuccessBlock 设置为 nil 。
更多的参数设置注意事项请参考 joinChannelByToken 接口中的参数描述。
// Objective-C - (void)joinChannel { // 加入频道。 [self.agoraKit joinChannelByToken:token channelId:@"demoChannel1" info:nil uid:0 joinSuccess:^(NSString *channel, NSUInteger uid, NSInteger elapsed) { }]; } // Swift func joinChannel() { // 加入频道。 agoraKit.joinChannel(byToken: Token, channelId: "demoChannel1", info:nil, uid:0) { [unowned self] (channel, uid, elapsed) -> Void in} self.isLocalVideoRender = true self.logVC?.log(type: .info, content: "did join channel") } isStartCalling = true } d) 设置远端视图 视频通话中,通常你也需要看到其他用户。在加入频道后,可通过调用 setupRemoteVideo 方法设置远端用户的视图。
远端用户成功加入频道后,SDK 会触发 firstRemoteVideoDecodedOfUid 回调,该回调中会包含这个远端用户的 uid 信息。在该回调中调用 setupRemoteVideo 方法,传入获取到的 uid ,设置远端用户的视图。
// Objective-C // 监听 firstRemoteVideoDecodedOfUid 回调。 // SDK 接收到第一帧远端视频并成功解码时,会触发该回调。 // 可以在该回调中调用 setupRemoteVideo 方法设置远端视图。 - (void)rtcEngine:(AgoraRtcEngineKit *)engine firstRemoteVideoDecodedOfUid:(NSUInteger)uid size: (CGSize)size elapsed:(NSInteger)elapsed { if (self.remoteVideo.hidden) { self.remoteVideo.hidden = NO; } AgoraRtcVideoCanvas *videoCanvas = [[AgoraRtcVideoCanvas alloc] init]; videoCanvas.uid = uid; videoCanvas.view = self.remoteVideo; videoCanvas.renderMode = AgoraVideoRenderModeHidden; // 设置远端视图。 [self.agoraKit setupRemoteVideo:videoCanvas]; } // Swift // 监听 firstRemoteVideoDecodedOfUid 回调。 // SDK 接收到第一帧远端视频并成功解码时,会触发该回调。 // 可以在该回调中调用 setupRemoteVideo 方法设置远端视图。 func rtcEngine(_ engine: AgoraRtcEngineKit, firstRemoteVideoDecodedOfUid uid:UInt, size:CGSize, elapsed:Int) { isRemoteVideoRender = true let videoCanvas = AgoraRtcVideoCanvas() videoCanvas.uid = uid videoCanvas.view = remoteVideo videoCanvas.renderMode = .hidden // 设置远端视图。 agoraKit.setupRemoteVideo(videoCanvas) } e) 离开频道 根据场景需要,如结束通话、关闭 App 或 App 切换至后台时,调用 leaveChannel 离开当前通话频道。
// Objective-C - (void)leaveChannel { // 离开频道。 [self.agoraKit leaveChannel:^(AgoraChannelStats *stat) } // Swift func leaveChannel() { // 离开频道。 agoraKit.leaveChannel(nil) isRemoteVideoRender = false isLocalVideoRender = false isStartCalling = false self.logVC?.log(type: .info, content: "did leave channel") } f) 销毁 AgoraRtcEngineKit 对象 最后,离开频道,我们需要调用 destroy 销毁 AgoraRtcEngineKit 对象,释放 Agora SDK 使用的所有资源。
// Objective-C // ViewController.m // 将以下代码填入你定义的函数中 [AgoraRtcEngineKit destroy]; // Swift // ViewController.swift // 将以下代码填入你定义的函数中 AgoraRtcEngineKit.destroy() 至此,完成,运行看看效果。拿两部 iOS 手机安装编译好的 App ,加入同一个频道名,如果 2 个手机都能看见本地和远端视频图像,说明你成功了。
如果你在开发过程中遇到问题,可以访问论坛提问与声网工程师交流https://rtcdeveloper.agora.io/
]]>




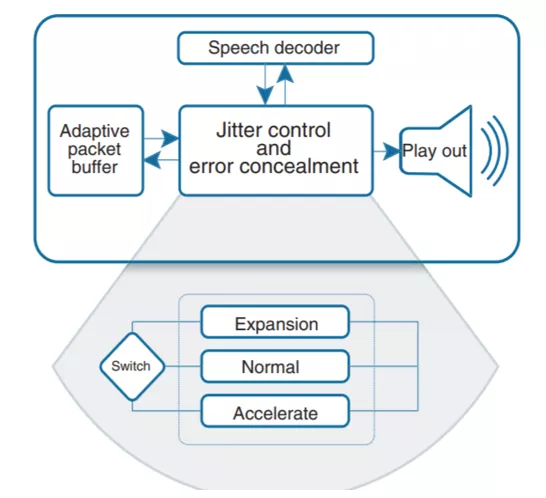
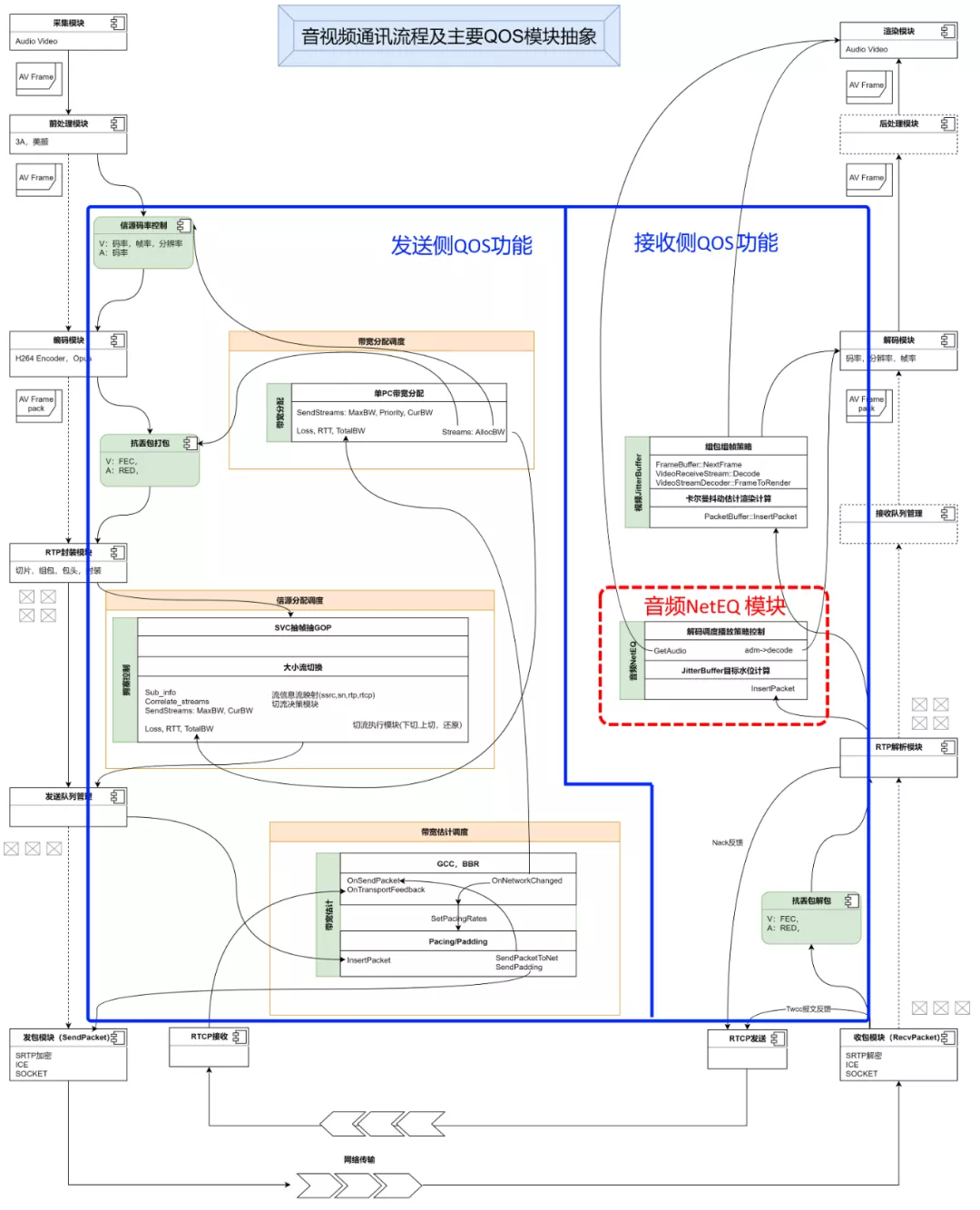
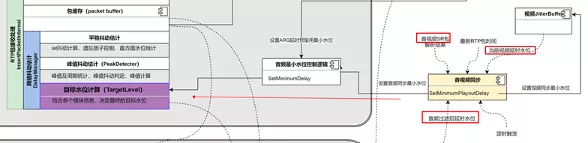
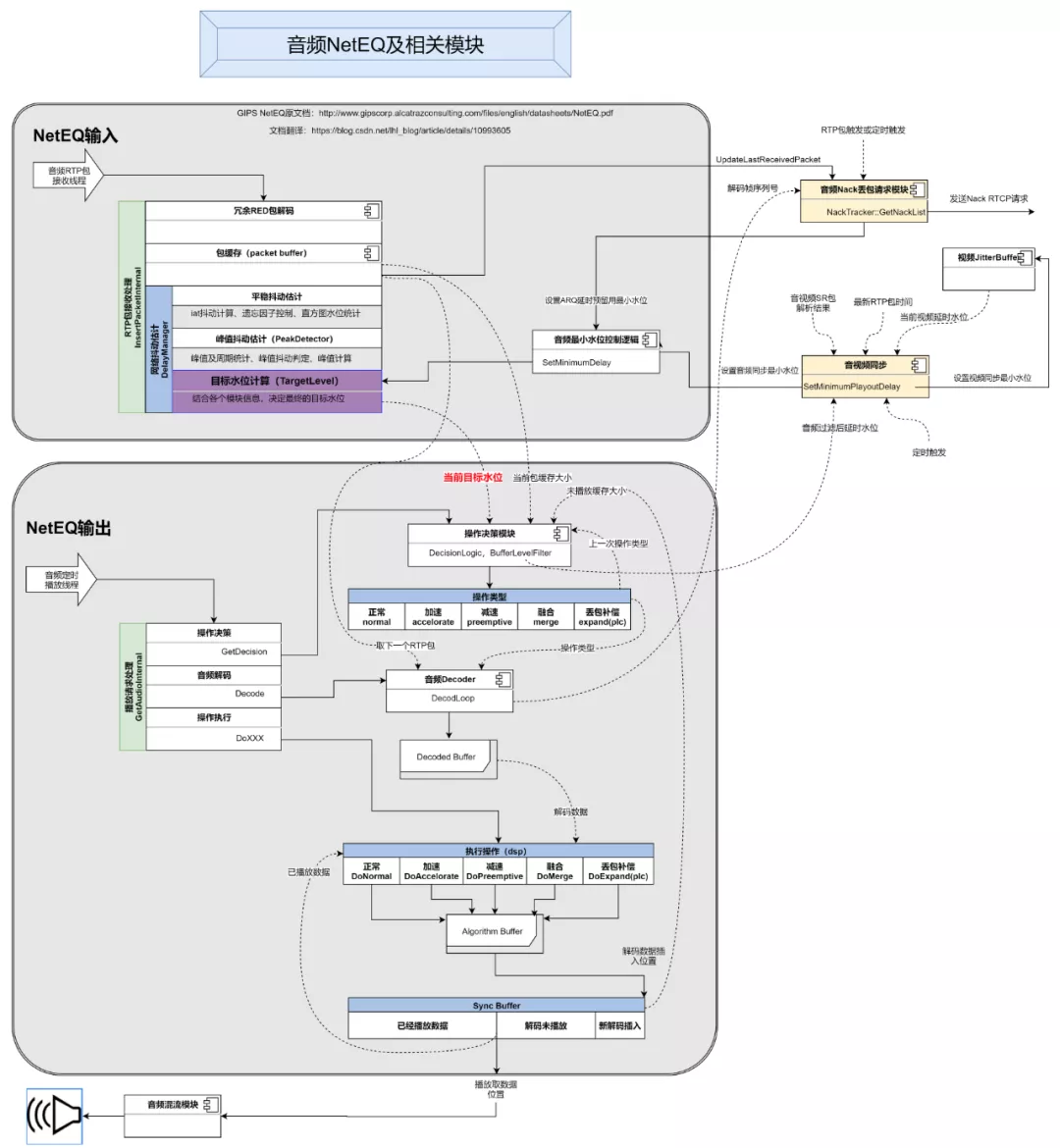 上面这张图是对 NetEQ 及其相关模块工作流程的抽象,主要包含 4 个部分,NetEQ 的输入、NetEQ 的输出、音频重传 Nack 请求模块、音视频同步模块。为什么要把 Nack 请求模块和音视频同步模块也放进 NetEQ 的分析中?因为这两个模块都直接跟 NetEQ 有依赖,相互影响。图里面的虚线,标识每个模块依赖的其它模块的信息,以及这些信息的来源。接下来介绍一下整个流程。
上面这张图是对 NetEQ 及其相关模块工作流程的抽象,主要包含 4 个部分,NetEQ 的输入、NetEQ 的输出、音频重传 Nack 请求模块、音视频同步模块。为什么要把 Nack 请求模块和音视频同步模块也放进 NetEQ 的分析中?因为这两个模块都直接跟 NetEQ 有依赖,相互影响。图里面的虚线,标识每个模块依赖的其它模块的信息,以及这些信息的来源。接下来介绍一下整个流程。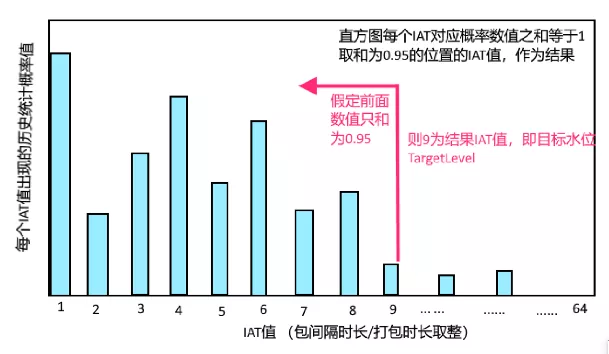
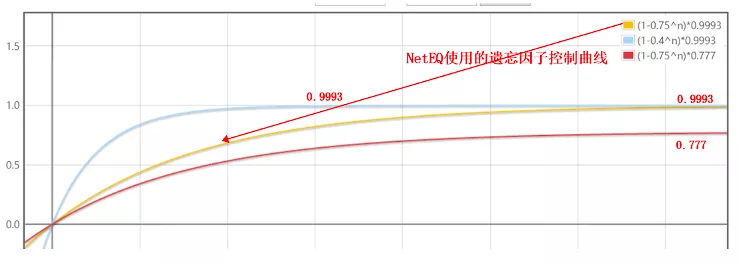
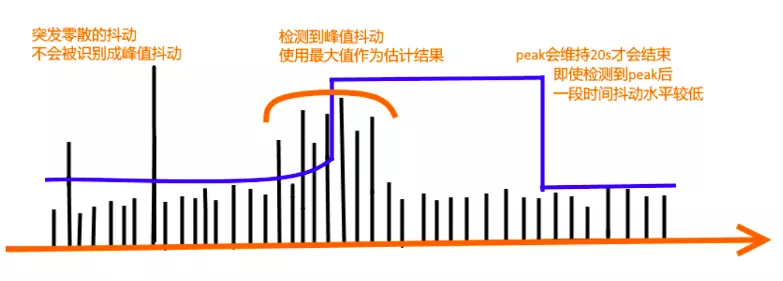
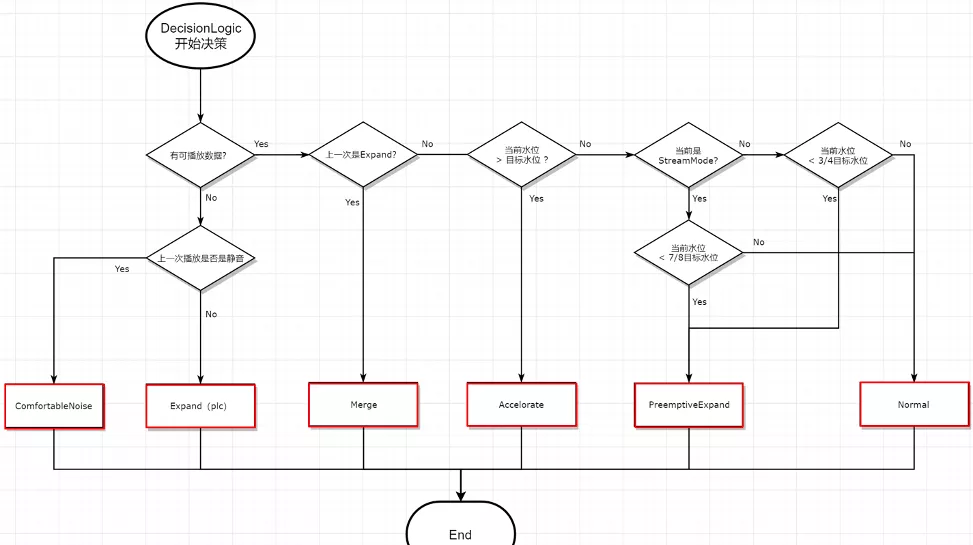
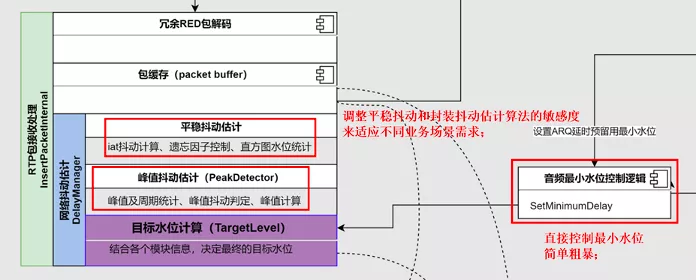
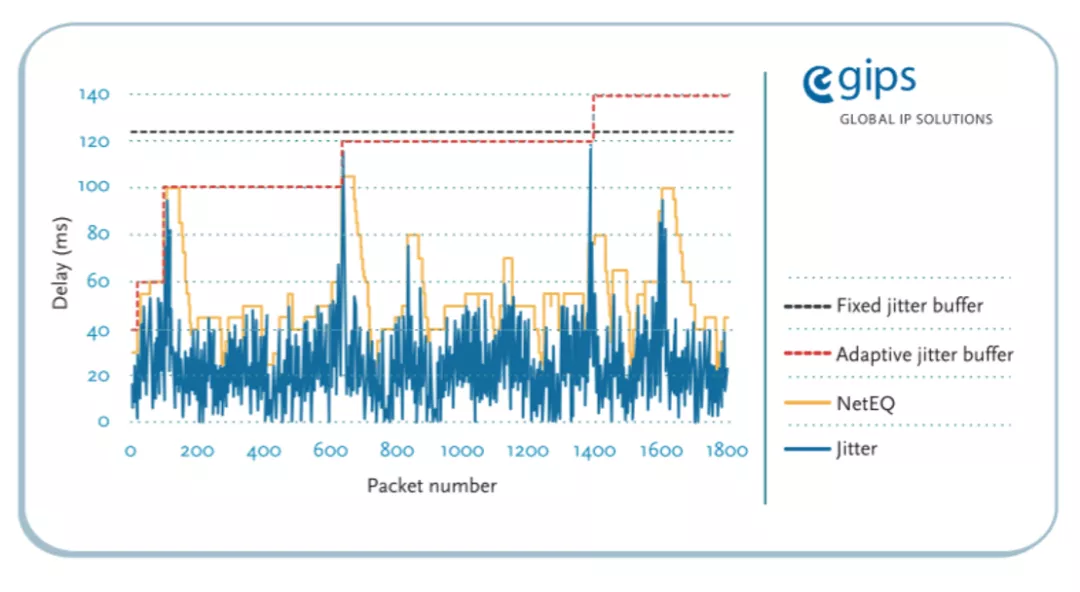
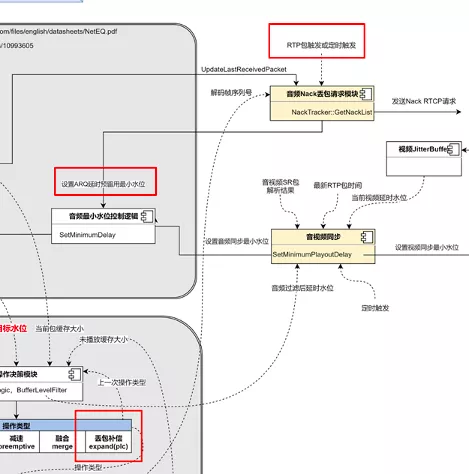 下面是 ARQ 延时预留功能开启后的效果对比,平均拉伸率降低 50%,延时也会相应增加:
下面是 ARQ 延时预留功能开启后的效果对比,平均拉伸率降低 50%,延时也会相应增加: 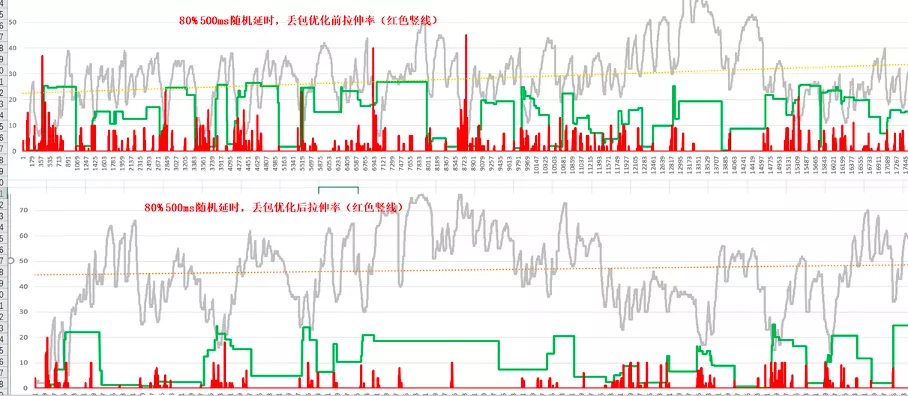
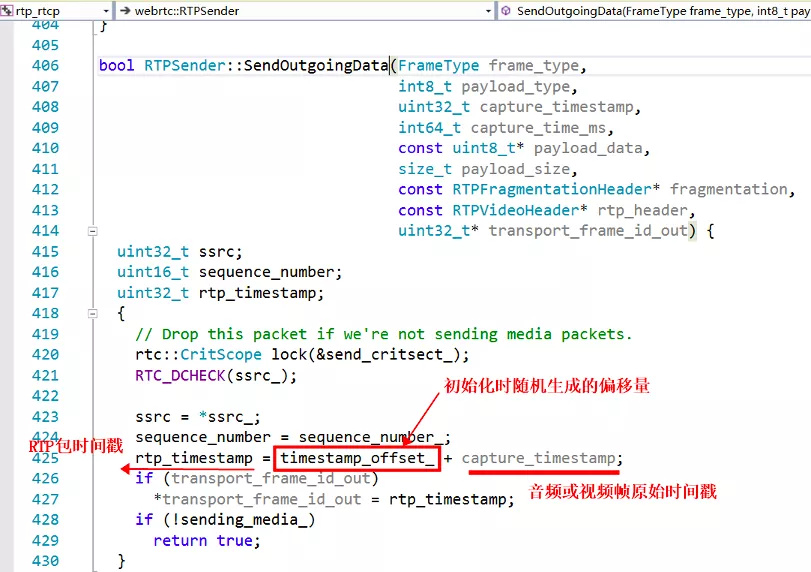
 为什么视频帧采用了跟音频帧不同的时间戳计算机制呢?我的理解,一般情况音频的采集设备的采样间隔和时钟精度更加准确,10ms 一帧,每秒是 100 帧,一般不会出现大的抖动,而视频帧的帧间隔时间较大采集精度,每秒 25 帧的话,就是 40ms 一帧。如果还采用音频的按照采样率来递增的话,可能会出现跟实际时钟对不齐的情况,所以就直接每取一帧,按照取出时刻的系统时钟算出一个时间戳,这样可以再现真实视频帧跟实际时间的对应关系。
为什么视频帧采用了跟音频帧不同的时间戳计算机制呢?我的理解,一般情况音频的采集设备的采样间隔和时钟精度更加准确,10ms 一帧,每秒是 100 帧,一般不会出现大的抖动,而视频帧的帧间隔时间较大采集精度,每秒 25 帧的话,就是 40ms 一帧。如果还采用音频的按照采样率来递增的话,可能会出现跟实际时钟对不齐的情况,所以就直接每取一帧,按照取出时刻的系统时钟算出一个时间戳,这样可以再现真实视频帧跟实际时间的对应关系。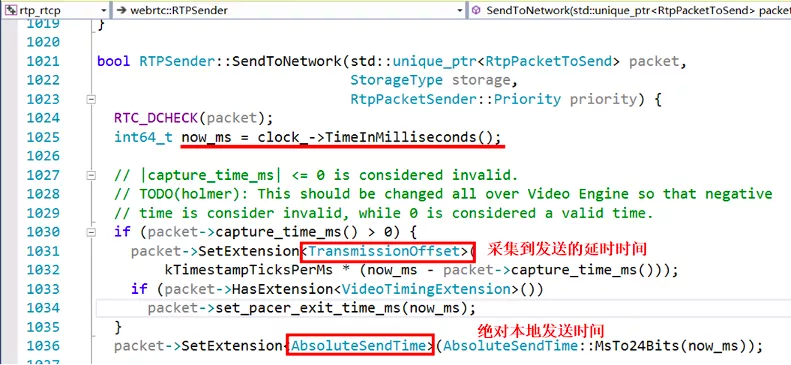
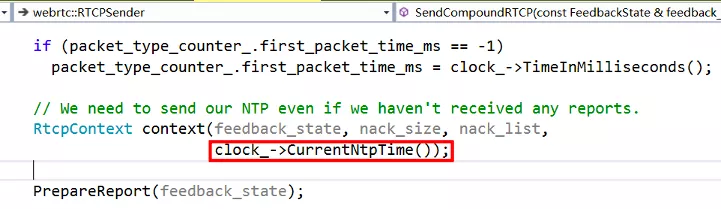
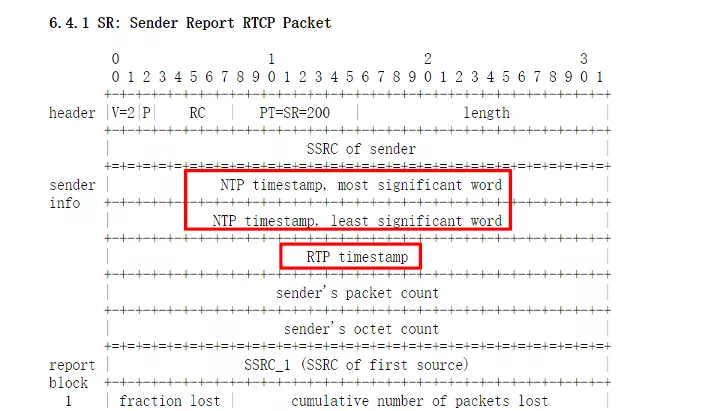 SR 包的其中一个作用就是来告诉我们每个流的 RTP 包的时间戳和 NTP 时间的对应关系的。靠的就是上边图片中标出的 NTP 时间戳和 RTP 时间戳,通过 RFC3550 的描述,我们知道这两个时间戳对应的是同一个时刻,这个时刻表示此 SR 包生成的时刻。这就是我们对音视频进行同步的最核心的依据,所有的其它计算都是围绕这个核心依据来展开的。
SR 包的其中一个作用就是来告诉我们每个流的 RTP 包的时间戳和 NTP 时间的对应关系的。靠的就是上边图片中标出的 NTP 时间戳和 RTP 时间戳,通过 RFC3550 的描述,我们知道这两个时间戳对应的是同一个时刻,这个时刻表示此 SR 包生成的时刻。这就是我们对音视频进行同步的最核心的依据,所有的其它计算都是围绕这个核心依据来展开的。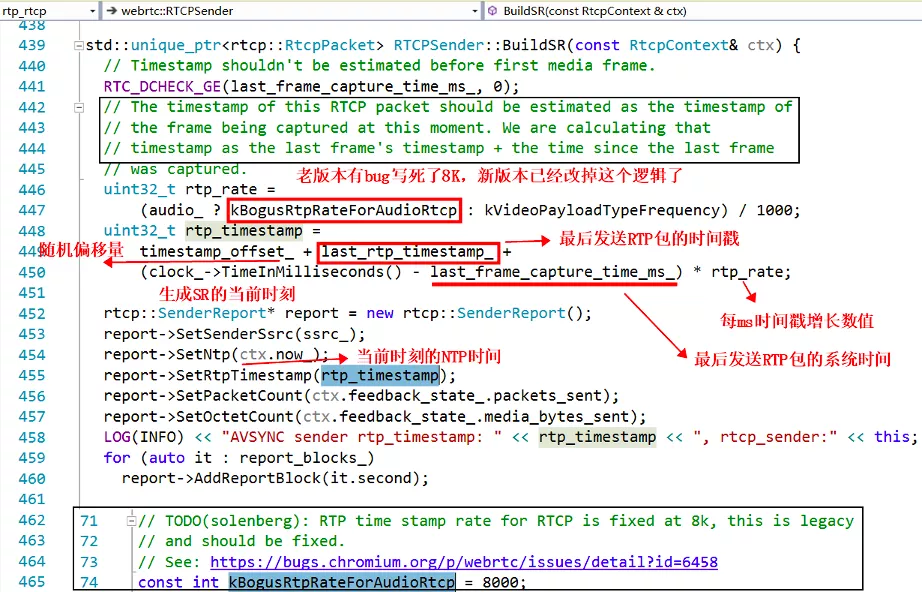
 其次,我们要计算当前时刻,应该对应的 RTP 的时间戳是多少。根据最后一个发送的 RTP 包的时间戳
其次,我们要计算当前时刻,应该对应的 RTP 的时间戳是多少。根据最后一个发送的 RTP 包的时间戳 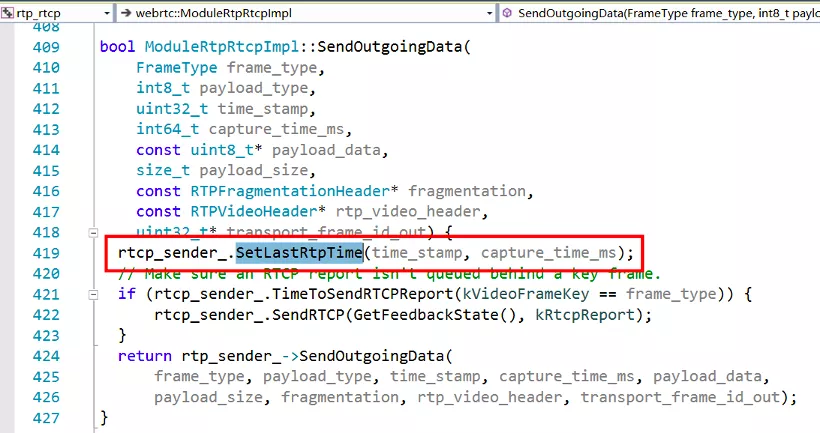
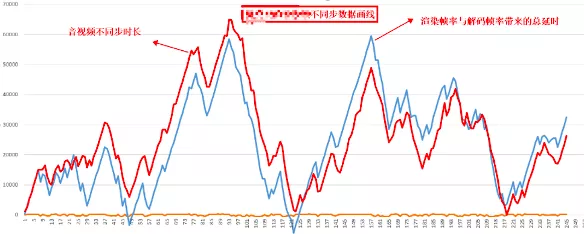
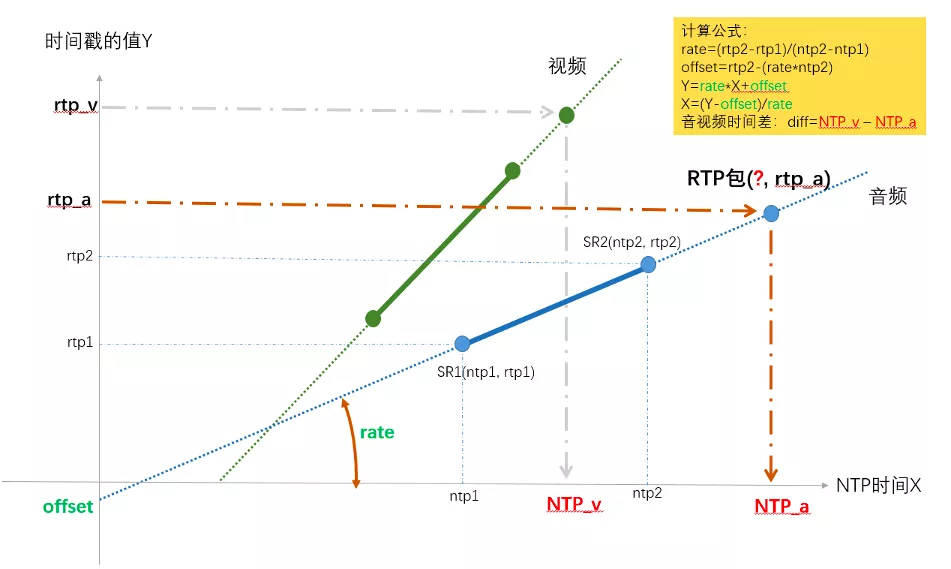 上图以音频的两个 SR 包为例,确定出了 RTP 和 NTP 对应关系的直线,然后给任意一个 rtp_a,就算出了其对应的 NTP_a,同理也可以求任意视频包 rtp_v 对应的 NTP_v 的时间点,两个的差值就是时间差。
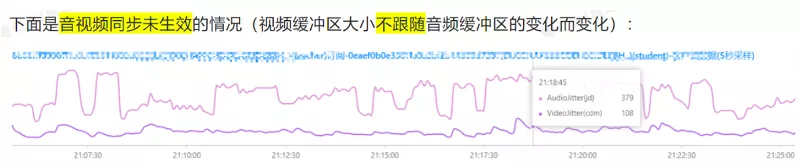
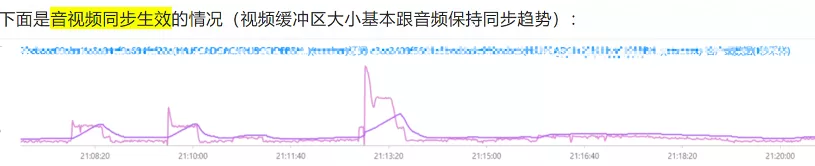
上图以音频的两个 SR 包为例,确定出了 RTP 和 NTP 对应关系的直线,然后给任意一个 rtp_a,就算出了其对应的 NTP_a,同理也可以求任意视频包 rtp_v 对应的 NTP_v 的时间点,两个的差值就是时间差。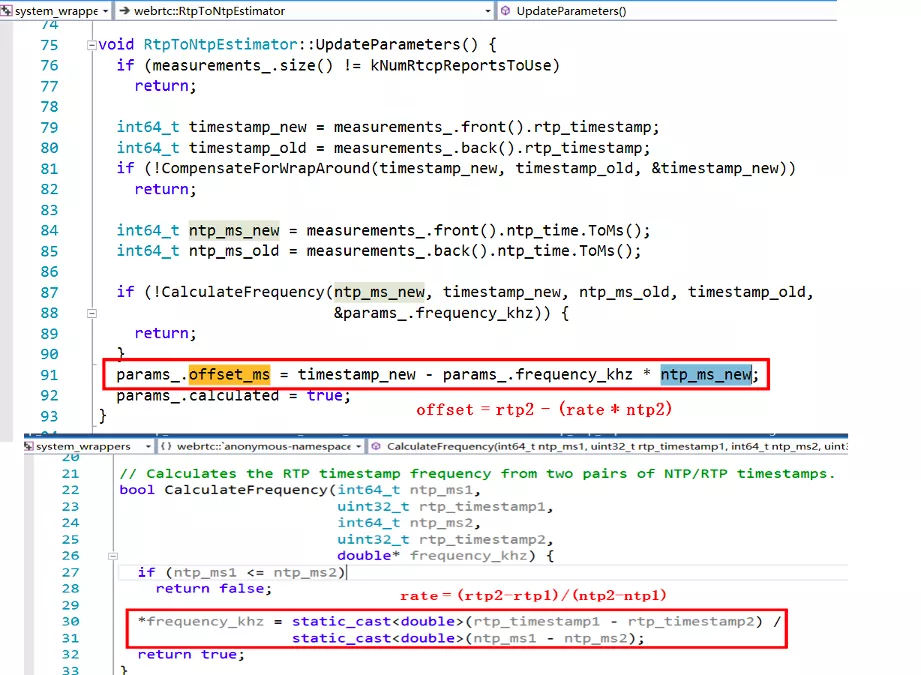 在 WebRTC 中计算的是最新收到的音频 RTP 包和最新收到的视频 RTP 包的对应的 NTP 时间,作为网络传输引入的不同步时长,然后又根据当前音频和视频的 JitterBuffer 和播放缓冲区的大小,得到了播放引入的不同步时长,根据两个不同步时长,得到了最终的音视频不同步时长,计算过程在
在 WebRTC 中计算的是最新收到的音频 RTP 包和最新收到的视频 RTP 包的对应的 NTP 时间,作为网络传输引入的不同步时长,然后又根据当前音频和视频的 JitterBuffer 和播放缓冲区的大小,得到了播放引入的不同步时长,根据两个不同步时长,得到了最终的音视频不同步时长,计算过程在  WebRTC 中实现音视频同步的手段就是 SR 包,核心的依据就是 SR 包中的 NTP 时间和 RTP 时间戳。最后的两张
WebRTC 中实现音视频同步的手段就是 SR 包,核心的依据就是 SR 包中的 NTP 时间和 RTP 时间戳。最后的两张