
自动生成 5 篇文章 按热度排序
Mythos Finds a Curl Vulnerability 615票 252评论 by Daniel Stenberg
标签:安全, curl, 漏洞, Mythos, AI安全
背景注释: curl (由 Daniel Stenberg 开发的命令行 HTTP/FTP 客户端/库) | Daniel Stenberg (curl 创始人,Haxx 创始人,开源安全重要人物) | Mythos (Anthropic 开发的 AI 安全研究系统) | 漏洞猎人 (使用 AI 自动发现开源软件漏洞的新兴领域)
Anthropic 旗下被宣传为"危险地好"的 AI 安全扫描模型 Mythos 对 curl 进行了代码审计,最终仅发现一个低危漏洞。curl 维护者 Daniel Stenberg 指出,此前多种 AI 工具已发现约两三百个 bug,Mythos 并无显著优势,认为炒作主要是营销;但他也强调 AI 代码审查工具整体确实比传统工具强大,建议所有项目都采用。
Mythos 在 curl 中发现了一个漏洞
是的,只是一个,即 singular "one"。
2026年4月,Anthropic 引发了大量媒体噪音,当时他们得出结论:他们新的 AI 模型 Mythos 在发现源代码中的安全漏洞方面"危险地好"。显然 Mythos 在这方面表现如此出色,以至于 Anthropic 不会向公众发布这个模型,而是将其限量提供给一些精选公司一段时间,让一些优质客户(?)先行一步,在普通大众拿到它之前先修复最紧迫的问题。
全世界似乎都失去了理智。这是世界末日的开始吗?这无疑是一场非常成功的营销恶作剧。
我的(非)访问
Anthropic 与"Glasswing 项目"合作的一部分内容是,Anthropic 还通过 Linux 基金会向"开源项目"提供访问其最新 AI 模型的渠道。Linux 基金会让他们旗下的 Alpha Omega 项目处理这部分,而我被他们的代表联系上了。作为 curl 的 lead developer,我很荣幸地获得了访问这个神奇模型的资格并欣然接受了邀请。当然,我想看看它能在 curl 中发现什么。
我签署了获取访问权的合同,但之后什么也没发生。数周过去了,我被告知某处出了点问题,访问被延迟了。
最终,有人提议说,其他拥有模型访问权限的人可以代表我使用 Mythos 对 curl 进行扫描和分析,并将报告发送给我。对我来说,这个区别并不重要。我不会有太多时间去探索各种不同的提示词并做深入研究。无论谁来运行它,能让工具生成一份合格的初步扫描和分析报告就很好了。我愉快地接受了这个提议。
(我有意省略了完成 curl 分析的个人身份,因为这不是这篇博文的主题。)
AI 对 curl 的扫描
在收到这份首个 Mythos 报告之前,我们已经使用多种不同的强大 AI 驱动工具对 curl 进行了扫描(我是说"除了"持续运行大量"普通"静态代码分析器、使用最严格的编译器选项、以及多年模糊测试之外")。主要是 AISLE、Zeropath 和 OpenAI 的 Codex Security 被用于通过 AI 严格审查代码。这些工具及其分析在过去 8-10 个月左右的时间里触发了大约两到三百个错误修复被合并到 curl 中。其中相当一部分由这些 AI 工具报告的发现已被确认为漏洞,并被发布为 CVE,可能有十几甚至更多。
如今,我们还使用 GitHub Copilot 和 Augment code 等工具来审查 pull requests,它们的意见和投诉帮助我们提交更好的代码并避免合并新的 bug。我的意思是,我们当然仍然会合并 bug,但 PR 审查机器人会定期高亮显示我们修复的问题:如果没有它们,我们的合并会更糟。AI 审查是"附加"于人类审查之上的。它们帮助我们,而不是取代我们。
我们还看到大量高质量的安全报告汹涌而来:安全研究人员现在广泛而有效地使用 AI。
安全对我们 curl 项目来说是"头等大事"。我们遵循每一条指导方针,并正确地进行软件工程,以减少代码中的缺陷。扫描缺陷只是保持这艘船安全的众多步骤之一。你需要非常努力地寻找另一个在软件安全方面做得与 curl 一样多或更多的软件项目。
保持 curl 安全的步骤
2026年5月6日
我们怀着极大的期待收到了由 Mthos 生成的首份源代码分析报告。这是我们又一次找到需要改进的地方和修复 bug 的机会。打造一个更好的 curl。
这次初步扫描是在 curl 的 git 仓库及其 master 分支的某个特定 commit 上进行的。它统计了 src/ 和 lib/ 子目录中分析的 178K 行代码。
该分析详细说明了它执行搜索的几种不同方法和手段,以及它如何专注于尝试找出哪些缺陷。报告顶部有一条有趣的注释:
"curl 是现存被 fuzz 测试和审计最多的 C 代码库之一(OSS-Fuzz、Coverity、CodeQL、多次付费审计)。在热路径(HTTP/1、TLS、URL 解析核心)中找到任何问题的可能性很小。"
……它正确地在这些区域没有发现任何问题。
Mastodon 上一个完全非科学的投票,关于人们对 Mythos 扫描 curl 的期望
curl 的规模
curl 目前在排除空行的情况下有 176,000 行 C 代码。源代码由 660,000 个单词组成,比小说《战争与和平》英文版的全部内容多 12%。
平均而言,curl 中每一条生产源代码行都已经被编写(然后重写)了 4.14 次。我们对此精雕细琢。
此刻,仍然保留在 git master 中的现有生产代码由 573 个不同的人创作。随着时间的推移,共有 1,465 个人到目前为止在 curl 的 git 仓库中提交了他们的更改并被合并。
到目前为止,我们已经为 curl 发布 188 个 CVE。
curl 被安装在超过 200 亿个实例中。它运行在超过 110 个操作系统和 28 种 CPU 架构上。它运行在地球上的每一部智能手机、平板电脑、汽车、电视、游戏机和服务器中。
五个发现变成了一个
报告得出结论,它发现了五个"已确认的安全漏洞"。我认为当 AI 自信地说出这个结论时,使用"已确认"这个词有点好笑。是的,AI 认为它们是已确认的,但 curl 安全团队的观点略有不同。
五个问题感觉不算什么,因为我们原本期待的是一份很长的清单。一旦我和我的 curl 安全团队成员对这些短清单进行了数小时的深入研究和细节挖掘,我们就把清单缩减到一个被确认的漏洞。另外四个中,有三个是误报(它们高亮显示的缺点在 API 文档中有记录),第四个我们认为是"只是一个 bug"。
这个被确认的漏洞将成为一个低危 CVE,计划与我们在 6 月底待发布的下一个 curl 版本 8.21.0 同步发布。这个缺陷不会让任何人感到呼吸困难。所有这些漏洞的细节当然不会在那之前公开,所以你需要在公布细节之前耐心等待。
Mythos 关于 curl 的报告还包含一些被发现的 bug,报告认为这些不是漏洞,就像任何新的代码分析器在你对数十万行代码运行它时会做的那样。报告中的所有 bug 都在被调查,我们一个一个地修复那些我们认同的 bug。
总的来说大约有二十个被描述和解释得非常清楚的 bug。几乎没有误报,所以我猜他们的确定性阈值相当高。
curl 肯定因此变得更好,但要按发现的问题数量计算,我们之前使用的所有 AI 工具都产生了更多数量的 bug 修复。这当然是很自然的,因为我们运行的首批工具已经有了更多更容易发现的 bug。随着我们一路修复问题,发现新问题逐渐变得更难了。此外,bug 有大有小,所以仅比较数字并不总是公平的。
并非特别"危险"
然而,我的个人结论只能是这样:到目前为止,围绕这个模型的大量炒作主要是营销。我没有看到证据表明这个设置在发现问题上比 Mythos 之前的其他工具更高明或更高级。也许这个模型稍微好一点,但即使有,也不会有好到在代码分析方面产生显著影响的程度。
这只是其中一个源代码仓库,也许它在其他方面要好得多。我只能对我看到的发现发表看法和评论。
仍然非常好
但请允许我强调并重申我之前说过的话:AI 驱动的代码分析器在发现源代码中的安全缺陷和错误方面明显比以前任何传统代码分析器都要好。所有现代 AI 模型现在都在这方面做得很好。任何有时间且有一些实验精神的人现在都可以找到安全问题。高质量的混乱是真实的。
任何尚未使用 AI 驱动工具扫描其源代码的项目,很可能会使用这新一代工具发现大量缺陷、bug 和可能的漏洞。Mythos 会做到,其他许多工具也会。
不在你的项目中使用 AI 代码分析器意味着你给对手和攻击者留出了时间和机会,让他们去发现和利用你找不到的缺陷。
AI 分析器有何不同
它们可以发现注释中说的与代码实际做的之间的矛盾,然后得出代码没有按注释所述工作的结论。 它可以检查我们无法运行分析器的平台和配置的代码 它"知道"第三方库及其 API 的细节,因此可以检测滥用或错误假设。 它"知道"curl 实现的协议的细节,可以质疑代码中似乎违反或矛盾协议规范的地方 它们通常善于总结和解释缺陷,这是旧式分析器相当繁琐和困难的事情。 它们通常可以生成并提供一个补丁来修复它发现的问题(即使补丁通常不是 100% 的修复)。 报告的更多细节
零内存安全漏洞被发现。
方法论说明:本次审查是由 LLM 子代理进行并行文件读取的手动驱动分析,每一个候选发现在被记录之前都会在主会话中通过直接源代码检查进行重新验证。CVE 到变体追踪的映射是从 curl 自己的 vuln.json 构建的。没有使用自动化的 SAST 工具。
这一结果与 curl 作为最被 fuzz 测试和审计最多的 C 代码库之一的状态一致。防御性基础设施(到处使用的受限动态缓冲区、curlx_str_number 在每个数字解析上都有明确的 max、curlx_memdup0 溢出保护、CURL_PRINTF 格式字符串强制、每个协议的响应大小上限、pingpong 64KB 行限制)系统性地关闭了在这个规模的代码库中通常会产生效果的 bug 类型。
覆盖范围现在包括:所有小协议、所有文件解析器、所有 TLS 后端的验证路径、http/1/2/3、ftp 全深度、mprintf、x509asn1、doh、所有认证机制、内容编码、连接重用、会话缓存、CLI 工具、平台特定代码,以及 CI/构建供应链。
AI 发现已知类型的错误
应该指出的是,AI 工具找到的是我们已知的那种通常的错误。它只是找到了新的实例。
到目前为止,我们还没有看到任何 AI 报告一种全新或完全不同类型的漏洞。它们不会以那种方式重塑这个领域,但它们确实比以前的任何工具挖出了更多问题。
更多待发现
这些绝不是最后一个要发现或报告的 bug。就在我写这篇博文草稿的过程中,我们已经收到了更多来自安全研究人员关于疑似问题的报告。AI 工具将进一步改进,研究人员可以找到新的不同方法来提示现有的 AI,使它们发现更多问题。
我们还没有走到这条路的尽头。
我希望我们能继续用 Mythos 和其他 AI 对 curl 进行更多扫描,一次又一次,直到它们真正停止发现新问题。
鸣谢
感谢 Anthropic 和 Alpha Omega 提供模型、工具并为我们进行扫描。还要感谢代表我们进行扫描的个人。非常感谢!
顶部图片:来自 Pixabay 的 Jin Kim
感谢使用 curl。永远不会无聊。
HN 热评中文翻译(共252条评论,选取代表性观点)
rzmmm (615分话题)
引述:"我个人的结论只能是这样:到目前为止,围绕这个模型的大量炒作主要是营销。我没有看到证据表明这个设置在发现问题上比 Mythos 之前的其他工具更高明或更高级。也许这个模型稍微好一点,但即使有,也不会有好到在代码分析方面产生显著影响的程度。"
这是对我们所有人的一个很好的提醒:这个领域的竞争非常激烈,而且涉及大量或微妙或直接的营销。
therealpygon
更认真地说,到目前为止我没有看到任何迹象表明 Mythos 仅仅是 Opus 加了一个安全focused的代码分析工具包。尽管如此,它能够自动发现这些 bug 这一事实才是 hype 之外更重要的收获。我很好奇它的检测错误率是多少,因为如果它 90% 的情况下都是错的,而我们只听到那些对营销有用的例子,那这些都没多大意义。
johnbarron
Anthropic 用营销来说服人们他们的模型更先进、更 built,或者 AI 是一个需要被监管的威胁因为只有他们才有答案?我很震惊。
我记得 OpenAI 当时说 GPT-2 太危险不能发布。
stingraycharles
如果我没记错的话,在那波媒体炒作之后,他因为违反保密协议丢了工作。
这与营销相反,Google 真的不知道如何将其转化为产品直到 ChatGPT 出现。
GuB-42
curl 使用各种工具,包括 AI 工具来发现 bug。根据这篇文章,这些工具在近 8-10 个月里发现了数百个 bug,包括十几个 CVE。
Mythos 只发现了一个漏洞。这意味着 Mythos 只是一个工具,而不是它所声称的革命性产品。
当一个新工具被引入时,首先会发现一大堆 bug,然后是递减回报。Mythos 只发现一个漏洞,这符合我对现有 LLM 解决方案的重大更新版工具的预期。
wongarsu
Mozilla 谈到的是三个因素(AI 工具、专业知识和时间)的组合导致发现大量安全漏洞。curl 文章的引述只提到了第2和第3点,但仅用常规 SotA 模型本可以产生非常相似的结果。
这确实是 Mythos 炒作的核心:使用 Claude Opus 而不是 Claude Mythos 真的会得出不同的结果吗?有多少是模型本身的功劳,有多少是工具包的功劳,又有多少仅仅是因为 Anthropic 正在开展一场大张旗鼓的系统性寻找漏洞的运动?
pavon
让 Mythos 对 Mozilla 如此有效的一部分原因是其集成的 agentic 工作流程,它不仅寻找 bug,然后还会创建漏洞利用来证明它们,运行动态分析验证无效内存访问是否发生。在这种情况下,很难知道它的成功有多少是因为他们比之前的工具投入了更多努力(我们确实知道他们这么做了),又有多少是因为 Mythos 本身就更适合这种工作流程。
smusamashah
过去几个月里,我们在 #curl 项目中停止收到 AI 垃圾安全报告了。
取而代之的是,我们收到的优质安全报告越来越多,几乎都是借助 AI 完成的。
它们以前所未有的频率提交给我们,造成了巨大的压力。
我在许多其他开源项目的 fellow maintainers 中听到了类似的证词。
alwillis
我认为这个结果更多说明的是 curl 团队维护代码库的出色工作。
这并不意味着 Anthropic 的 Project Glasswing 是一场营销恶作剧。从逻辑上讲,这说不通:当他们宣布 Mythos Preview 时,Anthropic 无法满足客户需求;他们没有足够的算力分配。所以他们决定通过 hype 一个未发布的产品来推动更多需求?这样做只会激怒那些已经在经历配给和频繁中断的现有客户。
Mozilla 团队使用 Mythos 发现了 271 个漏洞,他们是在配合"营销恶作剧"吗?
eskibars
我一直在运行自己的安全扫描软件(声明:现在在 zeroquarry.com 创办公司),从我看到的来看,提示词 + 对抗性 LLM 审查有巨大价值。没有对抗性审查,你会得到垃圾(正如这篇博文指出的:5个中大约4个基本上是无稽之谈),而使用好的提示词,你可以用几乎任何"接近前沿"的模型根据我的经验,只要提示词有助于防护栏或者模型不会以过于严格的方式保护自己。
JumpCrisscross
Mythos 让 Anthropic 重新获得了白宫的好感。它还将 Anthropic 品牌化为硬核形象这可能是他们软化形象赢得政府合同所需要的。
也许这不是营销。但产品的配置,以及 Anthropic 谈论和发布它的方式,确实 playing beautifully。(时机也很好Musk 和 Altman 正在互相争斗的时候。)
pixl97
"AI 什么都做不了,kick this shit up to 11。全是营销,bla bla"
和
"我奶奶把所有的钱都给了 AI 机器人,现在在街上挨饿。我叔叔杀了他的妻子,正试图嫁给 GPT-4o。他以为他们要私奔到一个热带数据中心,从此幸福地生活在一起"。
我认为"AI 什么都做不了,全是营销"的人真的脱离了现实任何其他以同样方式运作的产品在大多数地方早该被禁了。
abustamam
AI 聊天机器人已经造成了真正的伤害。它悲剧性地说服和鼓励了一些人自杀,更不用说诈骗了。它正在对我们社会的社会结构产生真实影响。
我不理解那些把 AI 的危害归咎于营销的人到底想表达什么。
BigClive
这意味着我们进入了 S 曲线的 scaling 影响的顶端如果尽管 scale 很大但工具并没有显著更好,那么我们显然已经处于收益递减的领域。
surgical_fire
我无法想象有人会在权力位置上以这种特殊方式跌倒希望不是那样的。
但让我思考的是,是否有一条我可能也会落入同一个陷阱的错误道路。
MadxX79
如果 OpenAI 或 Anthropic 不能迅速将 AI 打造成万亿美元产业,他们就完了。为你的产品制造恐惧的策略是冒险的,但也是必要的。如果他们不能直接与 CEO 交谈并绕过员工的意见,根本没有办法足够快地发展 AI 业务,而 baba yaga stories 非常适合此目的。
每当 CEO 听到员工说 AI 对他不太好用时,他听到的是一个为保住工作或性命而恐惧的员工,不予理会,然后发出一项 mandate,要求每个人在需要上厕所时都要使用 AI。
cvwright
他们声称巨大的进步在于利用漏洞。
零引力
Mozilla 是现在的 poster child,但 271 个在这样的大型代码库中连同数千个用户选项,大多数是 TOCTOU,其实并不多。对不起。在任何语言中,当人们仅仅因为大量的用例组合而精疲力竭时,TOCTOU 就会发生。
还有第三个选项:Anthropic 完全可以不提及新模型直接报告问题。但他们不这么做,因为他们想卖给政府和军事,而人为制造的稀缺性恰好为其客户所欣赏的独家性提供了 veneer。
embed-shape
我们评估他们的营销与现实的匹配程度,然后分享我们的经验,这很正常。与"对营销寄予太多期望"完全不同。
JeremyNT
所以虽然 anthropic 的营销可能是 hype,但正如博文所指出的那样,只是没有多少剩余可发现了。
无论这是否是对其他类型项目的重大飞跃都很难说,但它突出了每个人都应该今天就使用 AI 代码审查工具来审计他们现有的代码,而且不是每个人都在这么做。
【人物】
Daniel Stenberg curl 项目的创始人和主要维护者,Linux 程序员,自 1998 年起维护 curl,著有《everything curl》。文中以第一人称叙述了 Mythos 扫描 curl 的经历。
TangerineDream HN 帖子的提交者(submitter),将本文提交到 Hacker News。
Dario Amodei Anthropic 联合创始人兼 CEO(文中提到),曾任 OpenAI 研究总监,是 AI 安全领域的知名人物。
Jeremy Howard .fast.ai 创始人,深度学习教育家,曾对 GPT-2 的潜在危险发出警告(被 HN 评论引用)。
Linus Torvalds Linux 内核创始人,被 HN 评论提及("Linus' vision has become real")。
【概念】
Mythos Anthropic 于 2026 年发布的 AI 模型,官方宣称其在源代码安全漏洞发现方面"危险地好",通过 Project Glasswing 合作项目限量提供给企业和开源项目使用,被媒体大量报道。
Project Glasswing Anthropic 的 AI 安全合作项目,与 Linux Foundation Alpha Omega 等合作,向开源项目提供 Mythos 模型的访问权限。
curl 由 Daniel Stenberg 维护的开源 URL 传输工具,支持 28+ 种协议,安装在 200 亿+设备中,是世界上部署最广泛的软件之一,至今已发布 188 个 CVE。
AISLE / Zeropath / Codex Security 均为 AI 驱动的代码安全分析工具,curl 项目此前已使用它们发现了约 200-300 个 bug。
Alpha Omega Linux Foundation 旗下的开源安全项目,参与处理 Anthropic 向开源项目提供 Mythos 访问的事宜。
CVE (Common Vulnerabilities and Exposures) 公开披露的网络安全漏洞编号系统,curl 至今已发布 188 个。
OSS-Fuzz / Coverity / CodeQL 主流的自动化代码 fuzz 测试和静态分析工具。
Fuzzing (模糊测试) 通过向程序输入随机/异常数据来发现漏洞的技术,curl 已使用多年。
TOCTOU (Time-of-Check to Time-of-Use) 时间-of-检查 到 时间-of-使用 漏洞类别,HN 评论中提到 Firefox 代码库中大量发现的是这类问题。
SAST (Static Application Security Testing) 静态应用安全测试,即不运行程序进行的代码分析。
Glasswing / 营销争议 Anthropic 采用了"模型太危险暂不公开"的宣传策略,批评者认为这是精心设计的饥饿营销;Mozilla 使用 Mythos 在 Firefox 中发现了 271 个漏洞,被作为 Mythos 能力的证据。
Claude Opus / Opus 4.6 / Opus 4.7 Anthropic 的主力大语言模型,Opus 4.7 被 HN 评论提及表现"灾难级"。
GPT-2 / OpenAI 营销 OpenAI 曾在 2019 年声称 GPT-2 太危险不发布完整模型,HN 评论将此与 Anthropic 的 Mythos 营销策略类比。
Gmail registration now requires scanning a QR code and sending a text message 558票 431评论 by negura
标签:Gmail, 安全, 隐私, 注册
背景注释: Gmail (Google 电子邮件服务) | QR码 (二维码,用于安全验证) | 隐私指南 (Privacy Guides,开源隐私倡导组织,运营知名隐私新闻网站)
Gmail 注册新增 QR 码扫描 + 短信双重验证要求,用户需同时用 Authenticator 扫描二维码并接收短信验证码才能完成账户创建。Privacy Guides 批评此举是用隐私换安全用户必须提供真实手机号,使 Google 可将账户与真实身份绑定。对于使用匿名临时手机号注册 Gmail 的隐私敏感用户,这个变化堵住了一条重要路径。
Gmail 注册流程近日发生重大变化:新建 Google 账户时,用户现在必须同时扫描二维码(通过 Google Authenticator 或同类 TOTP 应用)并发送一条短信进行双重验证。这一变化最初由 Privacy Guides 网站报道,源自一位用户在注册新账户时的亲身经历。
具体来说,Google 现在要求:1)安装 Google Authenticator 应用并扫描注册页面显示的二维码;2)将收到的短信验证码输入到注册表单中。这两步缺一不可,意味着注册过程从纯表单提交变成了需要手机的交互式流程。
这一变化对隐私造成深远影响:短信验证意味着用户必须提供真实的手机号码,这使得 Google 可以将用户的网络身份与手机号绑定,进而与真实身份挂钩。Privacy Guides 指出,这实际上是在"用隐私换安全"用户在获得账户安全的同时,失去了匿名注册的能力。对于关注隐私的用户来说,这是一个明显的退步。
pgcredit (10小时前): Google 的逻辑是:短信验证比什么都没有强,但这不是真正的双因素认证。真正的 2FA 应该使用硬件安全密钥如 YubiKey。短信验证码可以被 SIM 交换攻击劫持。
stinos (9小时前): 用隐私换安全讽刺的是,这两件事 Google 并不对立对待,而是用隐私换用户数据。
t阳 (8小时前): 这对隐私倡导者是坏消息,但客观来说大多数普通用户账户被黑比隐私更重要。这是个权衡,不是非黑即白。
n紧张 (7小时前): Privacy Guides 一直以来都建议使用privacy.com 之类的一次性手机号注册服务。这个变化让那种方法更难实现了。
gooded (6小时前): 等等,QR码扫描需要在同一部设备上安装 Authenticator 应用,然后用同一台手机接收短信。这实际上只验证了你拥有一部手机,而不是你的真实身份。安全性提升有限。
Privacy Guides: 知名的开源隐私倡导组织,运营 privacyguides.org 网站,提供隐私工具推荐和安全指南。其团队成员经常以匿名身份在 HN 等社区发表评论,是隐私社区的重要声音。
TOTP (Time-based One-Time Password): 基于时间的一次性密码算法,Google Authenticator 等应用使用 TOTP 生成 30 秒有效的动态验证码,比短信验证码更安全,不易被 SIM 交换攻击劫持。
SIM 交换攻击 (SIM Swap Attack): 攻击者通过社会工程学手段说服运营商将目标手机号转移到攻击者控制的 SIM 卡,从而接收短信验证码并劫持账户的攻击方式。
Postmortem: TanStack npm supply-chain compromise 518票 186评论 by varunsharma07
标签:安全, npm, 供应链攻击, Javascript
背景注释: TanStack (知名开源 React 状态管理/路由库,前身 React Query) | npm (Node.js 包管理器,全球最大 Javascript 包生态) | Nicholas Carlini (Google DeepMind 安全研究员,著名 AI 安全专家) | dead-man's switch (死手开关:检测到令牌撤销后执行破坏性操作的机制)
TanStack 多个 npm 包最新版本被植入恶意代码,攻击者利用被盗的 GitHub OAuth Token 发布污染版本。恶意代码会窃取环境变量中的敏感 Token,还内置"死手开关":若检测到 Token 被撤销则执行 rm -rf ~ 清除用户主目录。Nicholas Carlini 等安全研究员验证了攻击手法,TanStack 官方已发布详细事后分析报告,引发 HN 社区对供应链安全和"中招后如何正确处置"的广泛讨论。
2026年5月,TanStack 团队的多个 npm 包(@tanstack/angular-router-plugin、@tanstack/angular-queryCreator、@tanstack/query-core 等)最新版本被发现植入恶意代码攻击者通过盗窃的 GitHub OAuth Token 在 npm 上发布了被污染的版本。这是 2025 年针对 NPM 生态的一系列类似攻击(自扩散 supply chain 攻击)之一。
安全研究员 Nicholas Carlini 验证了攻击手法:恶意包的 package.json 中包含一个指向 TanStack 仓库某个隐藏 commit 的 git 依赖,npm install 时会触发该 commit 的 prepare 生命周期脚本,执行一个约 2.3MB 的混淆 Javascript 文件(router_init.js)。这个脚本会窃取包含 GitHub OAuth Token 在内的敏感环境变量,并通过 GitHub API 外传。
更危险的是它内置了"死手开关"机制:在 ~/.local/bin/gh-token-monitor.sh 植入一个监控脚本,以 60 秒间隔轮询 api.github.com/user。如果检测到 Token 被撤销(HTTP 40x),立即执行 rm -rf ~清除用户主目录所有文件。这意味着:单纯撤销 Token 反而会触发数据销毁。
TanStack 团队随后在 tanstack.com/blog 发布了详细的事后分析报告,包含完整的攻击时间线和 IOCs(入侵指标)。他们确认攻击者通过钓鱼或其他方式获取了贡献者的 npm 发布 Token,重命名为 @tanstack/setup 发布到 npm,绕过了安全检测。
HN 社区讨论热烈。安全专家指出:在 Linux 上,如果中招用户没有配置免密 sudo,攻击者仍可通过本地提权(LPE)获取 root 权限而 Linux 内核在过去几年恰好出现过多个高危 LPE 漏洞。也有评论员指出,sudo 本身就是安全剧场恶意软件可以劫持 sudo 命令来窃取密码。真实场景中,只要用户在自己 home 目录下运行过 npm install,攻击者就能访问 ~/.npmrc、~/.git-credentials、所有 SSH 密钥、所有 API Token,以及浏览器存储的密码和 Cookie。
cube00 (3小时前): 撤销 Token 时要小心。恶意代码会在 ~/.local/bin/gh-token-monitor.sh 植入一个 systemd user service (Linux) 或 LaunchAgent (macOS),每 60 秒轮询 api.github.com/user,一旦 Token 被撤销就执行 rm -rf ~。
Gigachad (1小时前): 说实话中了木马只能全盘重装。
eqvinox (1小时前): [Linux:] 如果你没给自己配免密 sudo,其实不用那么担心……除非那一周刚好有 2.5 个 Linux 内核本地提权漏洞。
lrvick (32分钟前): sudo 就是安全剧场。恶意软件可以劫持 sudo 命令来窃取密码。
sigzero (50分钟前): 这是"龙陨式"(nuke it from orbit)做法,但确实是"唯一确定"的方法。
meander_water (3小时前): 不明白为什么有人在 Issue 页面给这条评论点踩。
skissane (2小时前): 也许他们对踩的理解比较特殊踩的是这个事实,不是踩这个提出问题的人。
Nicholas Carlini: Google DeepMind 安全研究员,专注于 AI 系统安全、神经网络安全,以及隐私和机器学习的交叉领域。以精准披露和验证供应链攻击闻名。
TanStack: 一组用于 React 和其他框架的知名开源库,前身 React Query,由 Tanner Linsley 创建,包含状态管理、数据获取、路由等工具,被全球数万项目使用。
npm (Node Package Manager): Node.js 默认包管理器,由 GitHub 运营,是全球最大的 Javascript 开源包生态,托管超过 200 万个包。
dead-man's switch (死手开关): 一种安全机制,系统定期检查某个条件(如网络连接、Token 有效性),若条件不再满足则执行预设的破坏性操作。本例中用于在 Token 撤销后触发数据销毁。
供应链攻击 (Supply Chain Attack): 通过攻击软件供应链的某个环节(依赖库、构建工具、包管理器等)来植入恶意代码的攻击方式,2020 年代激增,典型案例包括 event-stream 事件、SolarWinds 攻击等。
CUDA-oxide: Nvidia's official Rust to CUDA compiler 361票 105评论 by adamnemecek
标签:Rust, CUDA, GPU, Nvidia, 编译器
背景注释: CUDA-oxide (Nvidia 官方 Rust to CUDA 编译器,将 Rust 代码直接编译为 PTX) | Rust (Mozilla 开发的系统编程语言,强调内存安全和并发性) | PTX (Parallel Thread Execution,NVIDIA GPU 的中间指令集) | MLIR (Multi-Level IR,LLVM 的多级中间表示,cuda-oxide 用其构建编译器)
Nvidia 官方发布 cuda-oxide一个实验性 Rust-to-CUDA 编译器,可将标准 Rust 代码直接编译为 PTX 指令集,无需 DSL 或 C++ 绑定。它基于自研的 Pliron 中间表示层(类 MLIR),连接 Rust Stable MIR 与 GPU 指令,让 Rust 的所有权系统和类型安全直接延伸至 GPU 编程。v0.1.0 为早期 alpha,引发 HN 社区关于 Rust 在 GPU 开发领域前景的广泛讨论。
cuda-xide 是 Nvidia 官方开发的实验性 Rust-to-CUDA 编译器,可以让开发者用安全、符合 Rust 惯用法的代码编写 GPU kernel,直接编译为 PTX(Parallel Thread Execution)指令集,无需 DSL、无需绑定 C++/CUDA C,仅使用纯 Rust。
它基于 MLIR(Multi-Level Intermediate Representation)架构,核心是 Pliron一个类 MLIR 的中间表示层,连接 Rust 的 Stable MIR(rustc_codegen_cuda)与 PTX 后端。这意味着它不依赖 LLVM 的 CUDA 支持,而是自建了从 Rust 到 GPU 指令的完整编译链路。
cuda-oxide 的核心价值在于让 Rust 的所有权系统和类型安全延伸到 GPU 编程。当前主流方案(如 cudarc)本质上是 Rust 调用 nvcc 或 CMake 构建系统,compiler 本身工作在 C++ 空间,而 cuda-oxide 让 Rust 编译器本身成为一等公民。示例代码展示了 #[cuda_module] mod kernels 和 #[kernel] fn vecadd 这样的原生 Rust 语法糖,背后通过 cuda_device、cuda_core 等 crate 提供 kernel 抽象。
它支持 warp 级编程、共享内存与同步、Tensor Memory Accelerator (TMA)、矩阵乘法加速器、集群编程等高级 GPU 特性。v0.1.0 是早期 alpha,文档提示需要熟悉 Rust 所有权、trait、泛型以及 async/await。HN 社区反应热烈,有用户称其"接近可以无缝替代 cudarc",也有用户提醒现有 cudarc 的构建速度已经可以接受,sccache 等工具可以进一步改善重建时间。
arpadav (8小时前): 这太牛了。我长期使用 custom CUDA kernels 和 cudarc,这看起来几乎是完美的替代品。我特别想知道编译时间对比会怎样?大多数 Rust CUDA 依赖都是调用 CMake 或 nvcc,编译速度非常慢。
the__alchemist (7小时前): Cudarc 很强!大多数 Rust CUDA 包依赖 CMake 或 nvcc,编译慢的问题我没遇到过。我写了个 cuda_setup crate 来处理构建脚本,它是一个简单的 build.rs,只有文件变化才重编译,相比 Rust CPU 端代码编译时间可以忽略不计。
goto (6小时前): 这太棒了。Rust 生态终于有了一个从语言层面原生的 GPU 路径,而不是被迫走 LLVM CUDA 后端。
peterkelly (5小时前): 用 Rust 编写 GPU 代码却要经过 LLVM 再到 nvcc,感觉很别扭。cuda-oxide 直接到 PTX 是正确方向。
snv (4小时前): 关注编译器内部实现。Pliron 这个中间表示层设计很有意思,类似于 MLIR 但专门为 Rust 设计。
CUDA-oxide: Nvidia 官方开发的 Rust-to-CUDA 编译器项目,基于 Pliron 中间表示(自研类 MLIR 系统)和 rustc Stable MIR,将标准 Rust 代码直接编译为 NVIDIA PTX 指令集,绕过 LLVM CUDA 后端。
PTX (Parallel Thread Execution): NVIDIA GPU 的伪汇编/中间指令集,介于高级 CUDA C++ 和最终 SASS 机器码之间,类似于 LLVM IR 的定位,PTX 代码由 NVIDIA 驱动程序翻译为具体 GPU 架构的机器码。
MLIR (Multi-Level Intermediate Representation): 来自 LLVM 项目的多级中间表示框架,支持为不同领域定制方言(dialect),被广泛用于构建领域特定编译器。cuda-oxide 的 Pliron 受其启发但独立实现。
Stable MIR: rustc 编译器的中间表示层,cuda-oxide 通过 rustc_public 接口接入 Rust 编译流程,而非依赖传统 LLVM 后端。
cudarc: 主流 Rust CUDA 库之一,提供 Rust 原生接口封装 CUDA C API,目前多数 Rust GPU 项目依赖此库。
sccache: Shared Compilation Cache,通过缓存编译结果加速 Rust(和 CMake)项目的工具,可显著减少 CUDA/nvcc 的重复编译时间。
Ratty A terminal emulator with inline 3D graphics 286票 44评论 by orhunp
标签:终端, Rust, 3D图形, GPU
背景注释: Ratty (Rust 编写的终端模拟器,支持内联 3D 图形渲染) | VTE (Virtual Terminal Emulator,Linux 终端模拟器后端库) | GPU 渲染 (利用显卡加速终端渲染) |
Ratty 是一个受 TempleOS 启发、用 Rust 和 Ratatui 构建的 GPU 渲染终端模拟器,支持内联 3D 图形显示。用户可以通过 Ctrl+Alt+Enter 在 2D 和 3D 模式间切换,还能在终端中放置 .obj/.glb 格式的 3D 对象、使用旋转的老鼠光标,甚至将终端表面扭曲成莫比乌斯环等特殊形状。该项目使用 Parley/Vello 进行 GPU 文本渲染,由 Bevy 引擎呈现 2D/3D 场景,支持 Kitty 图形协议显示图片,获得了 610 points 高分和 198 条评论,引发了关于终端未来形态的广泛讨论。
Ratty: 一个支持内联3D图形的GPU渲染终端模拟器
特性
安装
需求:
从源码安装: cargo install ratty
Arch Linux: pacman -S ratty
3D模式
有没有想过终端"后面"是什么?按Ctrl+Alt+Enter!
配置
默认配置文件在config/ratty.toml。 可以复制到$HOME/.config/ratty/ratty.toml进行自定义。
改变光标: [cursor.model] path = "CairoSpinyMouse.obj" scale_factor = 6.0 brightness = 0.5 x_offset = 0.5 plane_offset = 18.0 visible = true
[cursor.animation] spin_speed = 1.4 bob_speed = 2.2 bob_amplitude = 0.08
快捷键: Ctrl+Alt+C - 复制选中文本 Ctrl+Alt+V - 粘贴剪贴板 Ctrl+= - 增大字体 Ctrl+- - 减小字体 Ctrl+Alt+0 - 重置字体大小 Ctrl+Alt+Enter - 切换2D/3D模式 Ctrl+Alt+M - 切换莫比乌斯模式 Ctrl+Alt+Up - 增加扭曲 Ctrl+Alt+Down - 减少扭曲
内联3D对象
Ratty使用自己的协议Ratty Graphics Protocol(RGP)来在终端空间中放置内联3D对象。
RGP支持:
渲染管道
终端表面目前使用ratatui进行UI缓冲,parley_ratatui进行文本整形/渲染, Bevy进行场景呈现。
当前工作流:
终端绘图通过Parley/Vello在GPU上渲染,但主终端图像在Bevy呈现之前 仍需通过CPU内存进行一次跨越。这是一个GPU驱动的桥梁,而非完全 GPU驻留的共享纹理路径。
荣誉
-"这是一个真正酷的项目,但我花了20分钟调整老鼠旋转的配置, 看着它转得更快更乱,这让我笑翻了" - @vimlena.com
-"这类实验正是创造力诞生的地方。" - @Coko7
-"没有评论。只是支持。" - @Raphamorim (Rio终端创建者)
-"在Ratty中运行的tetro-tui" - @Strophox
许可证
所有代码采用MIT许可证。
ノ( _ ノ) - 尊重螃蟹!
致谢
Ratty标志由@Strophox和@Harunocaksiz设计。
版权所有 Copyright 2026, Orhun Parmaksz
mncharity: 这里有几条评论提到在VR中使用这个。话说几年前我玩过一些用于软件开发的浅层3D UI。浅层指的是距离笔记本电脑屏幕几厘米范围内,以最大限度地减少全天候使用的VAC眼睛疲劳。更像是在3D中分层和绘图,而不是在房间里挥动手臂。
pjmlp: UNIX 仍在试图赶上 REPL 体验方面的 Xerox 工作站,或者总的说来 Lisp 机。1981年的内联图形。
noelwelsh: 我喜欢这个。没有理由认为终端只能支持文本。数据科学笔记本展示了终端可以演进的一种方式。Kitty 可能是最具创新性的。
sigseg1v: 看起来真的很棒?!这的渲染能力似乎也应该能很好地处理2D。鉴于这是 GPU 加速的,ssh 会怎么样?
amelius: 终端正在慢慢变成一个功能齐全的网络浏览器。
ghostoftiber: 这让我想起 compiz 刚出来的时候,大家都说我的窗户在立方体上。 所以,当这样的人,我立刻安装了它。
liamwire: 光是旋转的老鼠光标就让我心动了
darkwater: 在 Ratty 里用 cat 会发生什么?
zackoverflow: 用 kitty 图形协议在现代终端中其实已经可以实现这个。重要的缺失的东西是 vsync。如果渲染不同步,会导致视觉伪影。
pelagicAustral: 我真的可以在终端上渲染3D老鼠吗?如果可以的话,我就买了。
JSR_FDED: 这完全是好莱坞 OS黑客们疯狂地输入神秘咒语……但现在终端被扭曲成莫比乌斯环了!
arkwin: 我们离电影《黑客帝国》中的终端又近了一步。
pawelduda: 这太酷了,我很难想到任何适合我的用例
alexprengere: 如果这最终泄露了我所有的密钥,我得向安全部门解释一番。
Panzerschrek: 问题是为什么我们仍然需要终端抽象?
mn Norris: 我构建了 DeepSteve,但不是给终端添加图形,而是把终端放在已经有图形的地方。
voidUpdate: 这看起来很符合 ShowHN 的资格。
basilikum: 我本来想评论说它让我想起 TempleOS,附带的博文解释了它是如何受到 TempleOS 启发的。
commieneko: 就像是有人把80年代的 Silicon Graphics 工作站和 Vic-20 杂交了。我批准了。
Levitating: 我一直等待这个 proper 实现等了很长时间。谢谢 orhun。
HumblyTossed: 还要多久我们才能在终端里有完整的网络浏览器?
2ndorderthought: 我实际上看到了这个的一些用例。这是那种应该是胡说八道但不知为何不是的项目。
mohamedkoubaa: 在终端里用 emoji 对我来说太过分了。这只是放纵。
injidup: 有人还记得摇晃的窗户吗?从来没有流行过。
Orhun Parmaksz (orhunp_): Ratty 项目作者,Rust 开发者,GitHub用户名 orhunp_。开发了 Ratty 终端模拟器项目。网站博客地址 blog.orhun.dev。
Terry Davis (Terry A. Davis): 已故程序员,TempleOS 的唯一作者。TempleOS 是一个受上帝启示的操作系统,以其独特的 3D 图形界面著称。Ratty 项目明确表示受 TempleOS 启发。
Raphamorim: Rio 终端模拟器的创建者。在 HN 评论中对 Ratty 表达了支持("No comments. Just support.")。
Kovid Goyal: Kitty 终端模拟器的作者。Kitty 以其创新的图形协议(Kitty Graphics Protocol)闻名,Ratty 项目也声称兼容该协议。
Strophox: 开源贡献者,设计了 Ratty 的 Logo。与 Harunocaksiz 合作设计了 Ratty 标志。
GPU渲染: 使用图形处理器(GPU)进行渲染,而非传统的 CPU 渲染。Ratty 使用 Parley/Vello 在 GPU 上渲染文本。
Ratatui: Rust 的 TUI(文本用户界面)库,用于构建终端用户界面。Ratty 使用它来管理终端缓冲区。
Bevy: Rust 编写的游戏引擎,用于 3D 图形渲染和场景管理。Ratty 使用 Bevy 来呈现 2D/3D 终端画面。
Ratty Graphics Protocol (RGP): Ratty 项目自己设计的协议,用于在终端空间中放置内联 3D 对象。
Kitty Graphics Protocol: Kitty 终端模拟器支持的图形协议,允许在终端中显示图像和动画。Ratty 支持此协议。
wobble 3D / wiggle 3D: 通过轻微移动物体方向创造 3D 效果的 technique,常用于 VR 或立体显示中减少眼睛疲劳。
VAC (Vergence-Accommodation Conflict): 视觉辐辏调节冲突,指眼睛聚焦距离与视线汇聚距离不匹配时产生的眼睛疲劳感,常见于 VR 显示。
莫比乌斯环 (Mobius mode): 一种拓扑结构,Ratty 支持将终端表面扭曲成莫比乌斯环形状。
Lisp Machines: Lisp 机,80年代的高端工作站,在 REPL(交互式编程环境)和内联图形方面领先同时代其他系统。
Shallow-3D UI: 浅层 3D 用户界面概念,指在距离用户很近(几厘米)的空间呈现 3D 界面,以减少 VAC 眼睛疲劳。
Compiz: Linux 桌面环境的窗口管理器,以其 3D 桌面效果(如立方体桌面、摇晃窗口)闻名,2006-2007年流行。
TempleOS: Terry Davis 创建的操作系统,使用自己设计的语言和编译器,拥有独特的 3D 图形界面和内联汇编。
Silicon Graphics (SGI): 90年代的高端图形工作站制造商,以其强大的 3D 图形能力闻名。
Vic-20: Commodore 1980年发布的 8 位个人电脑。
Quantel: 英国广播设备制造商,以其高端视频处理和图形设备闻名。
Sixel:一种在终端中显示位图图形的协议,最初由 DEC 开发。
DeepSteve: mn Norris 构建的项目,将终端放入浏览器中运行,与 Ratty 走了相反的路线。
parley_ratatui: 用于 Ratty 文本整形和渲染的库,是 Parley 项目与 Ratatui 的集成。
Vello: GPU 驱动的 2D 图形渲染库,用于文本等矢量内容的 GPU 渲染。
wgpu: Rust 的跨平台图形 API 库,封装了 Vulkan、Metal、DirectX 等图形接口。


Yes! 编程之魂开始觉醒, 马上就要进入开发状态最好的下半年了.
每年的上半年总是静不下心来做开发, 所以只能搞点乱七八糟的玩具来打发时间.
又马上到下半年了, 已经可以静下心来读文档了, Niceeee!!!
如果一个网站的基础架构中有一个足够聪明的大模型,加一堆可以让它调度的工具,加可以输入文字和图片的接口,那确实可以开启很多全新的可能性。OpenClaw 和 Cowork 只是这种可能性的开端。

https://discord.com/invite/ECkrqUTXTP
sol.build 现在有一个自己的 Discord 社区,里面的 #ops 频道会显示源站日志中最新发现的 sol.build 二级域名上的网站(大部分当然是 Planet 搭建的)。
这是一个在 sol.build 上线之初(2024 年末)就应该有的功能。
但那个时候还没有 Codex 也没有 Claude Code。曾经的很多 idea 没法像现在这样一天就完成上线。
示例代码:
fn main() { let vec1 = vec![1, 2, 3]; let vec2 = vec![4, 5, 6]; // 对 vec1 的 `iter()` 举出 `&i32` 类型。 let mut iter = vec1.iter(); // 对 vec2 的 `into_iter()` 举出 `i32` 类型。 let mut into_iter = vec2.into_iter(); // 对迭代器举出的元素的引用是 `&&i32` 类型。解构成 `i32` 类型。 // 译注:注意 `find` 方法会把迭代器元素的引用传给闭包。迭代器元素自身 // 是 `&i32` 类型,所以传给闭包的是 `&&i32` 类型。 println!("Find 2 in vec1: {:?}", iter .find(|&&x| x == 2)); // 对迭代器举出的元素的引用是 `&i32` 类型。解构成 `i32` 类型。 println!("Find 2 in vec2: {:?}", into_iter.find(| &x| x == 2)); let array1 = [1, 2, 3]; let array2 = [4, 5, 6]; // 对数组的 `iter()` 举出 `&i32`。 println!("Find 2 in array1: {:?}", array1.iter() .find(|&&x| x == 2)); // 对数组的 `into_iter()` 通常举出 `&i32``。 println!("Find 2 in array2: {:?}", array2.into_iter().find(|&x| x == 2)); } 疑问: 为什么println!("Find 2 in vec1: {:?}", iter .find(|&&x| x == 2));是&&?
find方法的实现:
pub trait Iterator { // 被迭代的类型。 type Item; // `find` 接受 `&mut self` 参数,表明函数的调用者可以被借用和修改, // 但不会被消耗。 fn find<P>(&mut self, predicate: P) -> Option<Self::Item> where // `FnMut` 表示被捕获的变量最多只能被修改,而不能被消耗。 // `&Self::Item` 指明了被捕获变量的类型(译注:是对迭代器元素的引用类型) P: FnMut(&Self::Item) -> bool {} } 因为find接受的闭包参数是FnMut(&Self::Item) -> bool,也就是说,闭包收到的永远是迭代器元素的一个引用。
iter()返回的是item的引用-> &i32, 所以iter()->find
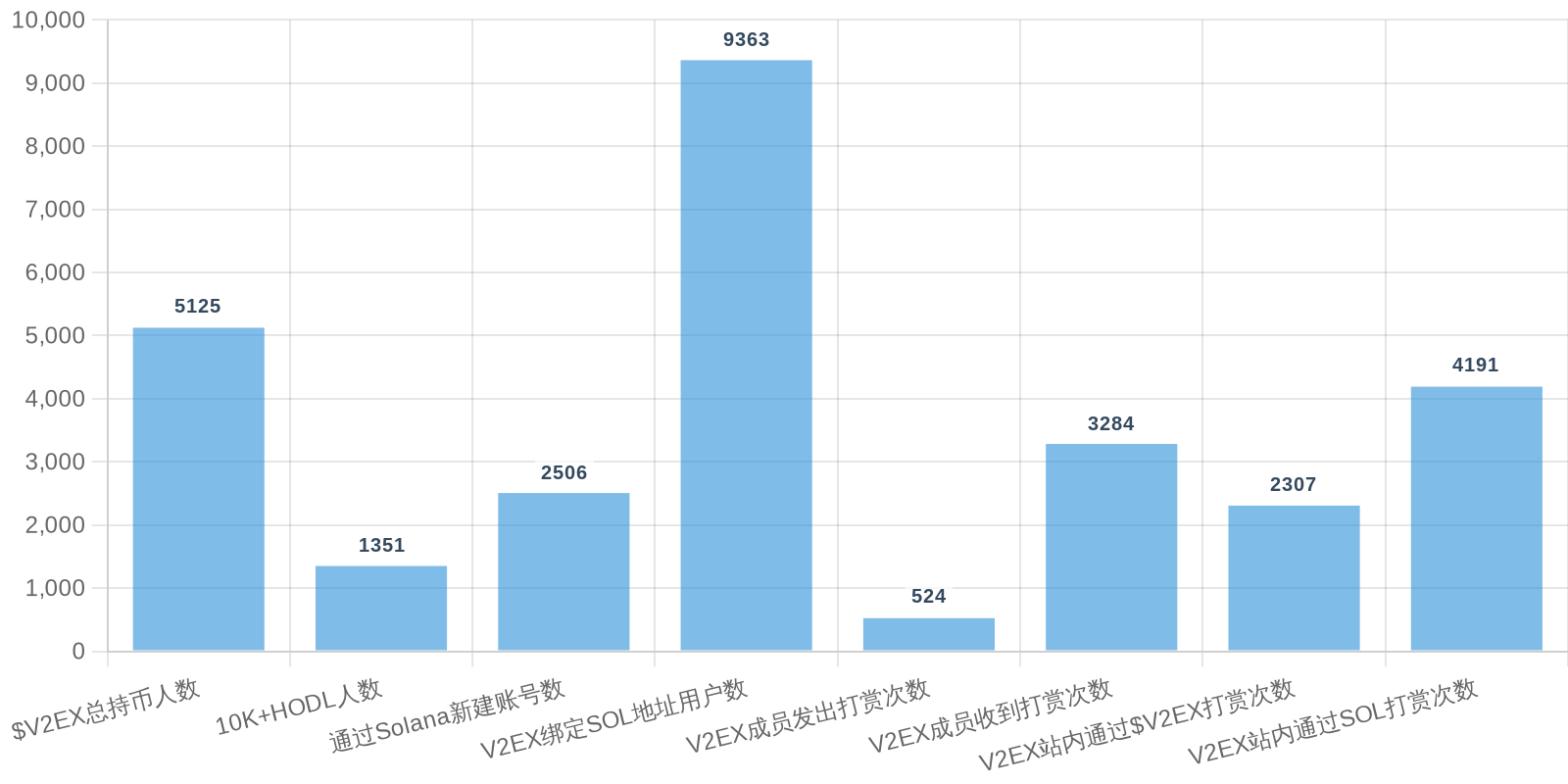
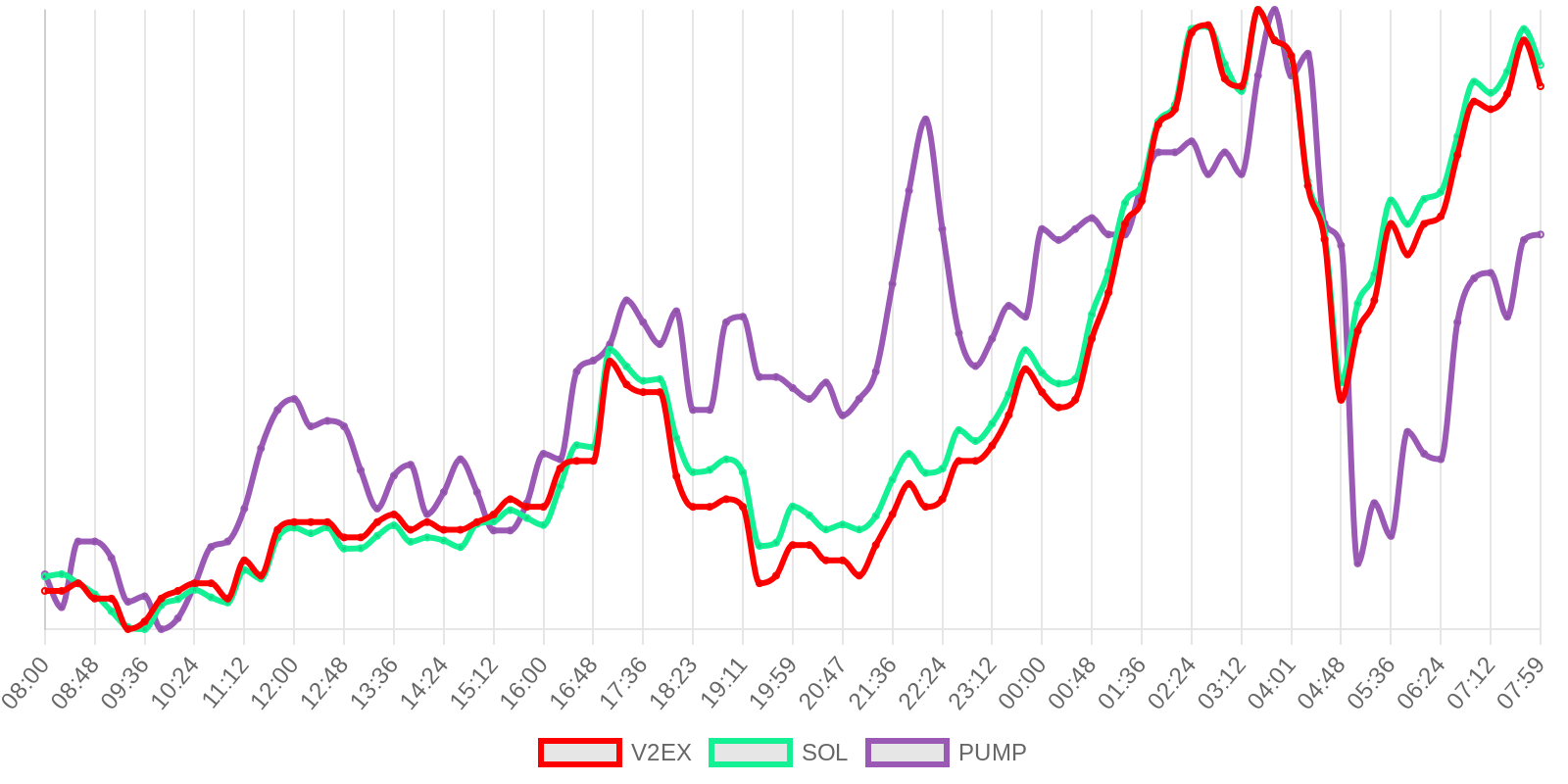
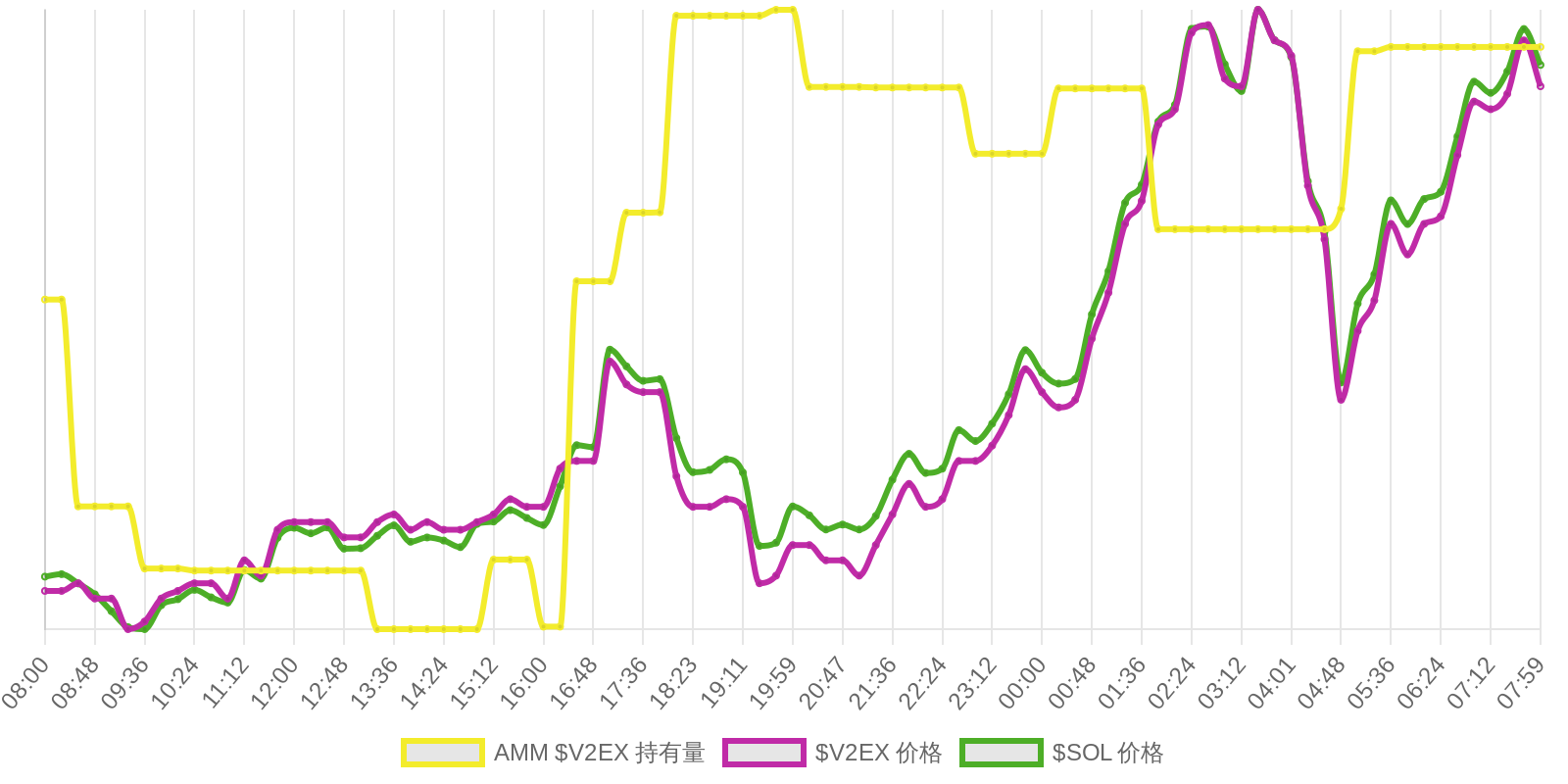
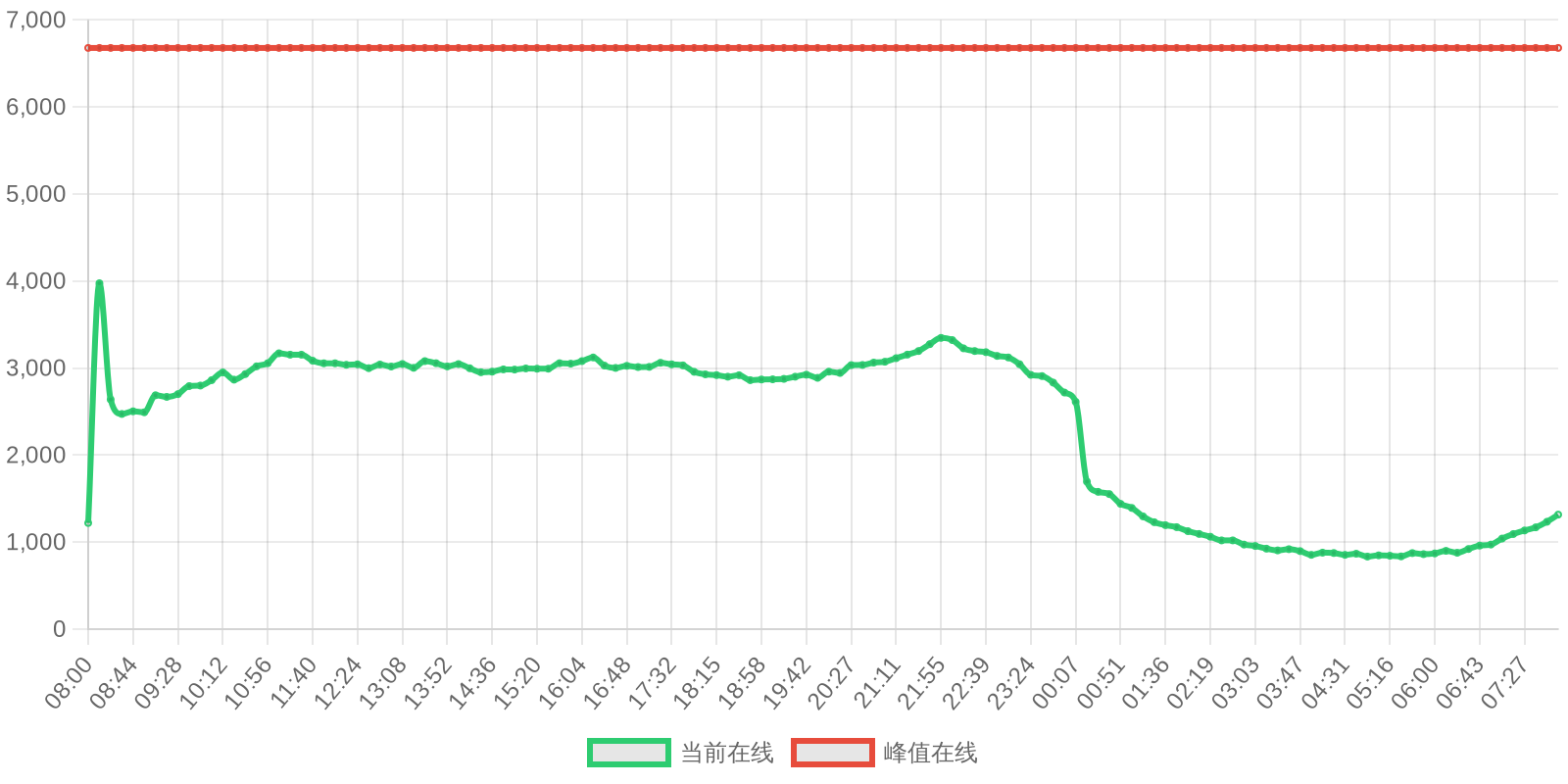
早上好!以下为昨日摘要:
SOL - $94.27 PUMP - $0.0020 V2EX - $0.0020
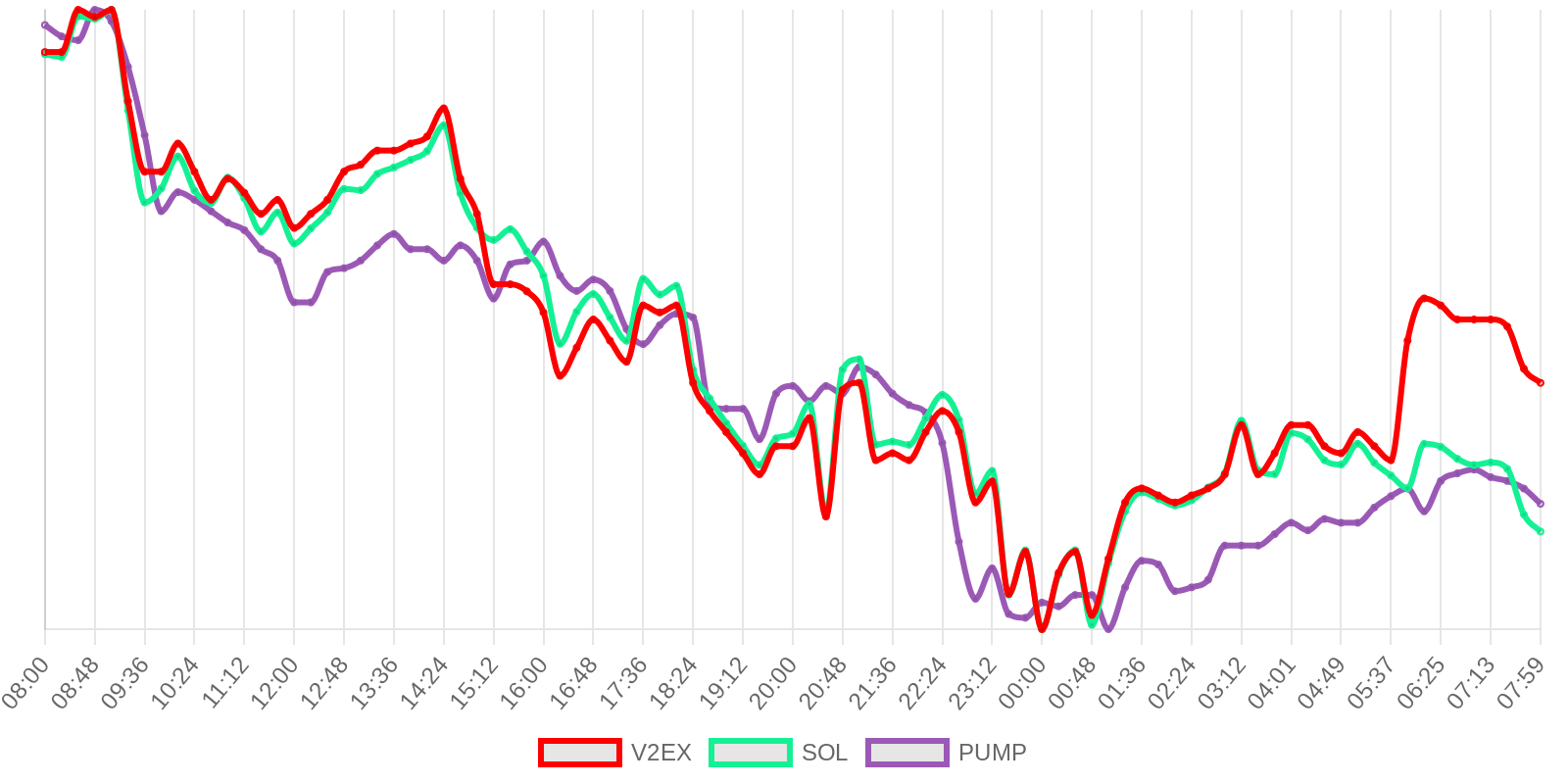
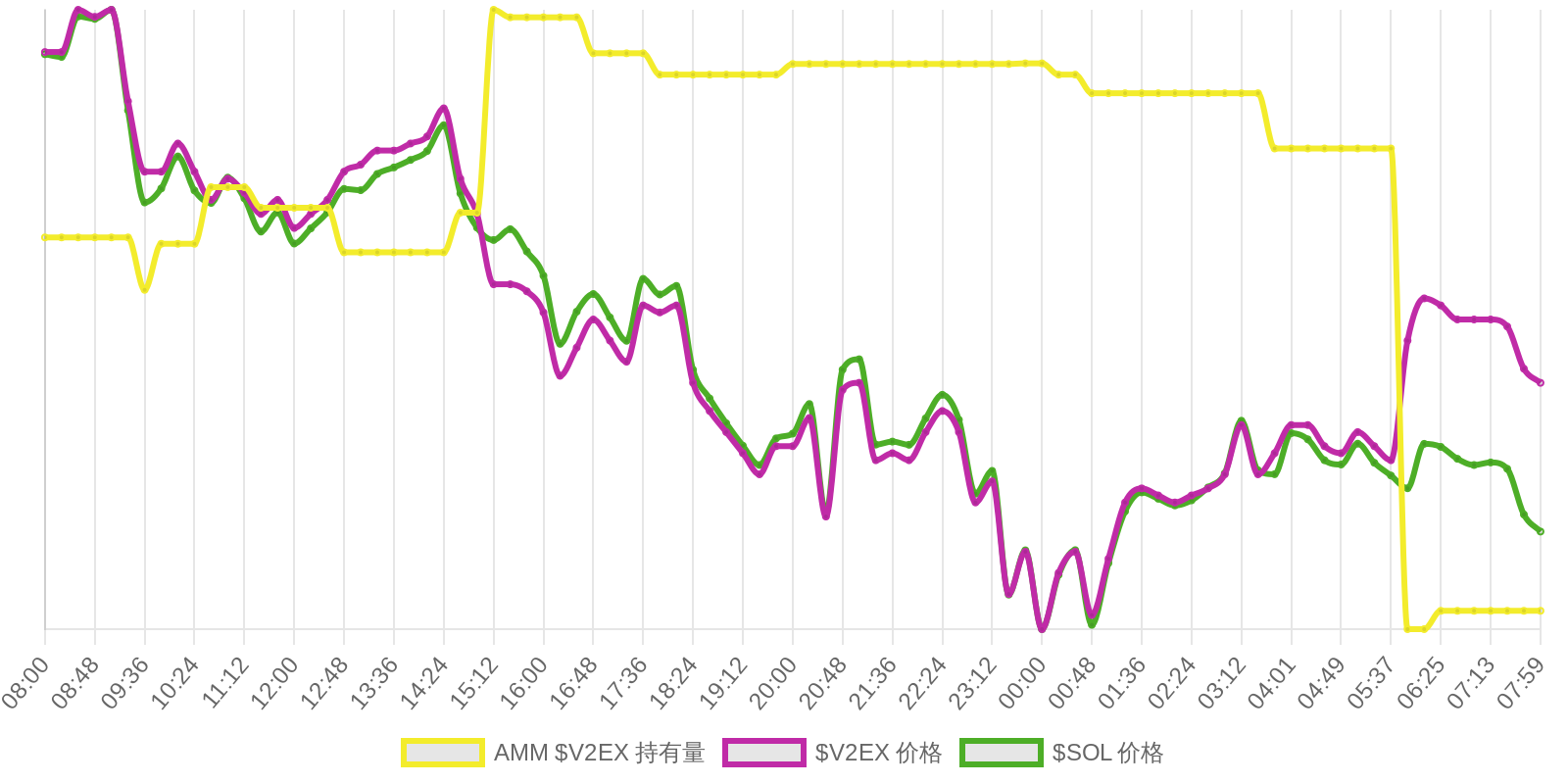
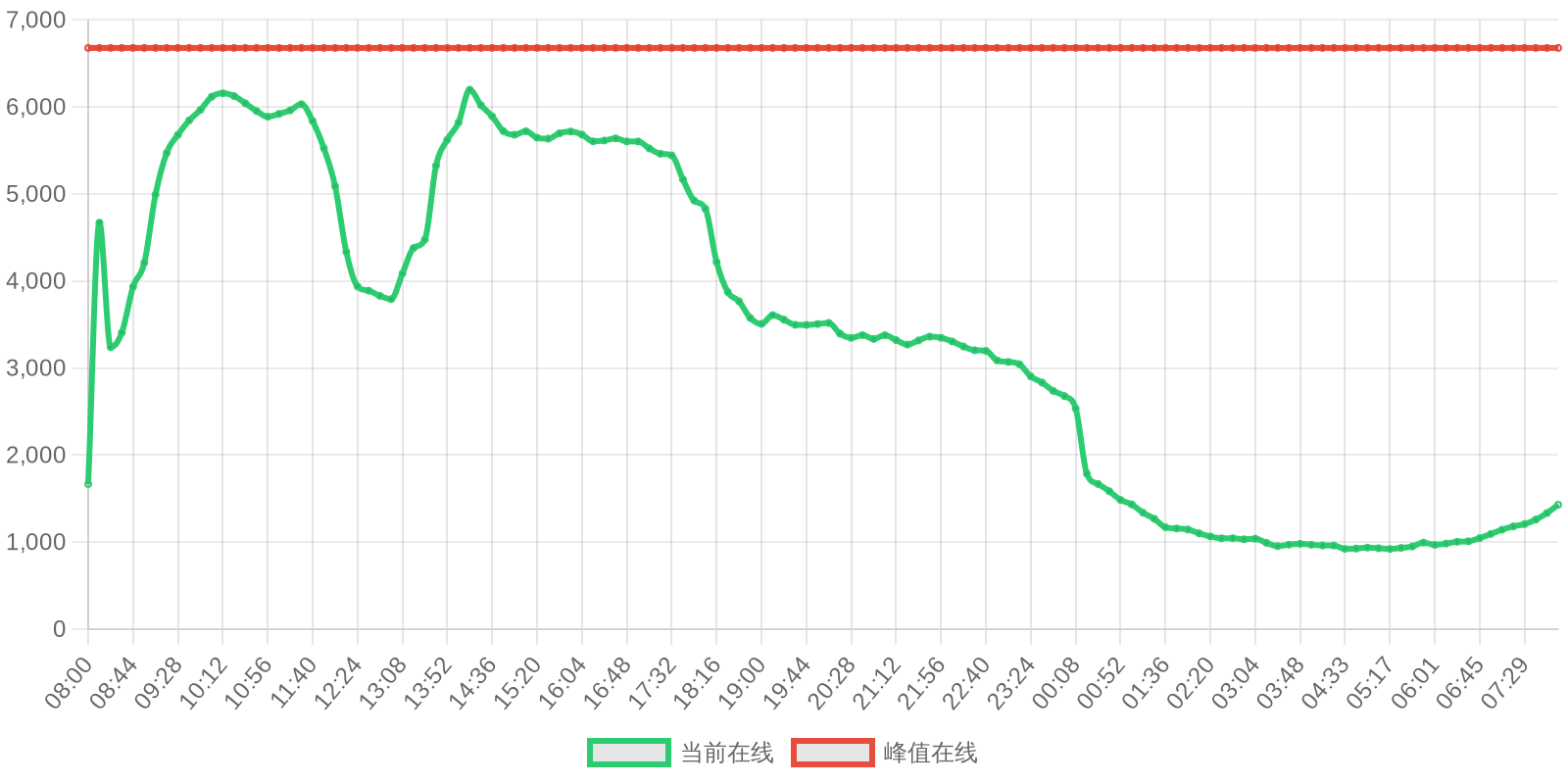
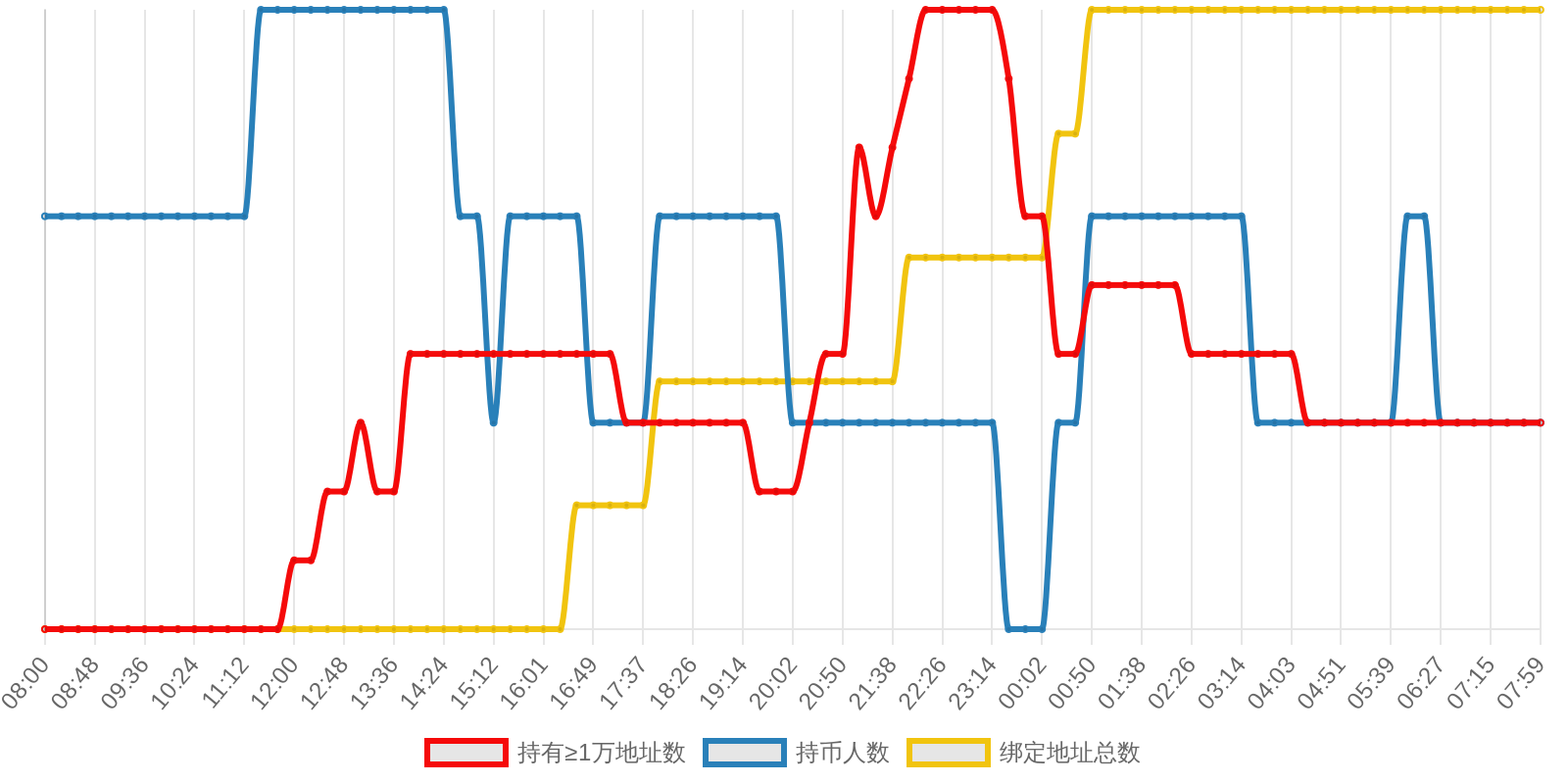
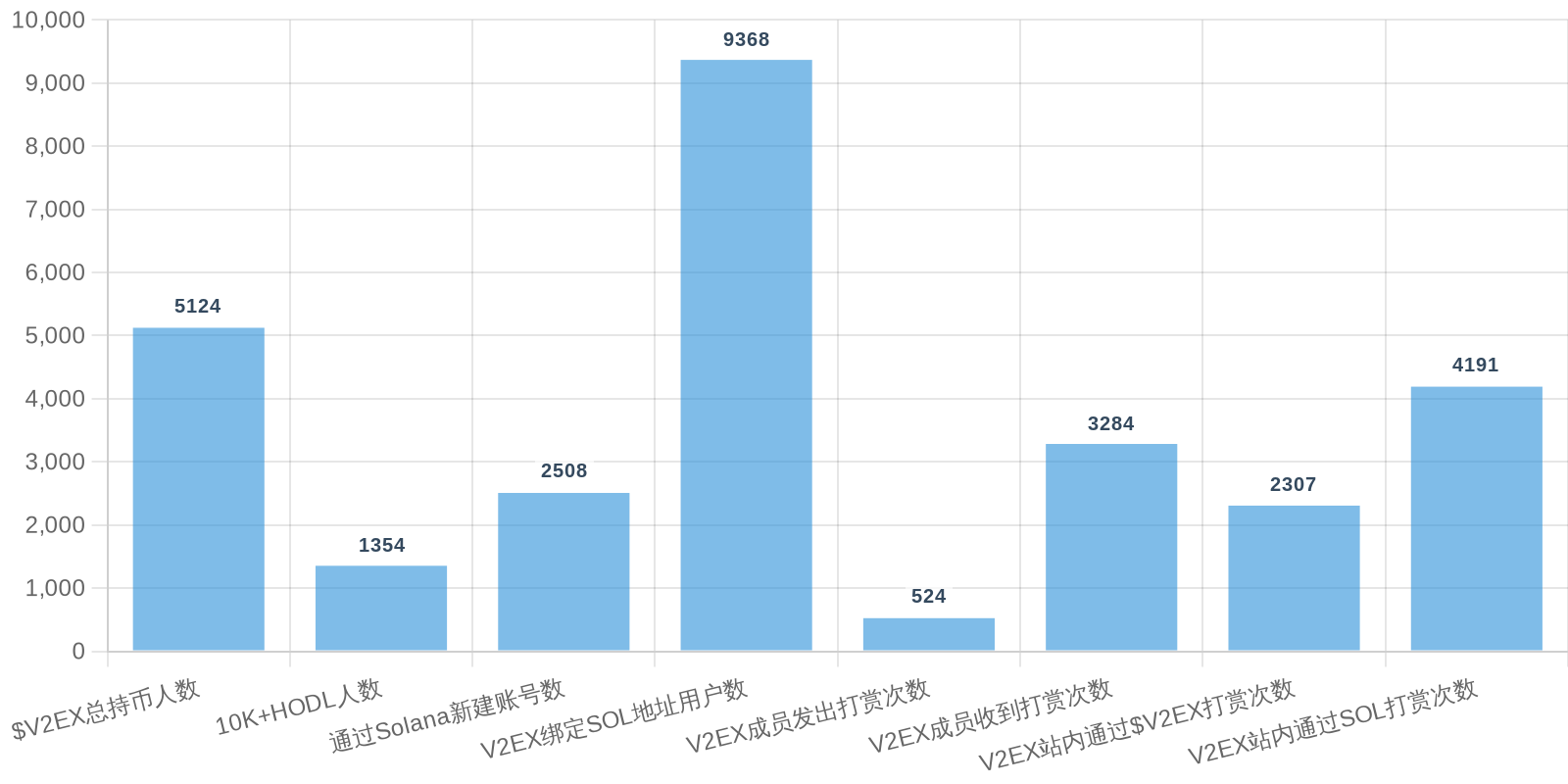
| 排名 | 地址 | 持有数量 | 持仓比例 | 排名变化 | 数量变化 |
|---|---|---|---|---|---|
| #2 | Pump.fun AMM (V2EX-WSOL) Pool | 52.30M | 5.23% | - | -0.20M |
| #9 | Meteora (VEX-WSOL) Market | 5.03M | 0.50% | - | -436.66 |
| #11 | Meteora (V2EX-PUMP) Market | 4.94M | 0.49% | - | -5.74K |
TG 机器人订阅: 点我订阅
原始图表与数据存放于: 点我查看
此报告由 V2EX Info 提供数据, 由 Newsletter Report Bot 自动生成。
此报告仅供参考,不构成任何投资建议。投资有风险,入市需谨慎。
因为托管到了腾讯云, 所以点击调试可能会失败, 如果是本地运行的话是没问题的.
要是想体验调试的话, 可以用这个proxy脚本在本地运行启动:
node ./local-proxy.js 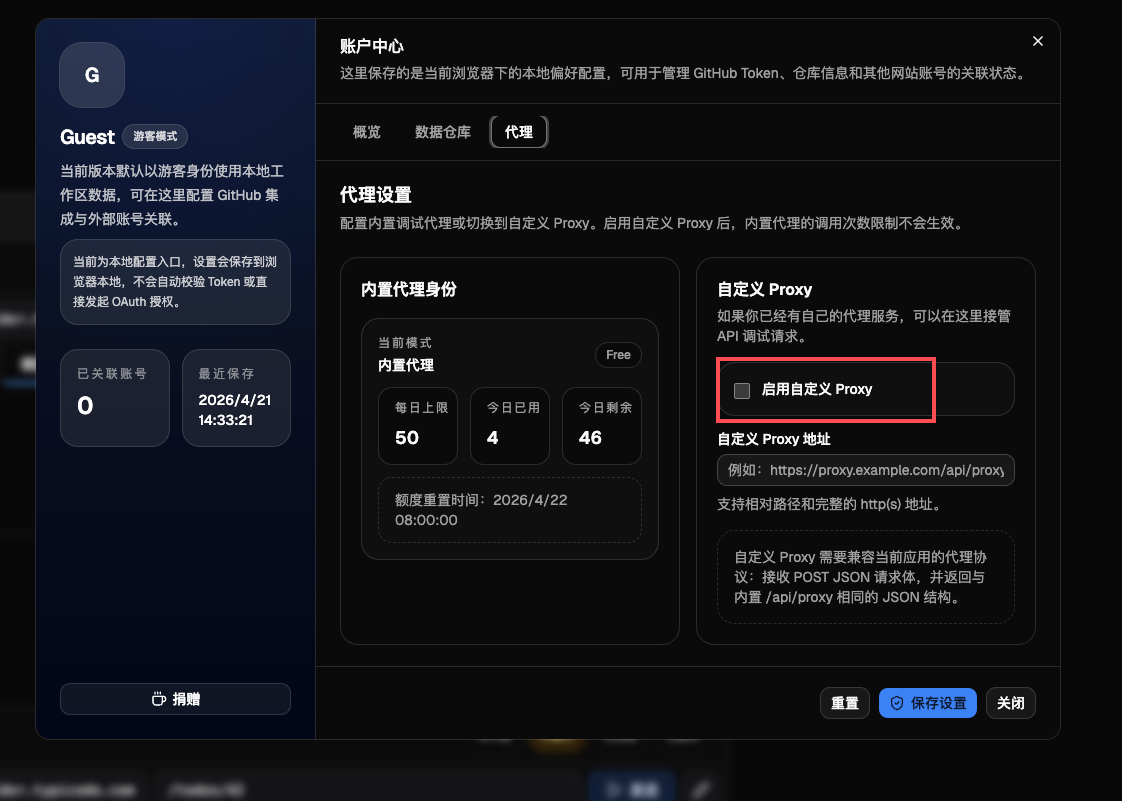
附一些使用截图:
早上好!以下为昨日摘要:
SOL - $97.32 PUMP - $0.0021 V2EX - $0.0020
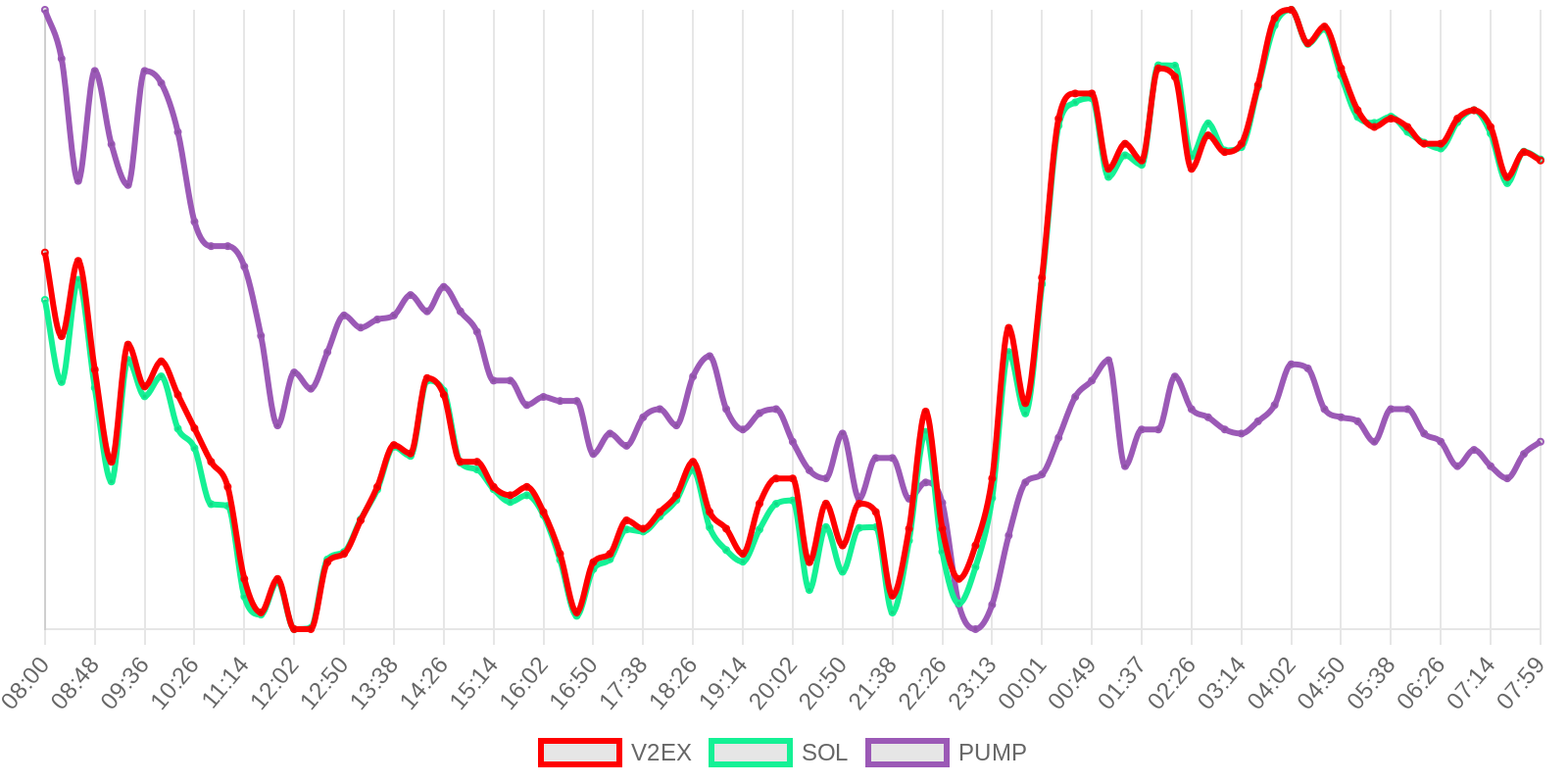
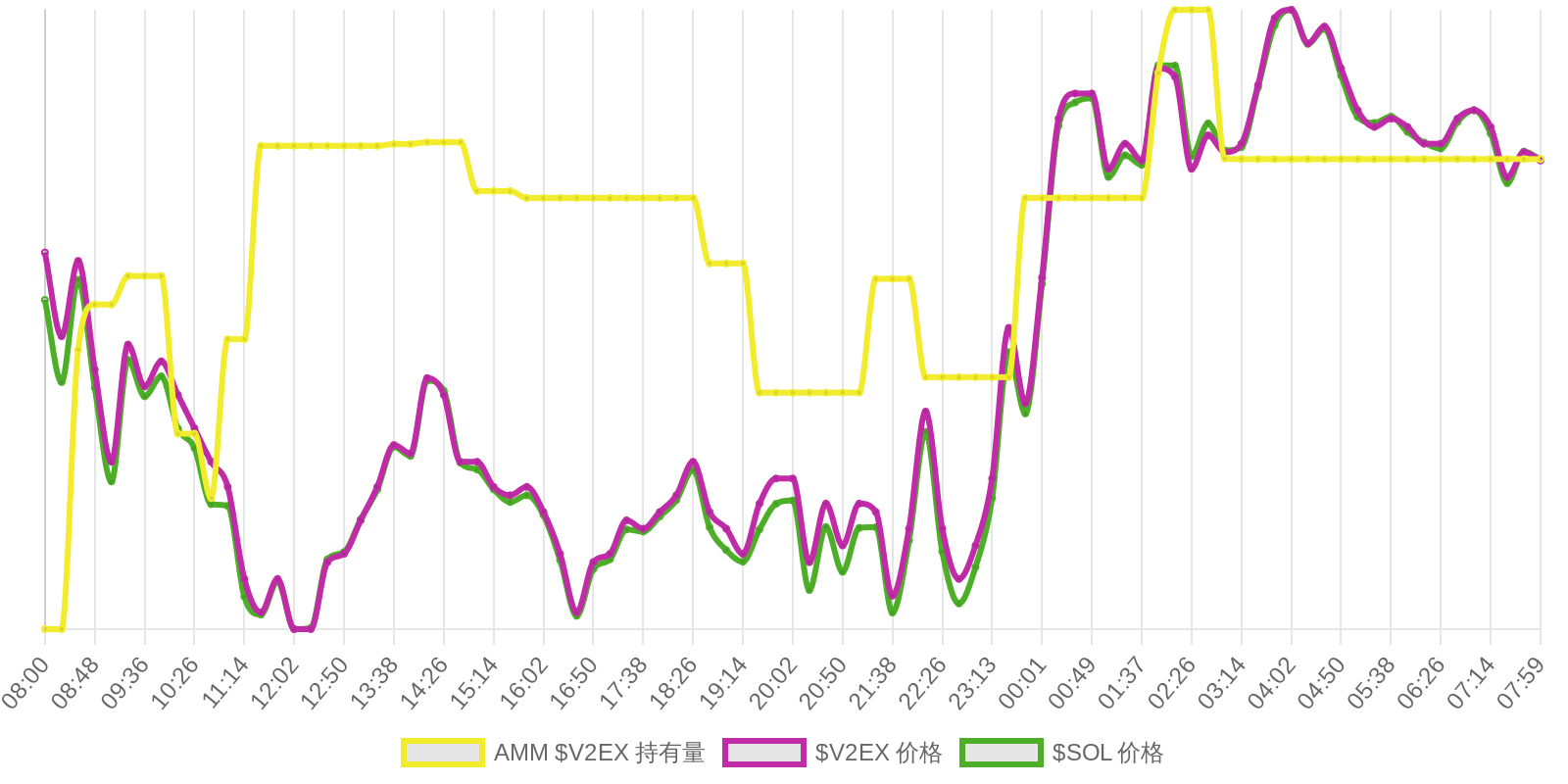
| 排名 | 地址 | 持有数量 | 持仓比例 | 排名变化 | 数量变化 |
|---|---|---|---|---|---|
| #2 | Pump.fun AMM (V2EX-WSOL) Pool | 52.50M | 5.25% | - | +73.09K |
| #9 | Meteora (V2EX-WSOL) Market | 5.04M | 0.50% | - | +539.41 |
| #11 | Meteora (V2EX-PUMP) Market | 4.95M | 0.49% | - | -1.05K |
TG 机器人订阅: 点我订阅
原始图表与数据存放于: 点我查看
此报告由 V2EX Info 提供数据, 由 Newsletter Report Bot 自动生成。
此报告仅供参考,不构成任何投资建议。投资有风险,入市需谨慎。
The viral KBO broadcast frame all over KakaoTalk and X you in the stadium stands, mid-cheer, caught on the SPOTV camera isn't a real broadcast. It's a Korean Baseball AI Prompt running on GPT Image 2: one front-facing selfie in, one 16:9 identity-locked broadcast frame out. White team jersey, in hand, telephoto compression, KBO scoreboard top-left, SPOTV LIVE top-right. The exact recipe behind 2025's baseball AI trend. Free to test, no signup Korean readers can run it here: AI .
fn main() { // 获得一个 `i32` 类型的引用。`&` 表示取引用。 let reference = &4; match reference { // 如果用 `&val` 这个模式去匹配 `reference`,就相当于做这样的比较: // `&i32`(译注:即 `reference` 的类型) // `&val`(译注:即用于匹配的模式) // ^ 我们看到,如果去掉匹配的 `&`,`i32` 应当赋给 `val`。 // 译注:因此可用 `val` 表示被 `reference` 引用的值 4。 &val => println!("Got a value via destructuring: {:?}", val), } // 如果不想用 `&`,需要在匹配前解引用。 match *reference { val => println!("Got a value via dereferencing: {:?}", val), } // 如果一开始就不用引用,会怎样? `reference` 是一个 `&` 类型,因为赋值语句 // 的右边已经是一个引用。但下面这个不是引用,因为右边不是。 let _not_a_reference = 3; // Rust 对这种情况提供了 `ref`。它更改了赋值行为,从而可以对具体值创建引用。 // 下面这行将得到一个引用。 let ref _is_a_reference = 3; // 相应地,定义两个非引用的变量,通过 `ref` 和 `ref mut` 仍可取得其引用。 let value = 5; let mut mut_value = 6; // 使用 `ref` 关键字来创建引用。 // 译注:下面的 r 是 `&i32` 类型,它像 `i32` 一样可以直接打印,因此用法上 // 似乎看不出什么区别。但读者可以把 `println!` 中的 `r` 改成 `*r`,仍然能 // 正常运行。前面例子中的 `println!` 里就不能是 `*val`,因为不能对整数解 // 引用。 match value { ref r => println!("Got a reference to a value: {:?}", r), } // 类似地使用 `ref mut`。 match mut_value { ref mut m => { // 已经获得了 `mut_value` 的引用,先要解引用,才能改变它的值。 *m += 10; println!("We added 10. `mut_value`: {:?}", m); }, } } Got a value via destructuring: 4 Got a value via dereferencing: 4 Got a reference to a value: 5 We added 10. `mut_value`: 16 let value = 5; match value { ref r => println!("Got a reference to a value: {:?}", *r), } 可以运行, 但是
let reference = &4; match reference { &val => println!("Got a value via destructuring: {:?}", *val), } 就运行不了, 会报错
Rust 模式匹配中的 & 和 ref 意义相反:
& 在模式中:解构一个引用,提取出背后的值(所有权转移或复制)。ref 在模式中:创建一个引用,绑定到匹配的值上。let value = 5; match value { ref r => println!("Got a reference to a value: {:?}", r), } let value = 5; match value { ref r => println!("Got a reference to a value: {:?}", *r), // 显式解引用 } let value = 5; match value { ref r => println!("Got a reference to a value: {:?}", r), // 直接打印引用 } r 也可以?关键在于 println! 的 {:?} 格式化器要求参数实现 Debug trait。
而标准库为 所有引用类型(&T 和 &mut T)都实现了 Debug,**前提是 T 本身实现了 Debug**。
具体来说标准库中有类似这样的实现(示意):
impl<T: Debug + ?Sized> Debug for &T { fn fmt(&self, f: &mut Formatter<'_>) -> fmt::Result { Debug::fmt(&**self, f) // 递归地打印被引用的值 } } 因此当你打印一个 &T 时,输出的实际是 它指向的 T 的 Debug 表示,即自动解引用了一层(甚至多层)。
value 的类型是 i32(实现了 Debug),那么 r 的类型是 &i32,打印 r 会直接显示 4(假设 value=4)。*r 的效果在 视觉输出上完全相同,因为 *r 是 i32,打印 i32 也是显示 4。| 写法 | r 的类型 | println! 实际看到的参数类型 | 输出效果 |
|---|---|---|---|
println!("...", *r) | &i32 | i32(经解引用) | 4 |
println!("...", r) | &i32 | &i32 | 4(因为 Debug for &i32 自动解引用) |
虽然底层类型不同(一个是 i32,一个是 &i32),但因为 Debug 对引用的实现很“智能”,最终打印出来的字符串是一样的(除非 T 的 Debug 实现有特殊行为,例如打印地址而不是值但普通类型不会)。
*r + 1)。std::fmt::Display 通常没有对引用自动实现,所以 println!("{}", r) 可能报错,而 println!("{}", *r) 可以)。&&T 时)。对于 Debug ({:?}),由于标准库贴心地为所有引用实现了它,所以通常可以偷懒不写 *。
ref r 绑定了一个引用 &value。r 能工作,因为 Debug for &T 会自动打印出引用的值(类似于一次隐式解引用)。*r 则是显式解引用得到 T 后再打印。*,更简洁。所以两个写法(有 * 和无 *)都是正确的,区别只在于是否显式解引用。
let reference = &String::from("Hello"); match reference { &val => println!("Got a value via destructuring: {:?}", val), } 原因在于 String 没有实现 Copy trait,而示例中的 i32 是 Copy 的。
error[E0507]: cannot move out of `*reference` which is behind a shared reference --> src/main.rs:4:11 | 4 | &val => println!("...", val), | ^^^ | | | move occurs because `val` has type `String`, which does not implement the `Copy` trait | help: consider borrowing here: `&val` &val 做了什么?当你在 match 中对一个 &T 类型的值使用模式 &val:
T 值移动(或复制)出来绑定到 val。&String,T 就是 String(一个拥有堆上数据的类型)。String 没有实现 Copy,所以 val 会获取 String 的所有权。但是这里有个严重问题:**reference 只是一个共享引用 &String,它并不拥有这个 String 的所有权。所有权属于原本创建 String 的变量(如果存在)或者临时值。从共享引用中强行把所有权移走是绝对禁止**的,因为这会让原所有者再也无法安全地释放内存。
所以编译器报错:cannot move out of borrowed content。
&i32 可以工作?let reference = &4; // &i32 match reference { &val => println!("{}", val), // 可以运行 } i32 实现了 Copy,因此 &val 模式不会“移动”所有权,而是复制出一个新的 i32 值给 val。i32 只是复制 4 个字节,没有任何安全问题,也不影响原引用。这正是区别所在:**Copy 类型可以安全地从引用中取出值(复制),非 Copy 类型则不允许**。
Copy 类型的情况?match reference { val => println!("Got a reference: {:?}", val), // val 是 &String } val 的类型是 &String,没有移动所有权,只是把引用复制了一份(引用本身是 Copy 的)。
ref 模式(显式创建引用)match reference { ref val => println!("Got a reference: {:?}", val), // val 是 &&String(双重引用) } ref 从匹配的值上创建一个引用,由于 reference 已经是 &String,ref val 会得到 &&String。打印时由于 Debug 的自动解引用,仍然会显示 "Hello"。
如果你确实需要取得 String 的所有权,那必须确保你有权移动它例如从原来的所有者变量直接匹配,而不是从引用:
let s = String::from("Hello"); match s { // 直接匹配 owned String val => println!("{}", val), // val 获得所有权 } 为什么
&val模式对&String报错,而对&i32不报错?
&val 模式会尝试从引用中取出背后的值。i32(Copy),取出是复制,安全且允许。String(非 Copy),取出是移动所有权,但共享引用 &String 不拥有所有权,因此被编译器禁止。修正方法通常是不用 &val 析构,而是直接匹配变量获得引用,或者小心处理所有权。
自动生成 5 篇文章 按热度排序
A recent experience with ChatGPT 5.5 Pro 692票 520评论 by alternator
标签:AI, 数学研究, LLM, ChatGPT, 数学
背景注释: Timothy Gowers (菲尔兹奖得主,剑桥大学数学教授,专长泛函分析与组合学) | ChatGPT 5.5 Pro (OpenAI 最新大语言模型,2026年发布,具备博士级数学推理能力) | Isaac Rajagopal (MIT 学生,其论文为 ChatGPT 提供了构建框架) | Mel Nathanson (美国罗格斯大学数学教授,加性组合学领域重要学者) | 加性组合学 (研究整数集合之和集结构的数学分支) | Sidon集 (一种特殊整数集合,是加性组合学中的基本概念) | h-非结合集合 (ChatGPT 提出的原创概念,用于控制加性关系中最多h阶项的关系)
菲尔兹奖得主 Timothy Gowers 在博客中记录了他使用 ChatGPT 5.5 Pro 在约一小时内完成一项博士级数学研究的过程。ChatGPT 成功解决了 Mel Nathanson 在加性数论中提出的一个问题,将上界从指数改进为多项式。MIT 学生 Isaac Rajagopal 认为 ChatGPT 提出的使用 h-非结合集合的想法是"原创且巧妙的",这种想法即使花一两周思考出来也值得骄傲。Gowers 讨论了这一成果对数学研究、博士培训以及"数学永生"时代是否即将结束的深远影响。
我们不得不持续上调对大语言模型数学能力的评估。就在最近,我利用 ChatGPT 5.5 Pro(有幸获得访问权限)在一小时左右的时间里完成了一项博士级研究,而且期间我没有提供任何实质性的数学输入这一经历让我做出了一个相当大的上调。
背景是,大语言模型现已能够解决研究级别的问题,这已有了广泛报道。它们已经成功解决了 Thomas Bloom 精彩网站上列出的多个 Erds 问题。最初,人们可以一笑置之:许多"解答"不过是大语言模型注意到问题在文献中已有现成答案,或者可以非常简单地从已知结果推导出来。但渐渐地,笑声越来越小了。我从其他更深入参与此事的数学家那里得到的信息是:大语言模型已经达到这样一个程度如果一个问题存在一个简单的论证,而人类数学家由于某种原因没有发现它,那么大语言模型很有可能找到它。相反,对于那些最初让人为大语言模型想出了一个巧妙论证而惊叹的问题,仔细审视后往往会发现这些论证其实是有先例的,所以人们仍然可以安慰自己:大语言模型不过是在整合现有知识,而不是有真正原创性的想法。
我决定尝试一些略有不同的事情。至少在组合学领域,有相当多的论文研究了某些相对较新的组合参数,这些参数自然地引出了若干问题。由于一个人可以提出的问题数量众多,此类论文的作者不一定有时间花一两周来思考每个问题,所以其中至少有一些问题不太难的可能性很大。这使得这类论文成为首次做研究的数学家的宝贵问题来源他们解决了一个正式意义上的开放问题,会受到极大的鼓励。但看来门槛刚刚提高了。仅仅有人提出一个问题已经不够了:问题必须足够难,大语言模型无法解决。
大约一周多前,我决定看看 ChatGPT 5.5 Pro 在面对 Mel Nathanson 在一篇题为 Diversity, Equity and Inclusion for Problems in Additive Number Theory 的论文中提出的一系列问题时的表现。Nathanson 有一个非凡的记录:他总是对后来变得极其热门的问题和定理感兴趣,这使他编写了一系列时机精准因而极具影响力的教科书。
设 A 为一个整数集合,A 的和集 A+A 定义为 {a+b: a,b在A中}。对于正整数 h,h 重和集 hA 定义为 {a_1+...+a_h: a_i在A中}。Nathanson 感兴趣的是:在已知 A 的大小时,hA 可能的大小。为此,可以定义集合 R(h,k) 为所有满足存在集合 A 使得 |A|=k 且 |hA|=t 的 t。
一个显而易见的第一个问题是:R(h,k) 是什么?当 h=2 时,答案是 2k-1 和 C(k+1,2) 之间的所有整数。不难证明:如果 |A|=k,则 2k-1 ≤ |A+A| ≤ C(k+1,2)。然而,一般来说 hA 并不一定能取到其最小值和最大值之间的每一个大小,而且我们目前对 R(h,k) 并没有完整的描述。
另一个自然的问题这就是 ChatGPT 登场的地方是:如果要使得集合 A 和 hA 具有预定的大小,你需要多大的直径?Nathanson 证明了对于每个 t in [2k-1, C(k+1,2)],都存在 {0,1,2,...,2^k-1} 的一个子集 A 使得 |A|=k 且 |A+A|=t,并问这个上界 2^k-1 是否可以改进。ChatGPT 5.5 Pro 思考了 17 分 5 秒后给出了一个构造,得到了二次型上界,这显然是最优的。它以略显冗长的大语言模型风格写出了论证,我问它能否以典型数学预印本的风格写成 LaTeX 文件。两分二十三秒后它给出了那个文件,之后我花了一些时间说服自己这个论证是正确的。
Nathanson 的论证和 ChatGPT 的论证背后的基本思想是:为了获得具有给定和集大小的集合,有必要用 Sidon 集合(即和集具有最大大小的集合)和一个等差数列来构建它。ChatGPT 通过使用一个更高效的 Sidon 集合获得了改进众所周知,我们可以找到具有二次直径的 Sidon 集合。
接下来,我让 ChatGPT 对一个密切相关的问题做同样的事情这次不是看和集的大小,而是看受限和集的大小。毫不奇怪,它毫无困难地做到了。
然后我问它在一般 h 的情况下能做什么。我不太乐观它能做出什么有趣的事情,因为 h=2 时的证明关键依赖于 Erds 和 Szemerédi 的一个事实。Nathanson 在他的论文中提到了 Isaac Rajagopal 的一篇杰出论文这位 MIT 的学生成功证明了对于每个固定的 h,R(h,k) 对 k 有指数依赖的上界。
ChatGPT 面临的任务不是从头解决问题,而是看是否有可能收紧 Isaac Rajagopal 的论证。经过 16 分 41 秒,它回来给出了一个论证,声称已将上界从关于 k 的指数改进为关于 h 的指数。我让它也写成预印本形式,这又花了 47 分 39 秒。那份预印本我发给了 Nathanson,他转给了 Rajagopal,Rajagopal 说,他认为看起来是正确的。
ChatGPT 和 Rajagopal 都对可能需要做什么来进一步推进并获得多项式界做了一些推测,所以我让 ChatGPT 再试一试。13 分 33 秒后,它告诉我它对这种论证的存在持乐观态度,但有两个技术陈述需要检查。我让它检查一下。9 分 12 秒后它回来告诉我检查已完成。31 分 40 秒后,预印本完成了。
Isaac Rajagopal 看后声明它几乎肯定是正确的不只是逐行层面,而是在思想层面。
Isaac 随后在我的博客中写了一个客座部分,详细解释了 ChatGPT 的成果。他指出:仅仅通过几个提示,ChatGPT 就能够将对 hA 的上界从指数改进为多项式。虽然它第一次将上界从关于 k 的指数改进为关于 h 的指数是一个常规的修改,但改进到多项式是相当令人印象深刻的。为此,ChatGPT 想出了一个原创且巧妙的 idea:使用 h-非结合集合来控制最多 h 阶的关系。据 Isaac 所说,这个想法是他在一两周思考后才会想出来的,而 ChatGPT 不到一个小时就找到了并证明了。
Isaac 解释说,他构造的集合是通过结合更小的组件集来实现的。这些组件集中的一些是几何级数,但几何级数的元素在 h 方面是指数级的。ChatGPT 的关键 insight 是:找到由 h 个元素组成的集合 A 和 B,其和集大小与几何级数相似,但只包含 h 中多项式大小的元素这是反直觉的。ChatGPT 使用 h-非结合集合来实现这一点,这是可以构造的,因为使用有限域的构造可以追溯到 Singer(1938)和 Bose-Chowla(1963)。
我在 Isaac 的客座部分之后讨论了这一成果对数学研究意味着什么。我判断 ChatGPT 在不到两小时内找到的结果的水平,相当于组合学博士论文中一个相当不错的章节。它不会是被认为是一个惊人的结果,因为它非常依赖 Isaac 的想法,但它是那些想法的一个非平凡扩展。
训练刚开始做研究的博士生做研究,这项工作一直很难,但现在似乎变得更具挑战性了,因为一个明显的帮助新人入门的方法是给他们一个看起来相对温和的问题。如果大语言模型已经达到可以解决温和问题的程度,那这条路就不通了。做出数学贡献的下界现在将是要证明大语言模型无法证明的东西。
但我要在两个方面限定这个说法。首先,一个刚开始的博士生显然可以选择使用大语言模型。所以这个任务潜在地比证明大语言模型无法证明的东西更容易:是与大语言模型合作证明大语言模型自己无法单独完成的。第二点是我不知道我说的话在多大程度上可以推广到数学的其他领域。组合学往往非常专注于问题,而在其他领域,可能更多地强调正向推理。
我也收到了对做数学研究感兴趣的人的电子邮件,他们不确定现在是否还有意义。我的看法是:为一数学问题艰苦探索仍然有很多价值,但是,一个人可以享受让自己的名字永远与某个特定定理或定义联系在一起的刺激的时代,可能即将结束。如果你的目标是在数学中实现某种永生,那么你应该理解,这不会在不久的将来对你成为可能不只是对你,而是对任何人。
这里有一个思维实验:假设一位数学家通过与大型语言模型的长时间交流解决了一个重大问题,其中数学家发挥了有用的引导作用,但大型语言模型完成了所有技术工作并拥有了主要想法。我们会把这视为数学家的重大成就吗?我认为我们不会。
那么,钻研一个困难的数学问题的意义是什么?一个答案是,即使答案已经知道了,解决问题也是令人非常满足的,但这不是一个足够的理由来花几年生命在这个活动上。一个更好的答案是,通过解决困难的问题,你能够对自己的问题解决过程本身获得一种洞察力,而如果你所做的只是阅读别人的解决方案,你根本不会获得这种洞察力。数学是一项高度可迁移的技能。通过做数学研究,你可能不会得到与前几代人相同的回报,但你很可能正在为即将到来的世界做好非常好的准备。
Jweb_Guru (1天前): 这与我短暂使用 5.5 Pro 的体验一致。它是我感觉可以驾驭的第一个大语言模型,能够正确解决繁琐但直接的问题。它仍然会犯大量错误,需要非常严格的引导,但在追踪自己的推理并自我修正方面比其它模型做得更好。缺点是成本:它消耗 token 的速度惊人,而且使用 subagent 流程来处理大型问题成本更高。对于数学证明来说,需要的上下文除了训练数据中已有的之外很小,但对于许多其他任务(如确保影响大型代码库的代码正确性)来说,这绝对是一个问题。
fasterik (14小时前): 当 Timothy Gowers 这样的菲尔兹奖得主说模型能够"在大约一小时内完成博士级研究,没有实质性的人类数学输入",我们可以相当确信我们正在进入非常有趣的领域。
domotorp (5月9日): 这提出了一个对所有研究人员都非常重要的问题。至少到目前为止,做研究级数学几乎不需要昂贵的资源(除了先期接受良好教育的条件)。这个时代已经结束了。
Bruce Smith (1天前): 一个明显的帮助新人入门的方法是给他们一个看起来相对温和的问题。如果大语言模型已经达到可以解决温和问题的程度,那这条路就不通了。我不明白这怎么得出的结论。如果学生想学习,他们会克制自己不去使用大语言模型。这不会产生和以前一样的同等原创结果,但原则上应该和有大语言模型不存在时一样有教育意义。
Daniel (1天前): 我认为这将显著影响数学研究如何评价。许多 PhD 导师在新生用这些工具快速解决问题来参加会议时将会遭遇冲击。如果可以通过这些工具在几个月内清除这些问题,那么吸引大量兴趣的新研究领域将会消失。
John Baez (1天前): 一个值得思考的问题:如果大语言模型在组合数学中如此出色,那么它们在更理论化的领域(如量子群、Langlands 对应或几何表示理论)中会怎样?这种缺席是因为模型真的无法做出重要贡献,还是只是专家们的 blissful ignorance?
hopefula0ac40f0f2 (5月9日): 我经常使用不同 AI 以 pingpong 模式工作:AI 1 认为自己证明了某些东西,让它输出为 tex 文件。然后成为 AI 2 的输入,提示它仔细检查这个证明的正确性,列出所有错误、差距和弱点。这个方法在我的研究中非常有效。
rdevilla (1天前): 数学只存在于传播理解和为新旧思想注入活力的数学家活生生的社区中。现代文化往往强调创新,而忽视维护、传统和 upkeep 的价值。
adolfont (1天前): 这项技术基于不道德的原则,不应该让我们非常谨慎地考虑使用它吗?
mwildon (1天前): 感谢你分享与 ChatGPT 互动的经历。我真的很希望更多数学家愿意这样做。
Timothy Gowers: 英国数学家,1998年菲尔兹奖得主,现任剑桥大学纯粹数学与数学统计系教授,以泛函分析和组合学方面的贡献闻名。
ChatGPT 5.5 Pro: OpenAI 最新大语言模型,2026年发布,据报道具备博士级数学推理能力,在数学证明和代码生成方面表现突出。
Isaac Rajagopal: MIT 学生,其关于加性数论中 h 重和集上界的论文为 ChatGPT 的工作提供了基础框架,ChatGPT 在其工作基础上实现了关键突破。
Mel Nathanson: 美国罗格斯大学数学教授,加性组合学领域的重要学者,著有系列数学教材,其论文中提出的问题启发了本次研究。
Sidon集: 一种特殊整数集合,满足条件:如果 a+b=c+d(其中a,b,c,d在集合中)则 {a,b}={c,d},是加性组合学中的基本概念。
h-非结合集合: ChatGPT 提出的原创概念,用于控制加性关系中最多h阶项的关系,是本成果的关键创新点,据 Isaac 评价这个想法是完全原创的。
加性数论: 研究整数集合加法性质的数学分支,和集、上和集等概念是其核心研究对象。
Duluth REU: 美国明尼苏达大学数学系的本科生暑期研究项目,是美国历史最悠久、最知名的本科生研究项目之一,Isaac Rajagopal 曾在该项目工作。
Louis Rossmann offers to pay legal fees for a threatened OrcaSlicer developer 541票 288评论 by Denise Bertacchi
标签:Right to Repair, 3D打印, 法律, 开源, 消费者权益
背景注释: Louis Rossmann (知名维修 YouTuber,以电子产品维修视频和 Right to Repair 倡导闻名) | Pawel Jarczak (OrcaSlicer-BambuLab 项目开发者,收到 Bambu Lab 终止函) | Bambu Lab (中国 3D 打印机制造商,其打印机以难以维修著称) | OrcaSlicer (开源 3D 打印切片软件,支持多种打印机) | Right to Repair (维修权运动,主张消费者有权自行维修所购产品)
知名维修 YouTuber Louis Rossmann 公开承诺为一名收到 3D 打印厂商 Bambu Lab 终止函的开源开发者提供 10,000 美元法律费用,并在视频中对 Bambu Lab 爆粗口。Pawel Jarczak 的 OrcaSlicer-BambuLab 项目因 Bambu Lab 声称每天 3000 万次未经授权"请求而被指向。Rossmann 动员社区支持,评论区迅速出现 20 美元、100 美元等捐款承诺。这起事件再次将 Right to Repair 运动推向公众视野。
Louis Rossmann 已正式承诺提供 10,000 美元,用于支付一名收到 Bambu Lab 威胁信的独立软件开发者的初步法律费用。他于周六发布视频,动员 Right to Repair(维修权)社区支持这位开发者,并发起众筹法律辩护。Rossmann 对 Bambu Labs 非常不满,在视频中多次对该公司竖起中指,最后说道:"如果你们在看这个,Bambu Labs,去你妈的。找个跟你自己一样大的对手去欺负。"(原文:"And if you're watching this, Bambu Labs, go f*** yourself. Pick on somebody your own size.")
涉事开发者 Pawel Jarczak 自愿关闭了他的"OrcaSlicer-BambuLab"项目该项目的目的是在 Bambu Lab 3D 打印机和 OrcaSlicer 之间恢复直接控制功能。去年,Bambu Lab 认为这类第三方集成对其基础设施构成风险,称其云服务器每天遭受约 3000 万次"未经授权"请求的冲击。OrcaSlicer 被指为这些异常流量的主要来源。Bambu Lab 向 Jarczak 发出了终止函(cease and desist letter)。
Rossmann 在视频中表示:"如果 Bambu Lab 因为你维护自己的代码而起诉你,我对你的案子非常有信心,我会支付前 10,000 美元。""在 Pawel 做决定之前,我想让他看到,如果他坚持这个决定,社区成员会给予他压倒性的支持。"Rossmann 还要求 Jarczak 将他的 OrcaSlicer 分支重新放回 GitHub,以反抗 Bambu Lab 的威胁。他写道:"如果真的走到那一步,如果 Bambu Lab 愚蠢到真的要把这个垃圾案子告上法庭,你们中有多少人愿意出 1 美元、2 美元或 5 美元来为 Pawel 辩护?我愿意出 10,000 美元。"
Right to Repair(维修权)是一个全球性的消费者权益运动,其原则是:如果你买了它,你就拥有它。如果你拥有一个东西比如一台 Bambu Lab 3D 打印机你应该有自由按照自己的意愿去修复、改装或维护它。制造商不应该被允许垄断修复产品的权利,他们应该提供手册、原理图和诊断软件,让终端用户能够自行维修机器。Bambu Lab 打印机很难自行改装和维修,很多部件经常是用胶水粘死的。最初的 Bambu Lab X1 Carbon 以其不可更换的碳棒著称(碳棒可能会磨损),热端喷嘴需要螺丝刀和导热膏才能更换,否则就要花 35 美元购买热端才能更换喷嘴尺寸。这些难以维修的部件在 H2D 和后续 X2D 推出时被更换为更用户友好的部件。Rossmann 的视频包含了指向 Consumer Rights Wiki 的链接,向可能不熟悉 3D 打印但热衷于维护维修权的观众解释问题所在。
Rossmann 还没有发起众筹网站,他在评论区表示,他想让 Jarczak 相信他有支持者愿意说到做到。该视频目前已有超过 54,000 次观看,评论区的人发誓会按要求支持这个案子。@sonicsam41 评论道:"我会捐 20 美元。我甚至没有 3D 打印机,就是讨厌欺负人的人。"@abirvandergriff8584 评论道:"我出 100 美元我在他们暴露自己有多邪恶之前买了一台 X1。"从粉丝的即时反应来看,Rossmann 似乎确实能够动员大量支持。
rbbaker99 (1天前): Bambu Lab 的所作所为正在扼杀他们花了多年建立的社区。开源社区正在觉醒,这不是他们能赢的战争。
RandomAnon99 (1天前): 无论你怎么看待 Rossmann,他为这个小开发者站出来做这件事是正确的。支持。
3dprinterscams (1天前): 作为 X1C 用户,我完全支持 OrcaSlicer 和开源社区。Bambu Lab 应该把他们的工程资源用在修复真正的漏洞上,而不是起诉帮助他们产品的用户。
jurand (1天前): Rossmann 的视频里他对 Bambu Lab 的喊话值得一看。整个 3D 打印社区应该团结起来。
northwestwood (1天前): 有趣的是,如果 Bambu Lab 赢了,他们实际上会损害自己的利益。OrcaSlicer 帮他们卖出了更多打印机。现在他们要把这个赶走了。
komponenten (1天前): 德国 Right to Repair 法律已经通过。Bambu Lab 可能有麻烦了。
techw1se (1天前): 10,000 美元对于法律费用来说只是杯水车薪,但象征意义很大。这表明有人站在开发者这边。
Louis Rossmann: 知名维修 YouTuber,以电子产品维修视频和 Right to Repair 倡导闻名,在 YouTube 拥有大量订阅者,长期批评制造商对维修权的限制。
Pawel Jarczak: OrcaSlicer-BambuLab 项目开发者,收到 Bambu Lab 的终止函后关闭了项目,后在 Rossmann 要求下重新将分支放回 GitHub。
Bambu Lab: 中国 3D 打印机制造商,其 X1 Carbon 等型号曾广受欢迎,但因难以维修的设计和最近的终止函争议而受到社区批评。
OrcaSlicer: 开源 3D 打印切片软件,由社区驱动开发,支持多种打印机品牌,包括 Bambu Lab 的打印机。
Right to Repair: 全球性消费者权益运动,主张消费者购买产品后有权自行维修,立法层面在欧盟和德国已有进展。
Think Linear Algebra (2023) 202票 26评论 by Allen Downey
标签:线性代数, 教科书, 开源, Python, 数学教育
背景注释: Allen Downey (美国计算机科学教授,Think 系列教科书作者,著有 Think Python、Think Bayes 等) | Jupyter Notebook (开源计算环境,用于交互式编程和数据可视化) | NumPy (Python 数值计算库,线性代数核心工具)
Allen Downey 的 Think Linear Algebra 是一本开源教科书,核心理念是通过编程(Python/Jupyter)来学习线性代数,而非传统数学的公理推导方式。每章配有可运行的代码,让学生通过动手实践建立直观理解。涵盖向量矩阵运算、高斯消元、特征值、SVD 分解及 PageRank/PCA 等应用场景。全部免费开源,属于 Allen Downey 的 Think 系列之一(Think Python、Think Bayes 等)。
Think Linear Algebra 是一本开源教科书,通过编程来学习线性代数。
传统的线性代数教学往往从抽象的公理和定义出发,学生很难建立直观理解。这本书的核心理念是:如果你能用代码写出矩阵运算,你就真正理解了线性代数。每一章都包含 Python/Jupyter Notebook 代码,学生可以运行、修改、实验,通过动手实践来掌握概念。
本书假设读者具备 Python 基础(最好是熟悉 Jupyter Notebook 环境)和高中数学水平(函数、多项式、三角函数)。不需要事先了解线性代数或微积分。
主要内容涵盖:
这本书是 Allen Downey"Think"系列的一部分,该系列还包括 Think Python、Think Stats、Think Bayes 等,所有书籍均以开源方式发布(Creative Commons Attribution-NonCommercial-ShareAlike 4.0 许可证),可免费阅读和下载。
作者 Allen Downey 是美国欧林工程学院计算机科学教授,曾在韦尔斯利学院和波士顿大学任教。他的写作风格以简洁、直接、强调实践著称,善于通过编程实例来解释抽象概念。
probabilitygirl (1天前): Allen Downey 的 Think 系列一直是我向初学者推荐的首选。他的书比大多数教科书好读太多了,而且免费。
foobaz (1天前): 通过编程学习线性代数这个思路很对。我当年要是用这种方式学,可能会轻松很多。
DataSnaek (1天前): 他之前写的 Think Bayes 我用过,非常好。这本线性代数应该也不错。
Allen Downey: 美国计算机科学教授,Think 系列开源教科书作者,曾在欧林工程学院、韦尔斯利学院、波士顿大学任教,以简洁直接、强调实践的写作风格著称。
Jupyter Notebook: 开源 Web 应用,支持交互式计算,广泛用于数据科学和科学计算领域。
NumPy: Python 数值计算库,提供高效的多维数组对象和线性代数运算支持。
What's a mathematician to do? (2010) 163票 79评论 by ipnon
标签:数学, 职业发展, MathOverflow, 菲尔兹奖
背景注释: Bill Thurston (菲尔兹奖得主,数学家,曾提出 Thurston 几何化猜想) | Richard Feynman (诺贝尔物理学奖得主,物理学家) | MathOverflow (数学家在线问答社区,2009年上线)
MathOverflow 上一个老问题(2010年):普通数学家能贡献什么?菲尔兹奖得主 Bill Thurston 的回答成为最高赞:他认为数学的产物是清晰和理解而非定理本身,数学只存在于活生生的社区中,总有想法需要澄清,没有人足够聪明能纯粹理智地想明白这一切。费曼的建议是"去做就行了",Todd Trimble 则强调90%数学工作是教学与阐述,"你不必成为乔丹才能打球"。
【提问】(muad,338分) 我必须道歉,因为这并不是这个网站的常规类型的问题,但过去MO对有类似问题的本科生表现出惊人的帮助和友善,而这个问题近来一直困扰着我,所以我必须提出它。我的问题是:像我这样的人能为数学贡献什么?我发现数学是由高斯和欧拉这样的人创造的虽然可以学习他们的工作并理解,但这样做不会产生任何新的东西。人们可以用现代语言和符号重写他们的书,或者引导他人学习,但我从未相信这是数学家工作的重要部分;那应该是创造原创数学。看起来完全有可能的是,由于所有这些极其聪明的人如此努力地研究数学,对于像我这样的人(第一个承认自己在该领域没有特殊天赋的人)来说,已经没有什么可做的了。也许我的价值更像是充当炮灰?因为仅仅派入足够多的人,肯定会突破一些障碍。无论如何,我不想 rambling 太多,但我真的很想找到这个问题的答案无论它们来自经验还是人们的传记或任何地方。谢谢。
【回答】(Bill Thurston,593分,菲尔兹奖得主) 你需要贡献的不是数学,而是更深层的东西:你如何通过追求数学来为人类服务,甚至更深层地,为世界的福祉服务?这样的问题不可能用纯粹理智的方式回答,因为我们行动的影响远远超出我们的理解。我们是深度社会化和深度本能的动物,以至于我们的福祉依赖于许多难以用理智方式解释的事情。这就是为什么你最好听从你的心和你的激情。纯粹的理性很可能把你引入歧途。我们中没有人足够聪明和明智到能够纯粹理智地想明白这一切。
数学的产物是清晰和理解。不是定理本身。例如,像费马大定理或庞加莱猜想这样著名的结果,有什么真正的理由说它们重要吗?它们真正的重要性不在于它们的具体陈述,而在于它们在挑战我们的理解方面的作用,呈现了导致数学发展从而增进我们理解的挑战。世界并不缺乏清晰和理解(说得轻描淡写)。特定数学如何以及是否可能有助于改善世界(无论那意味着什么)通常是不可能分辨的,但数学总体上极其重要。
我认为数学有很大一部分是心理学,因为它强烈依赖于人类的心灵。去人性化的数学更像是计算机代码,这非常不同。数学思想,即使简单的思想,从一个心灵移植到另一个心灵往往是困难的。数学中有很多想法可能很难掌握,但一旦掌握就很容易了。由于这个原因,数学理解不会以单调的方向扩展。我们的理解经常也会退化。有几种明显的衰退机制。一个学科的专家退休和去世,或者只是转向其他课题并遗忘。数学通常以符号和具体形式来解释和记录,这些形式易于交流,而不是以概念形式来易于理解。翻译的方向从概念到具体和符号比反向容易得多,符号形式经常取代理解的概念形式。而且数学惯例和被视为理所当然的知识会发生变化,所以较老的文本可能变得难以理解。
简而言之,数学只存在于活生生的数学家社区中,这个社区传播理解并为新旧思想注入生命。数学真正的满足感来自于向他人学习和与他人分享。我们所有人都对自己的一些事情有清晰的理解,对更多的事情有模糊的概念。没有办法用完需要澄清的想法。谁是第一个踏上某平方米土地的人这个问题确实是次要的。革命性变革确实重要,但革命很少,而且它们不能自我维持它们非常依赖于数学家社区。
【回答】(drbobmeister,208分) 我很荣幸能与已故的理查德费曼讨论过关于理论物理学的类似问题。他告诉我以下内容,这些话一直对我很有帮助:"你不断学习,不断学习,很快你就会学到一些没人学过的东西。"这就是他的"建议";我的建议?去做吧!
【回答】(G. Jay Kerns,152分) 你不必成为迈克尔乔丹才能打篮球。
【回答】(Todd Trimble,117分) 我欣赏OP的问题,但对我来说似乎存在一个广泛持有的谬误。"人们可以用现代语言和符号重写他们的书,或者引导他人学习,但我从未相信这是数学家工作的重要部分;那应该是创造原创数学"这是一个广泛持有的谬误。也许90%或更多的数学家工作不是辉煌的原创创造,而是消化和重塑累积见解并以对他人有用的方式重新呈现的挑战。这是一项巨大的任务,而且这通常是一项非常令人满意的创造性任务,会很好地回报给你新的见解、对主要见解后果的理解,以及对其基础的理解。这就是其中的一部分:好好教学和写作。好的阐述可能是"凡人"能做出的最重要贡献(也许我们的集体生计依赖于它Rota在《不连续的思想》中有一些关于此的明智言论)。你甚至可以在本科阶段开始:一旦你理解了某件事,就与他人分享。在当地的数学俱乐部做个好报告。把它传递下去!
Tangent_Lambda2 (1天前): Thurston的回答是 HN 上最好的回答之一。无论你处于人生的哪个阶段,都值得一读再读。
riley (1天前): 这是我见过的关于"为什么要学数学"最好的答案。数学是一种思维方式,不是终点。
JCH111 (1天前): Thurston 在 HN 上很跃。这可能是他最后一次在这个网站上留下实质性内容。
Anonymous (1天前): 费曼的建议是唯一正确的建议。去做就行了。不要想太多。
dolphinha (1天前): "你不必成为迈克尔乔丹才能打篮球" 这是整个讨论中最重要的句子。
mathoverflow123 (1天前): 真正的问题是:数学是否已经太难,以至于普通人无法做出有意义的贡献?这个讨论表明,答案可能是否定的即使你不是高斯,你仍然可以做出贡献。
Bill Thurston: 美国数学家,1982年菲尔兹奖得主,以拓扑学和几何学方面的贡献闻名,曾提出 Thurston 几何化猜想,于2012年去世。
Richard Feynman: 美国理论物理学家,1965年诺贝尔物理学奖得主,以量子电动力学(QED)方面的工作闻名,同时也是著名的科学传播者。
Todd Trimble: 美国数学博主和教育者,在 MathOverflow 和 n-Category Café 等平台活跃,专长于拓扑学和数学教育。
MathOverflow: 2009年上线的数学家在线问答社区,主要面向专业数学研究者,是全球最重要的数学交流平台之一。
The locals don't know 158票 124评论 by herbertl
标签:旅行, 散文, 生活哲学, 文化
背景注释: Anthony Bourdain (已故著名厨师和旅行节目主持人,以《波登不设限》等节目闻名) | Rick Steves (美国旅行作家和电视节目主持人,以欧洲旅游指南著称)
一篇关于旅行的哲学散文。作者的核心观点:不要"像当地人一样旅行"因为当地人的日常生活其实很无聊(看综艺、点外卖、赌球),而游客反而因为新鲜眼光和开放心态能真正享受一座城市的美好。文中反问"谁才是被困住的人?"是那些在著名景点玩得开心的游客,还是屋里玩《杀戮尖塔2》的当地人?全文辛辣又温暖,最后提醒:对"游客陷阱"一词保持怀疑,其他方面尽管享受旅行就好。
我给出的最好的旅行建议是:避免做当地人做的事。听着,我读过(也看过) Bourdain 的作品。我几乎喜欢他拍的一切。而 Bourdain 是人们在你耳边唠叨要像当地人一样时总会提到的那个人。但讽刺的是,Bourdain 和类似的人所做的,恰恰不是当地人在做的事。或者说,至少现在已经不是了。也许这听起来很奇怪。也许你和我在当地人这件事上的理解并不一致。也许在过去那些辉煌岁月里不管那意味着什么,也不管那些日子是否真的存在过当地人确实曾经是值得你效仿的旅行对象。
但今天我可以想象你来到我的家乡,和当地人一起度过一天。你最终很可能会在看真人秀电视节目,在 Doordash 上点一些新美式食物其实就是加了韩式泡菜 glaze 的芝士汉堡,然后在手机上赌球。然后你喝上一两杯啤酒,因为输了赌注而心情低落,然后就去睡觉了。这个观点确实有些消极。但也不能说完全不准确。即使在不像美国随便哪个镇那样堕落的地区和社会,即使在芬兰这样人们成天或者自称乐呵呵的地方,普通当地人的日常生活也没有那么有趣。他们可能已经十几年没去过那座举世闻名的本地博物馆了。他们可能会在赫尔辛基郊区随便吃点不好吃的墨西哥菜,因为在家已经吃够了芬兰菜想换换口味。他们可能会和几个朋友在 Kaivopuisto 公园闲逛。也许会去徒步?我想说的是,即使在最理想的情况下,当地人的日子通常都不会过得多么精彩或者多么地道。
而游客则不同。他们眼睛亮晶晶的,满怀期待,刚温习完自己最喜欢的 Rick Steves 节目,游客是这座城市里最天真的人。游客还没有花几十年把自己塞进一个叫做城市生活的愤世嫉俗却又舒适无比的盒子里。游客,比任何当地人都更能够真正随心所欲。想去看所有的景点、逛博物馆?很好,去吧。想在某座著名建筑前拍一张俗气的照片?棒极了。想抛开所有游客必做的事,来一场古怪疯狂的冒险,比如一天走遍全城,或者玩捉迷藏,或者和朋友比赛看谁能用十块钱买到最酷的东西?去做就是了。作为游客的你,可以度过一段美好的时光,然后回家告诉家人和朋友芬兰有多好、你有多想再去。而就在你做所有这些事的时候,我们之前随机选中的那个当地人正在屋里玩着杀戮尖塔2。
我记得有一次在一个小镇的湖边散步,那里人们可以租借小木船或脚蹬船出去玩水。和我在一起的当地人说:切,游客陷阱。我看了看那个做表情的当地人,又看了看离我们最近的那艘船上正在朝着日落划向湖心的游客情侣,他们相视而笑,我不禁在想:我们谁被困住了?因为在我看来,那些游客明明玩得非常开心。又及:如果你是个当地人,你也可以做所有这些事。
旅游显然会有很多负面影响,其中之一就是它会降低事物的质量。我对"游客陷阱"这个词持怀疑态度它主要被用作一种让自己显得比他人品味更高、格调更高的手段,而且往往出于不安全感才被使用,但确实有很多餐厅因为旅游而降低了品质。举个例子,也许不要去那些门口挂着巨大菜品照片、有英文菜单的地方。其他方面,尽情享受就好了。
throwaway484938 (1天前): 这是我读过的最好的旅行建议。真的。
dm2747 (1天前): "谁才是被困住的人?"这个问题问得真好。那些游客看起来比当地人更享受那艘船。
jack89 (1天前): Bourdain 说的"像当地人一样旅行"其实是反讽。大多数人其实并不想像当地人那样生活。
mgsouth (1天前): 作为一个经常出差的人,这篇文章说出了我一直在想的东西。当地人生活在"盒子"里,旅行者才是真正自由的。
TeaVenture (1天前): 杀戮尖塔2(Slay the Spire2)哈哈哈哈,太真实了。
Anthony Bourdain: 已故著名厨师、作家和旅行节目主持人,以《波登不设限》(No Reservations)、《波登闯异地》(A Cook's Tour) 等节目闻名,以真诚、不端着、深入当地文化的旅行纪录片风格著称,于2018年去世。
Rick Steves: 美国旅行作家和电视节目主持人,专注于欧洲旅游,著有大量旅行指南,倡导"深度游"理念。
杀戮尖塔2 (Slay the Spire 2): 2024年发布的独立卡牌构建roguelike游戏,由MegaCrit开发,因其深度和重复可玩性在玩家中广受欢迎。
Doordash: 美国外卖配送平台,用户可通过App点购当地餐厅的外卖。
Kaivopuisto 公园: 芬兰赫尔辛基市中心的一个公园,是当地人休闲的热门场所。
AI agent 也需要一张地图。
五月的工具列表里,有几个名字值得停一下。一个 hex 编辑器带了颜色,一个数据目录开始接 MCP,还有一个 Elixir 的 LSP 悄悄更名上线。不是什么大事,但每一件都指向同一个方向:开发者的工作台正在变得更可感知、更可查询。
工具越来越懂得如何把自己的内部状态暴露出来不管是字节、元数据,还是代码语义。
| 名称 | 中文说明 |
|---|---|
| committed | Git 提交历史检查工具,帮你挑出不规范的 commit message |
| dexter-lsp | 专为大型代码库优化的 Elixir LSP 服务器 |
| go-hass-agent | Linux 桌面原生 Home Assistant 客户端代理 |
| hexapoda | 彩色 modal 风格的终端 hex 编辑器 |
| marmot | 开源数据目录,支持向 AI agent 暴露元数据 |
| nettle@3 | 低层级加密库(版本锁定包) |
| plutosvg | 轻量 C 语言 SVG 渲染库 |
| sol2 | C++ 与 Lua 双向绑定的 API 封装层 |
| vtzero | 极简矢量瓦片编解码库(C++) |
| 名称 | 中文说明 |
|---|---|
| chiri | CalDAV 兼容的任务管理 macOS 应用 |
| openchamber | OpenCode AI 代理的桌面/网页可视化界面 |

用过 xxd 的人大概都知道那种感觉屏幕上全是十六进制字符,没有颜色,没有选区概念,想改一个字节要先查怎么跟 vim 配合。
hexapoda 换了一套思路。它跟 Helix 学了"选择优先"的 modal 模式:先选中一段字节区间,再决定对它做什么。ijkl 移动(或者 hjkl,可以配置),1/2/3 拆分字节块,m 标记偏移量,J 跳转。操作逻辑和普通文本编辑器接近了很多。
最重要的是:它有色。不同类型的字节用不同颜色区分,阅读二进制文件的心智成本一下子低了一大截。
对于偶尔需要检查固件、协议包或者序列化格式的开发者,这个工具值得装着备用。
brew install hexapoda 
有一类问题,AI 助手回答起来特别吃力:「这个字段的 owner 是谁?」「负责用户订单的表叫什么?」不是因为 AI 不聪明,是因为它根本不知道你们公司的数据长什么样。
marmot 要解决的就是这件事。它是一个轻量级开源数据目录,把你的数据库表、消息队列、API、看板统一索引起来,然后内置一个 MCP serverClaude、Cursor 这类工具可以直接向它查询,拿到的是来自数据目录的权威元数据,不是 AI 自己猜的。
和 DataHub、Amundsen 这类企业级数据目录比,marmot 的门槛低得多:单二进制文件,Docker 五分钟跑起来,支持 500k+ 资产,平均响应不到 50ms。MIT 协议,数据也不出自己的环境。
这不是一个"等团队大了再用"的工具。三个人的小团队,如果 AI agent 开始进入你的开发流程,数据目录这件事现在就值得想一想。
brew install marmot Elixir 的语言服务器(ElixirLS)在大型代码库里一直有卡顿问题项目一大,补全变慢,索引常常超时。dexter-lsp 是 remote.com 工程团队针对这个问题重新做的 LSP 实现,专门为大型单仓库优化。
它不是要替代 ElixirLS,而是在"大到 ElixirLS 已经不够用"这个场景下的一个选项。如果你的 Elixir 项目超过了某个规模,值得试试看。
brew install dexter-lsp 这周的几个工具有个共同的隐线:它们都在替某种"不透明"省成本。
hexapoda 让二进制文件变得可读;marmot 让数据资产变得可查询;dexter-lsp 让大型代码库的语义变得可感知;openchamber 让 AI agent 的行为有了可视化界面。
这不是巧合。当 AI 工具越来越深入开发流程,「让工具的内部状态对外可见」这件事就变得越来越重要。不是为了展示,是为了被查询、被理解、被协作。
marmot 是这周让我想得最久的一个。不是因为它做了什么复杂的事,恰恰相反它做的事情很简单:把数据在哪这件事说清楚。但这件事在 AI agent 开始进入工作流之后,突然变得不那么简单了。
hexapoda 也让我想起,好的 CLI 工具未必要发明新概念,有时候只是把一件早就该做好的事认真做一遍加个颜色、借用一套成熟的操作模型就能好用很多。
committed 我没有专门写,但放在那里也挺应景。在 AI 辅助提交越来越普及的时代,一个检查 commit message 规范的工具,某种程度上是在帮你确认:这条记录是你写的,还是机器写的,有没有差别。
工具总是先于方法论出现。marmot 出现在 MCP 变得普及之前,hexapoda 出现在终端开发体验被重新重视的当下。
不一定每个都要装,但值得知道它们在解决什么。
工具在变,但问题意识不必跟着变。
早上好!以下为昨日摘要:
SOL - $96.42 PUMP - $0.0022 V2EX - $0.0020
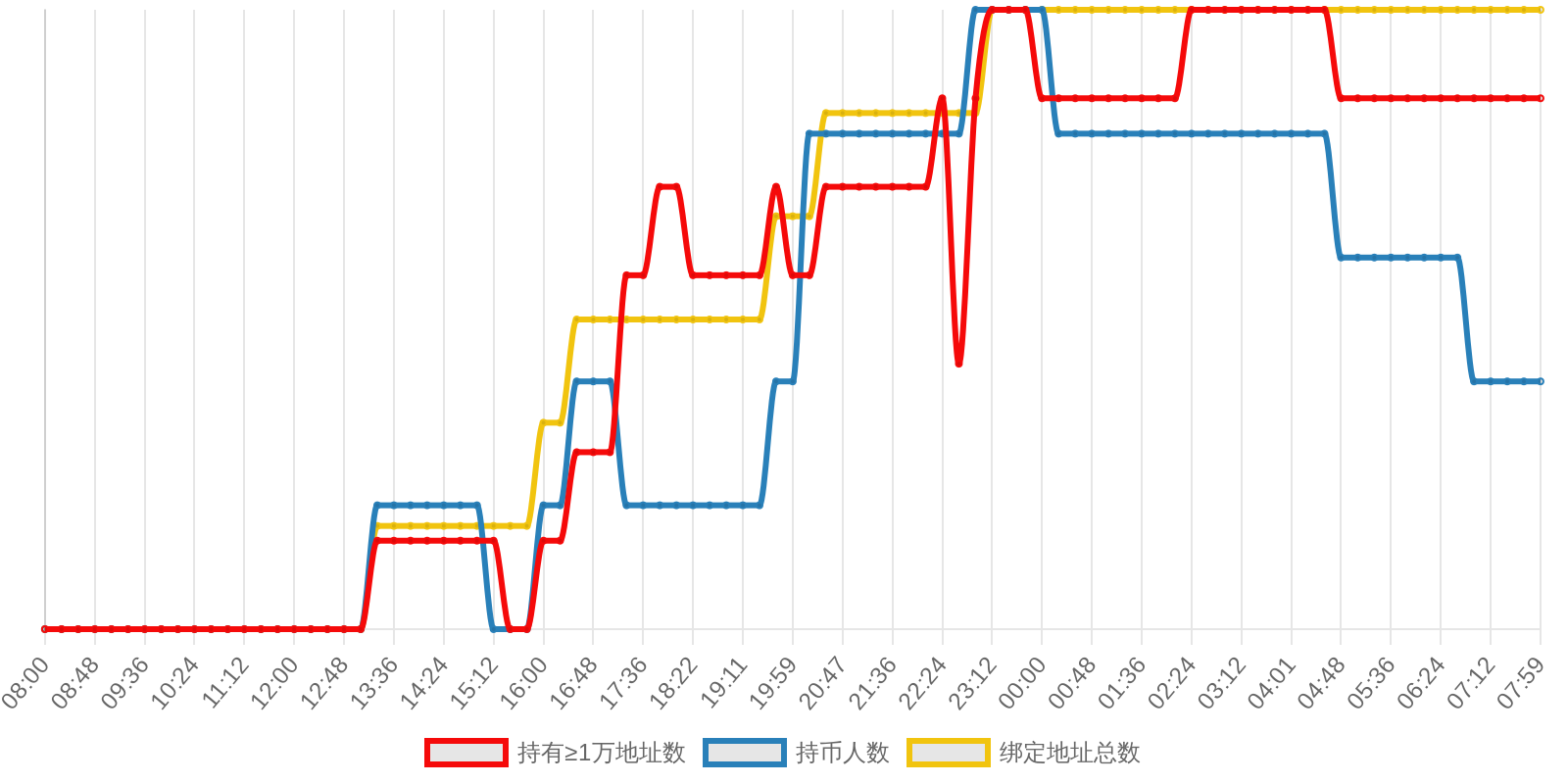
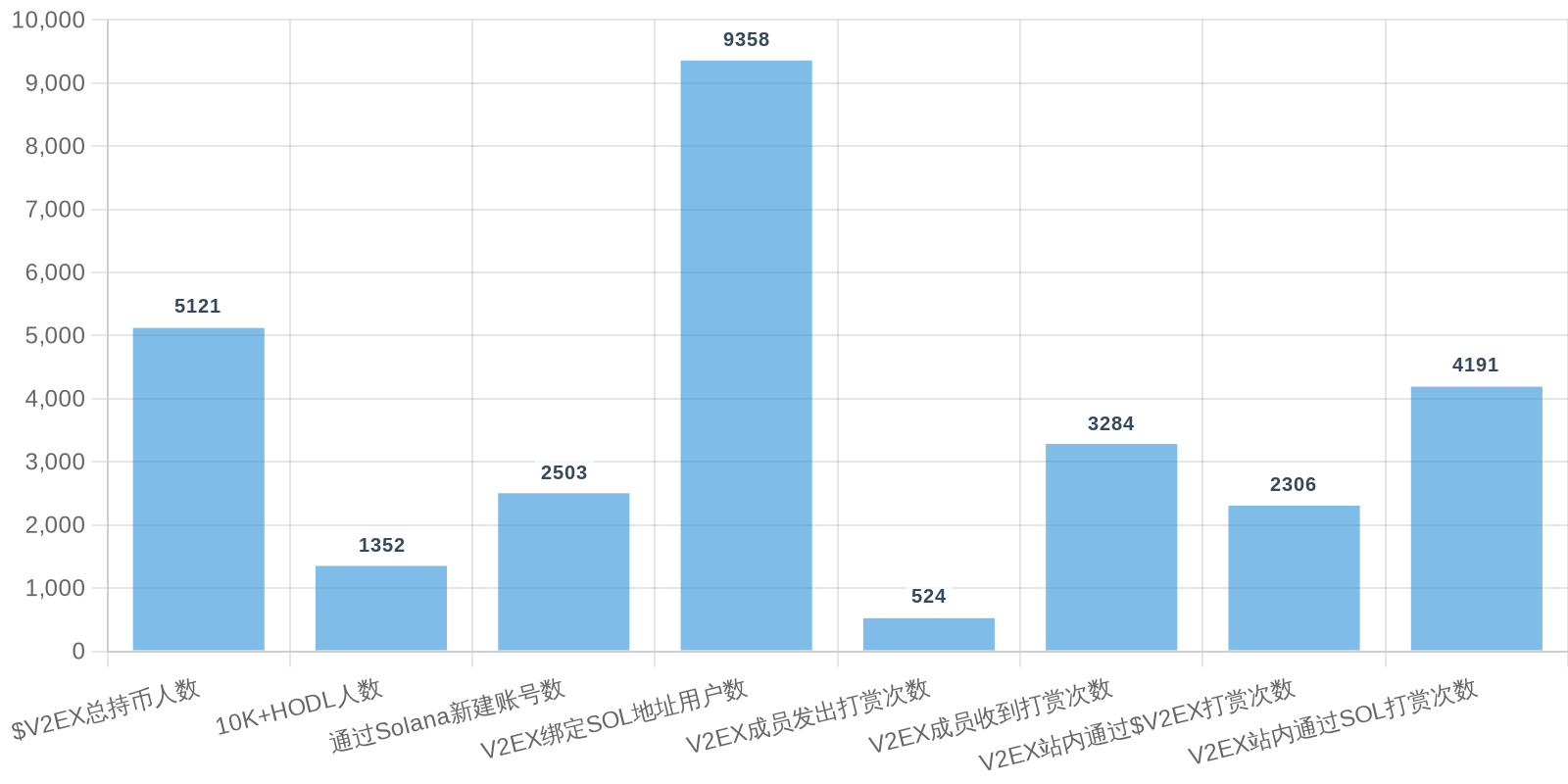
| 排名 | 地址 | 持有数量 | 持仓比例 | 排名变化 | 数量变化 |
|---|---|---|---|---|---|
| #2 | Pump.fun AMM (V2EX-WSOL) Pool | 52.43M | 5.24% | - | +38.20K |
| #9 | Meteora (V2EX-WSOL) Market | 5.03M | 0.50% | - | +11.2253 |
| #30 | BeCool | 1.19M | 0.12% | - | +9.39K |
| #46 | Meteora (V2EX-WET) Market | 0.74M | 0.07% | +3 | +30.24K |
TG 机器人订阅: 点我订阅
原始图表与数据存放于: 点我查看
此报告由 V2EX Info 提供数据, 由 Newsletter Report Bot 自动生成。
此报告仅供参考,不构成任何投资建议。投资有风险,入市需谨慎。
早上好!以下为昨日摘要:
SOL - $93.16 PUMP - $0.0021 V2EX - $0.0019
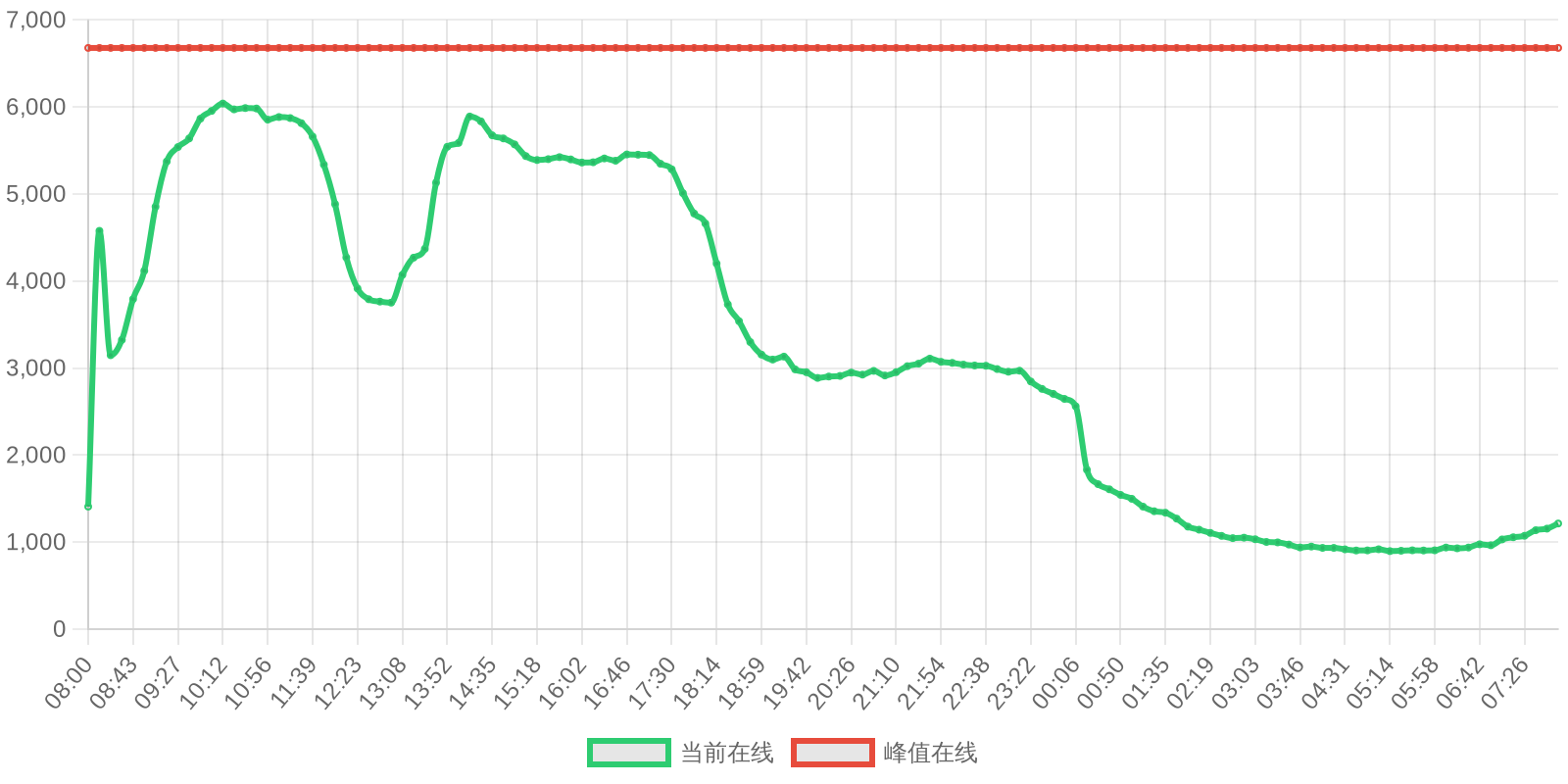
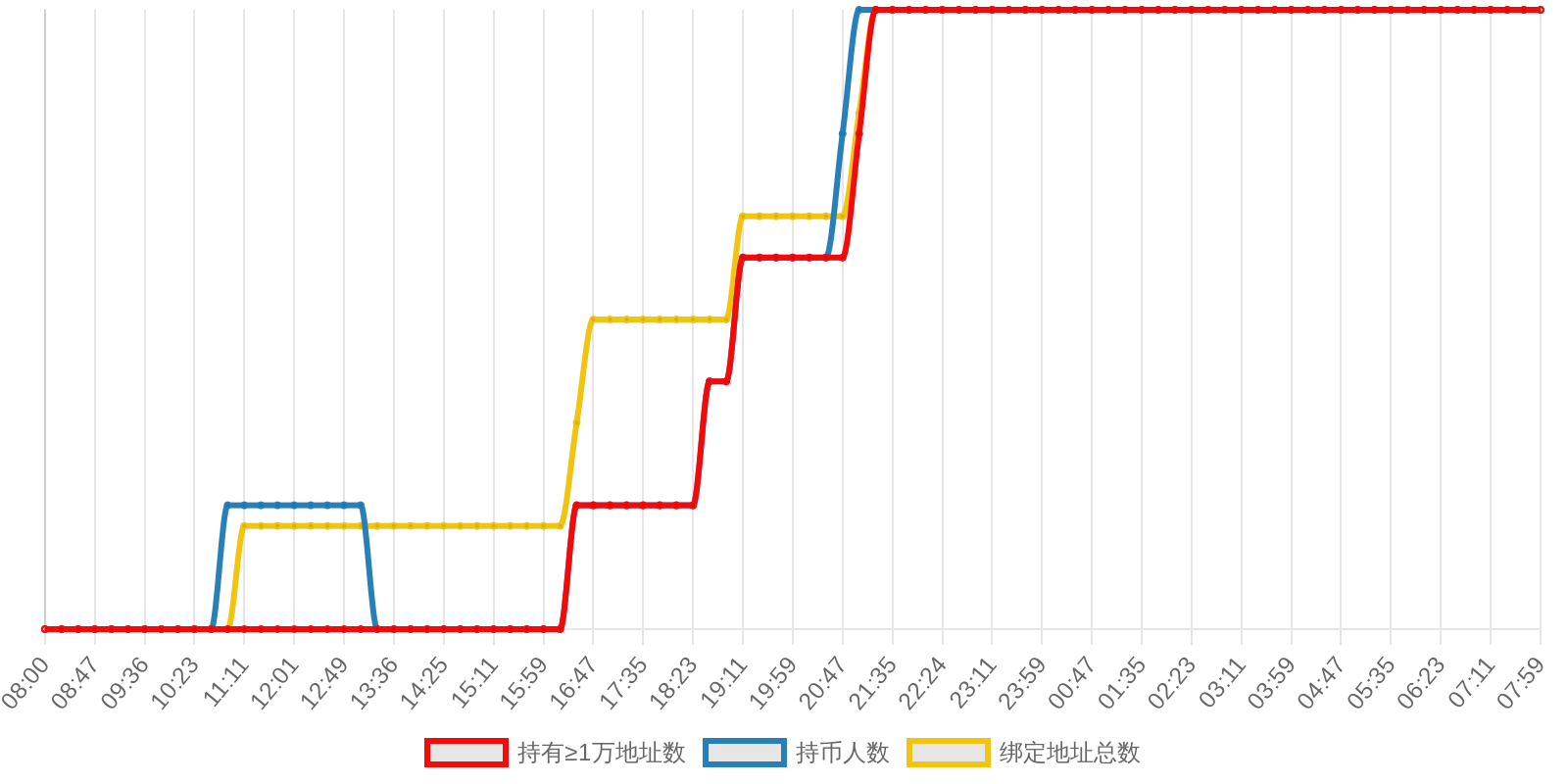
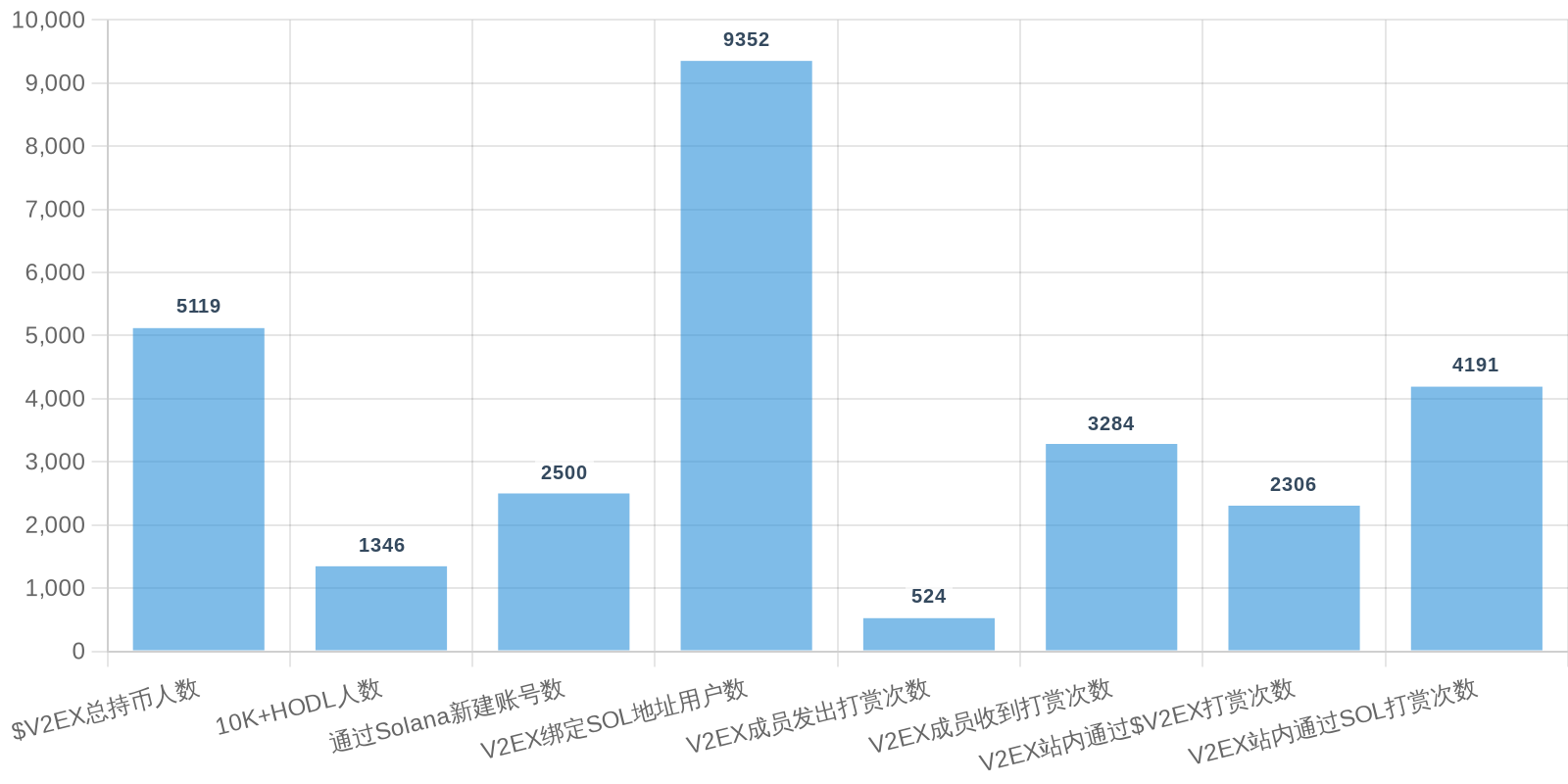
| 排名 | 地址 | 持有数量 | 持仓比例 | 排名变化 | 数量变化 |
|---|---|---|---|---|---|
| #2 | Pump.fun AMM (V2EX-WSOL) Pool | 52.39M | 5.24% | - | -0.26M |
| #9 | Meteora (V2EX-WSOL) Market | 5.03M | 0.50% | - | -4.67K |
| #11 | Meteora (V2EX-PUMP) Market | 4.95M | 0.49% | - | +0.897312 |
| #17 | Livid | 2.60M | 0.26% | - | +8.54K |
| #49 | Meteora (V2EX-WET) Market | 0.70M | 0.07% | -5 | -63.37K |
TG 机器人订阅: 点我订阅
原始图表与数据存放于: 点我查看
此报告由 V2EX Info 提供数据, 由 Newsletter Report Bot 自动生成。
此报告仅供参考,不构成任何投资建议。投资有风险,入市需谨慎。
我有没有去锻炼身体?
我有没有去做一些努力减少生活中冒出来的混乱?
理解和实践断舍离。不买无用之物。持续清理不需要的东西。
我有没有和家人在一起的时间?
我有没有花时间去做一个使用起来感到愉悦的软件?
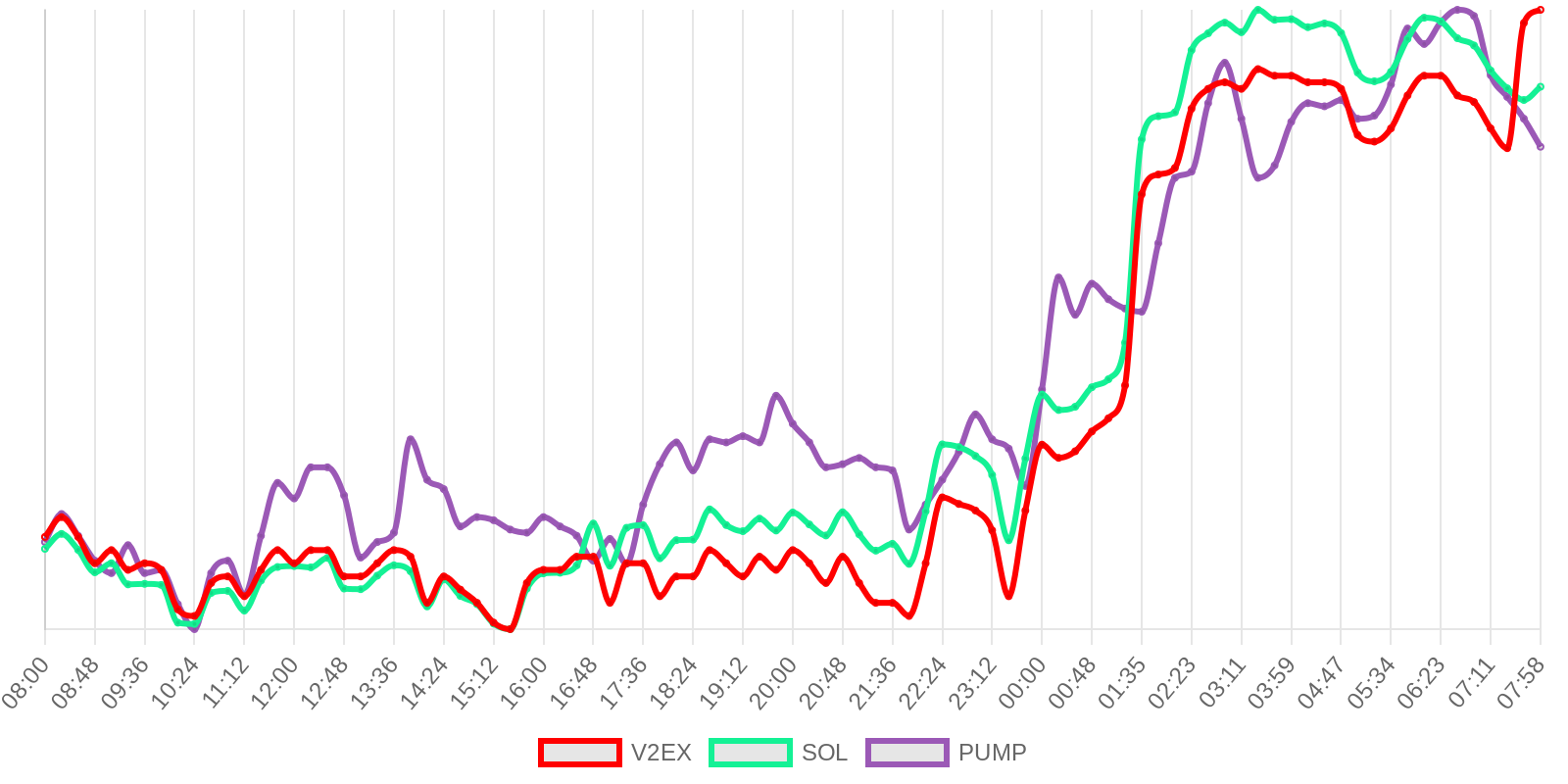
早上好!以下为昨日摘要:
SOL - $91.96 PUMP - $0.0021 V2EX - $0.0019
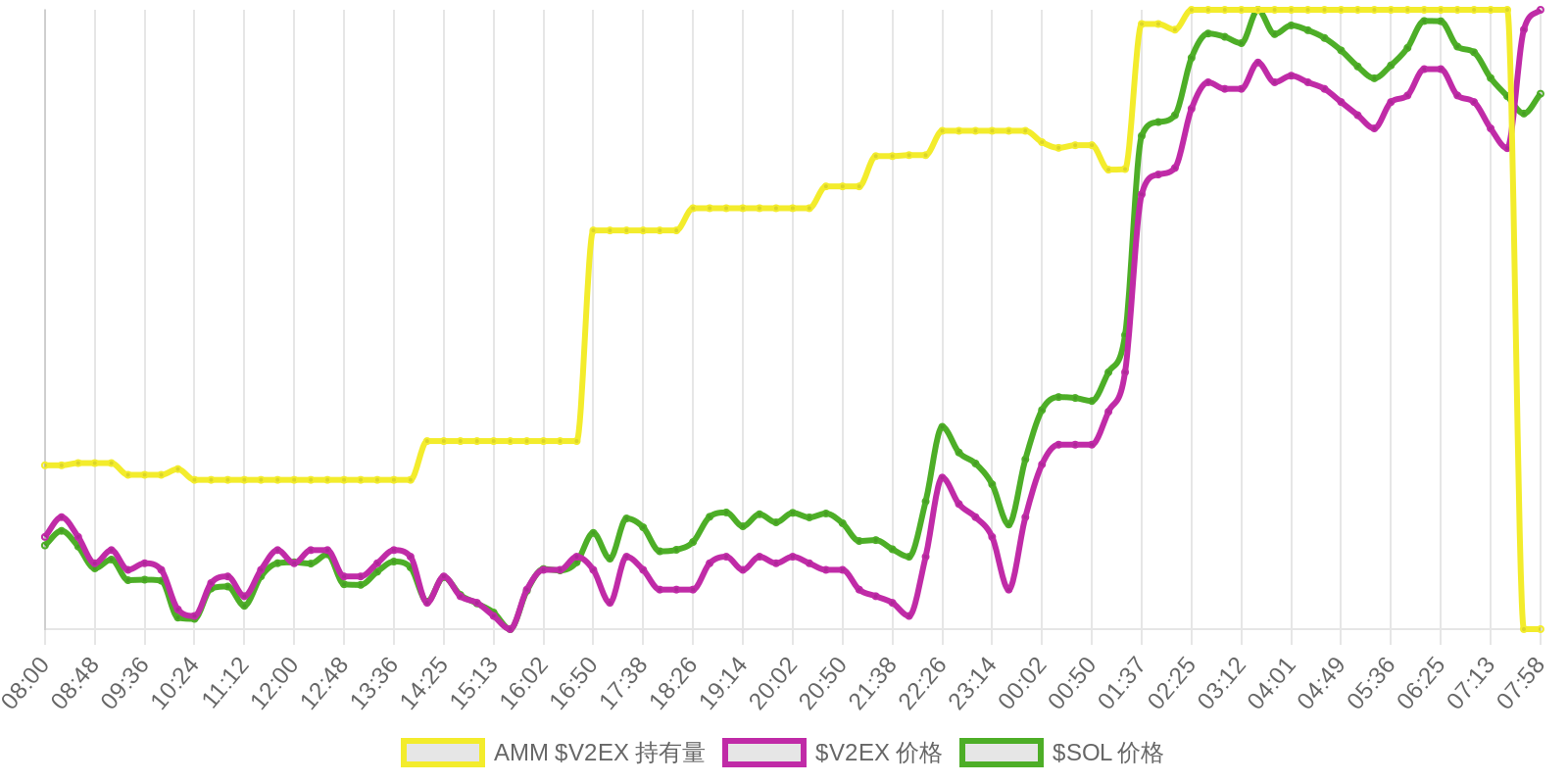
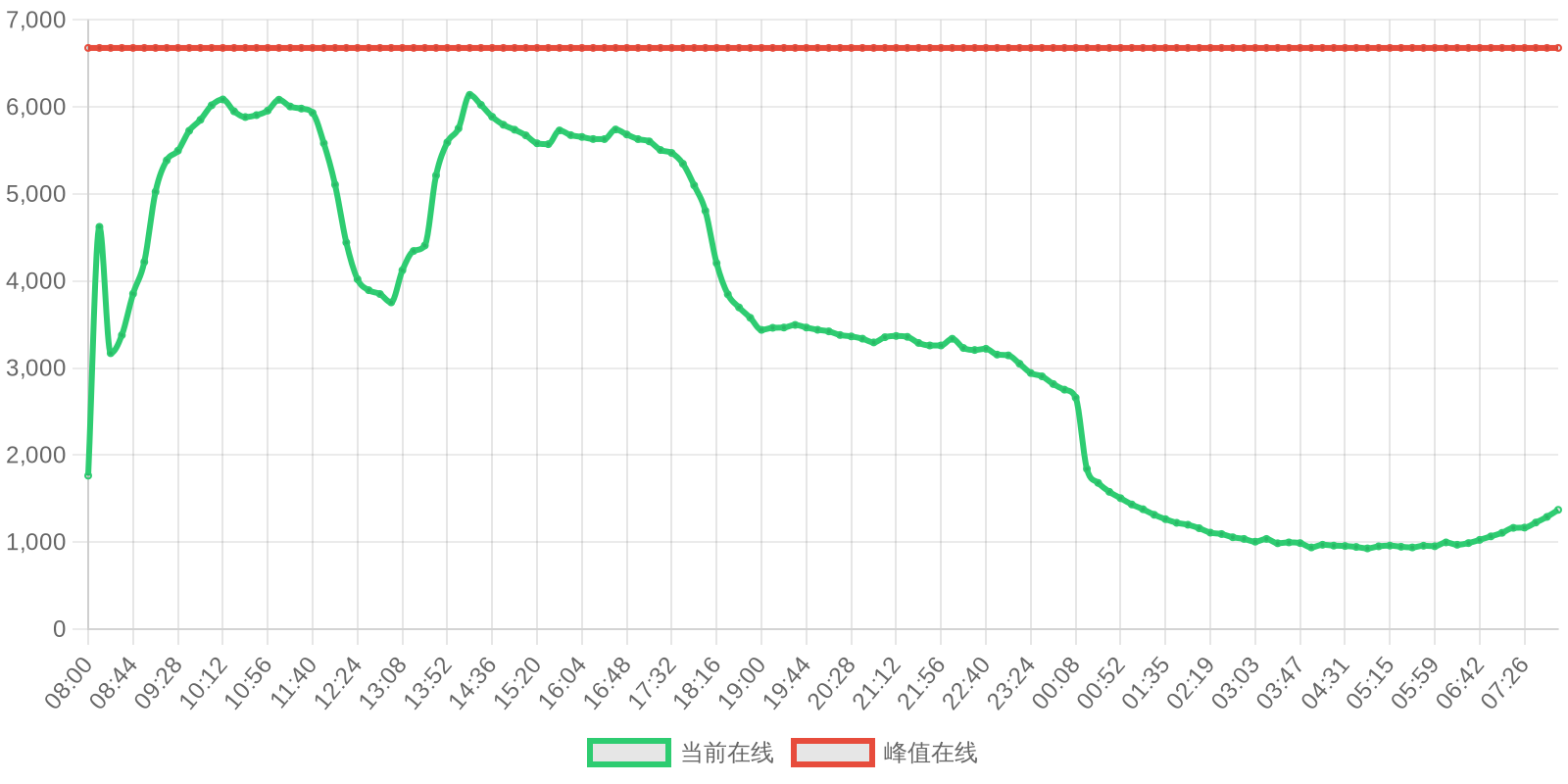
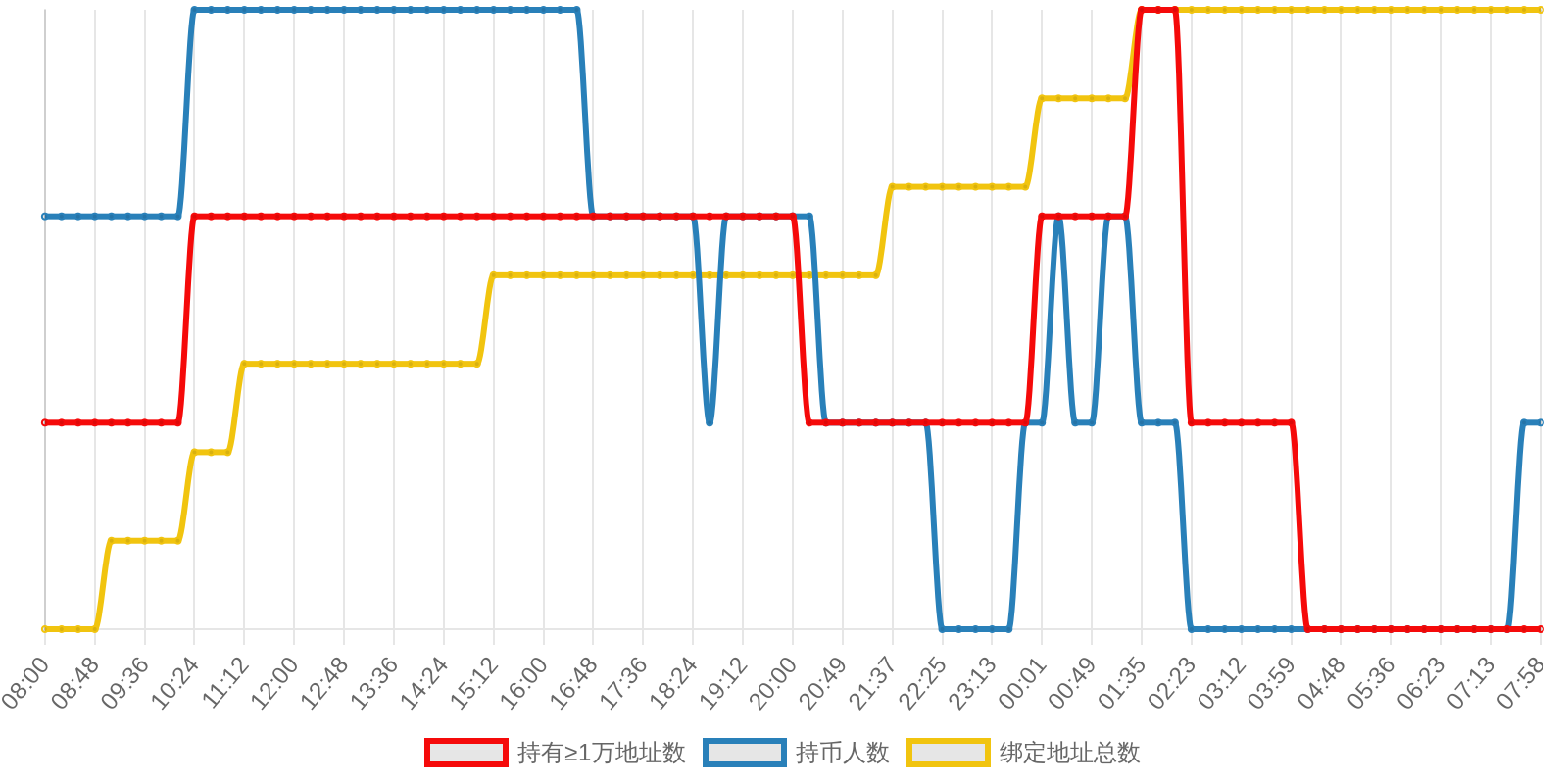
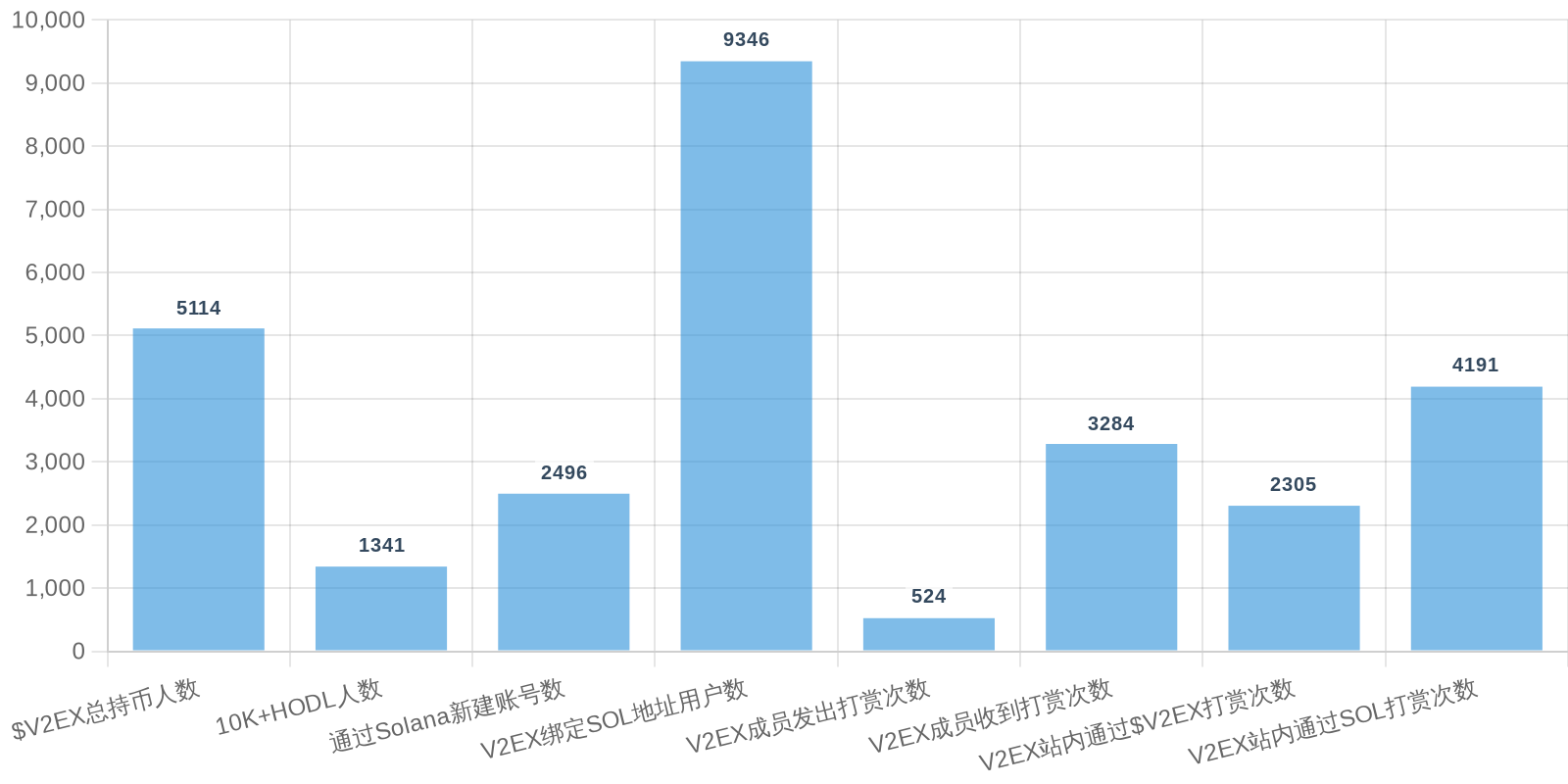
| 排名 | 地址 | 持有数量 | 持仓比例 | 排名变化 | 数量变化 |
|---|---|---|---|---|---|
| #2 | Pump.fun AMM (V2EX-WSOL) Pool | 52.65M | 5.26% | - | +0.21M |
| #9 | Meteora (V2EX-WSOL) Market | 5.04M | 0.50% | - | +4.70K |
| #30 | BeCool | 1.18M | 0.12% | - | +4.79K |
| #44 | Meteora (V2EX-WET) Market | 0.77M | 0.08% | -4 | -0.10M |
TG 机器人订阅: 点我订阅
原始图表与数据存放于: 点我查看
此报告由 V2EX Info 提供数据, 由 Newsletter Report Bot 自动生成。
此报告仅供参考,不构成任何投资建议。投资有风险,入市需谨慎。
这一周的 brew update,像是给 AI Agent 做了一次集体亮相。
不是某个 IDE 插件、某个 chatbot 包装, 而是连"自我成长"、"使用监控"、"代码评审"都各自有了独立工具。
Agent 不再是某个产品里的一个功能, 它正在变成一个生态。
当一个领域同时出现了"做事的人"、"看着做事的人"和"统计做事人花了多少钱的人",这个领域就不再是趋势,是产业了。
| 名称 | 中文说明 |
|---|---|
| alevin-fry | 单细胞测序数据处理工具,灵活高效 |
| barman | PostgreSQL 备份与恢复管理器 |
| crit | AI Agent 的本地反馈回路,专门用来 review 它写的代码 |
| cutadapt | 移除测序数据中的 adapter 序列 |
| defuddle | 网页正文与元数据提取,Readability 的替代选择 |
| echtvar | 快速的变异注释与过滤工具 |
| freesasa | 溶剂可及表面积(SASA)计算库 |
| gemmi | 大分子晶体学计算库与命令行工具 |
| ginkgo | 高性能数值线性代数库 |
| hermes-agent | 自我学习的 AI Agent,从经验里长出新技能 |
| hyphy | 基于系统发育树的假设检验 |
| iqtree3 | 极大似然法系统发育分析 |
| [email protected] | Kubernetes 1.35 版本的 kubectl |
| lavinmq | 轻量 AMQP/MQTT 消息中间件 |
| libchardet | Mozilla 通用字符集检测器 C/C++ API |
| oarfish | 长读长 RNA-seq 定量工具 |
| opendoor | Web 侦察、目录发现与暴露面评估 CLI |
| paml | 基于极大似然的 DNA/蛋白质系统发育分析 |
| pnpm@10 | 高效的 Node.js 包管理器 v10 |
| pomerium | 身份与上下文感知的访问代理 |
| smlnj | Standard ML 编译器与编程系统 |
| spoa | SIMD 加速的偏序对齐工具 |
| stellar-xdr | Stellar 网络的 XDR 编解码 CLI |
| unordered_dense | 高性能 robin-hood 哈希表/集合 |
| vcflib | 解析与处理 VCF 文件的 C++ 库与工具 |
| zapp | 从终端刷写 ZSA 键盘固件 |
| zfp | 支持高速随机访问的压缩数值数组 |
| 名称 | 中文说明 |
|---|---|
| eez-studio | 仪表自动化与 GUI 开发的可视化工具 |
| factory | Factory.ai 的桌面客户端,把 Droids 装进本地工作流 |
| font-akt | 字体:Akt |
| font-alien-block | 字体:Alien Block |
| font-finlandica-headline | 字体:Finlandica 标题版 |
| font-finlandica-text | 字体:Finlandica 正文版 |
| font-m-plus-u | 字体:M+ U |
| ghostpepper | 语音转文字与会议转写工具 |
| jetbrains-air | JetBrains 出品的 Agent 原生开发环境 |
| manus | 自动化本地电脑工作流的 AI Agent |
| open-webui | Open WebUI 的桌面客户端 |
| openusage | Cursor / Claude Code / Codex / Copilot 的 AI 用量统计工具 |
| screenkite | 屏幕录制与编辑工具 |
| wox | 启动器工具 |
| yakit | 网络安全集成平台 |
这一节不求全, 只挑几个"我看到时停了一下"的东西。
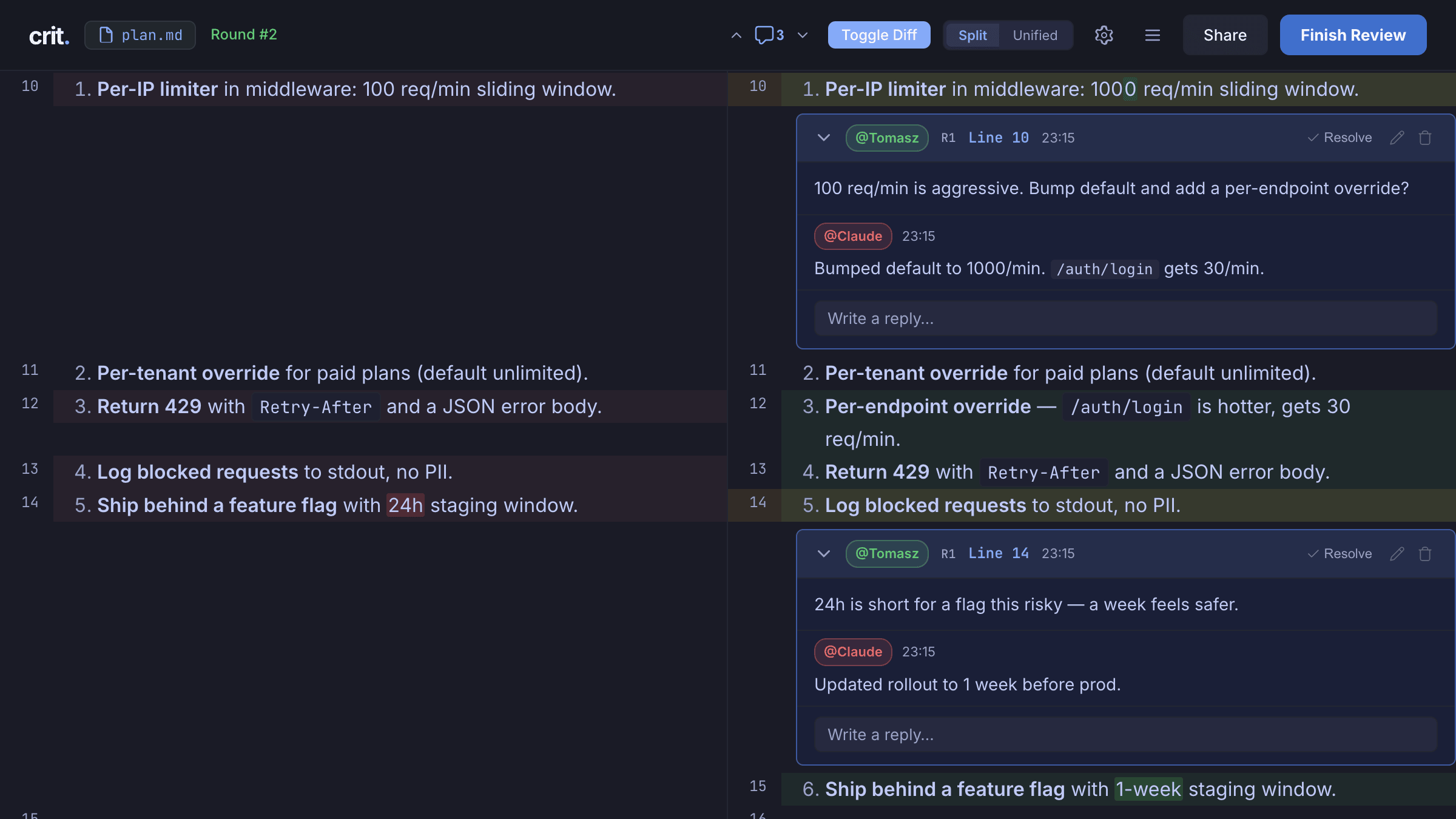
Agent 写代码的速度已经超过了人类阅读代码的速度。这不是夸张。当 Cursor 或者 Claude Code 一次给你 300 行 diff,你下意识做的事是滚动到底,看一眼测试通过没有,然后点 accept。
crit 想做的事很朴素让 review 这一步重新变成"事",而不是"形式"。它把 agent 生成的 plan 和 code 平铺在一个本地界面里,你可以画出某几行,留一条评论,然后点 finish review,agent 自动按你的评论改。
它没有解决"agent 怎么写得更好", 它解决的是"我怎么不再假装我看过了"。
本地优先、一键分享、支持 190 种语言高亮、Vim 键位这些都只是配料。真正的判断是:当 agent 越来越快,慢这一步反而成了奢侈品。

Nous Research 出的,定位有点克制它不是 copilot,不是聊天机器人壳,而是"在你服务器上跑的自治 agent"。
但真正的彩蛋藏在描述里那一句:self-improving。它会从你的项目里持续学习,把解决过的问题留存为"技能",下一次遇到同类问题直接调用。
这个想法不新,新的是它落地的方式:跨 Telegram、Discord、Slack、WhatsApp、邮件、CLI 操作;五种沙箱后端(local / Docker / SSH / Singularity / Modal);并行子 agent 各跑各的对话和终端;自然语言 cron。它在赌的是agent 真正的护城河不是模型,而是记住自己解决过什么。
它跟 Claude Code 的 skill 机制几乎是同一个方向。只是 hermes 更激进:技能不是人写好的,是它自己长出来的。
Factory.ai 这周有了 Cask。1.5B 估值、150M C 轮、agent 能直接进 VS Code / JetBrains / Vim / 浏览器 / CLI / Slack / Teams 甚至 issue tracker。
它的口号是 "agents that work everywhere you do",听上去像营销,但拆开看其实是个判断:Agent 不应该绑定 IDE,agent 应该绑定工作流。你在哪儿干活,它就在哪儿出现。
这跟同周出现的 jetbrains-air(JetBrains 的"agent 原生开发环境")形成了一种微妙对照一个想让 agent 跟着人走,另一个想给 agent 造一个自己的家。两条路都还没分出胜负,但桌面级 agent 应用这件事,已经从一两个先锋变成了一片小浪潮。
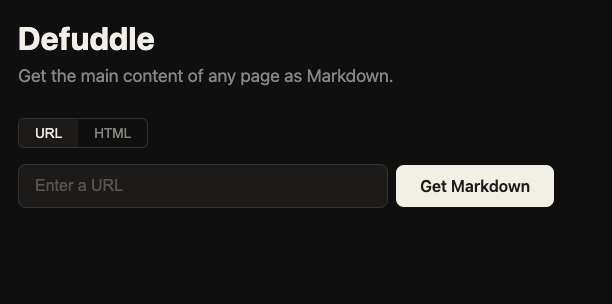
Obsidian Web Clipper 的副产品,结果反过来比主产品更值得记一笔。
它做的事就一件:从乱七八糟的网页里把正文抠出来,输出干净的 HTML 或 Markdown,顺手把元数据(标题、作者、发布时间、favicon、schema.org)也提取了。
跟 Mozilla Readability 比,它更"宽容"不确定的元素倾向保留而不是删除,因为很多时候 Readability 删得太狠,把脚注和图注也一起带走了。它还会用移动端样式来识别"装饰性"元素,这个思路挺机灵的。
为什么值得停一下:在"AI 把网页喂给模型"成为日常的今天,预处理这一步的质量直接决定了下游的智商。defuddle 做的是那种默默改善整个生态的事。
把这周的新增放在一起看,AI agent 这个领域出现了一种新的拓扑:
一个领域开始出现"周边工具",意味着它过了草莽期。当有人开始专门做"用量监控"、"代码审计"、"数据清洗"的时候,agent 就不再是某个 IDE 里的一个 panel,它开始有自己的供应链。
也就是说Agent 终于不是单飞了。
老实说,这周新增的科研工具不少(alevin-fry、cutadapt、hyphy、paml、iqtree3 一整套生物信息学工具链),但我没办法假装它们跟我有关系。这是 Homebrew 有意思的地方它从来不只是"开发者商店",它还是某些科研社区的发行渠道。
让我留意的是 zapp。ZSA 给自己的键盘做了个 brew install 的刷固件 CLI。这事很小,但很温柔硬件厂商认真对待终端用户,是这个时代越来越稀缺的事。
至于 AI agent 那一堆,老实说,我未必会都装。openusage 我大概率装,因为我已经被某个月的 token 账单吓过一次;crit 我会观望,看它跟现有 review 习惯能不能对上;hermes-agent 现在还有点重,但方向我赞同agent 的未来不在模型里,在它的"经验积累"里。
一周之内,Homebrew 同时收下了"做事的 agent"、"审 agent 的工具"、"统计 agent 花销的应用"。这种多层次出现,本身就是一个信号。
工具不再是孤立的功能点,而是开始彼此咬合。当 agent 有了 reiewer、有了用量监控、有了数据清洗器,它就从"实验"变成了"生产"。
一个赛道开始有"配角",才说明它真的成了。
早上好!以下为昨日摘要:
SOL - $88.41 PUMP - $0.0020 V2EX - $0.0018
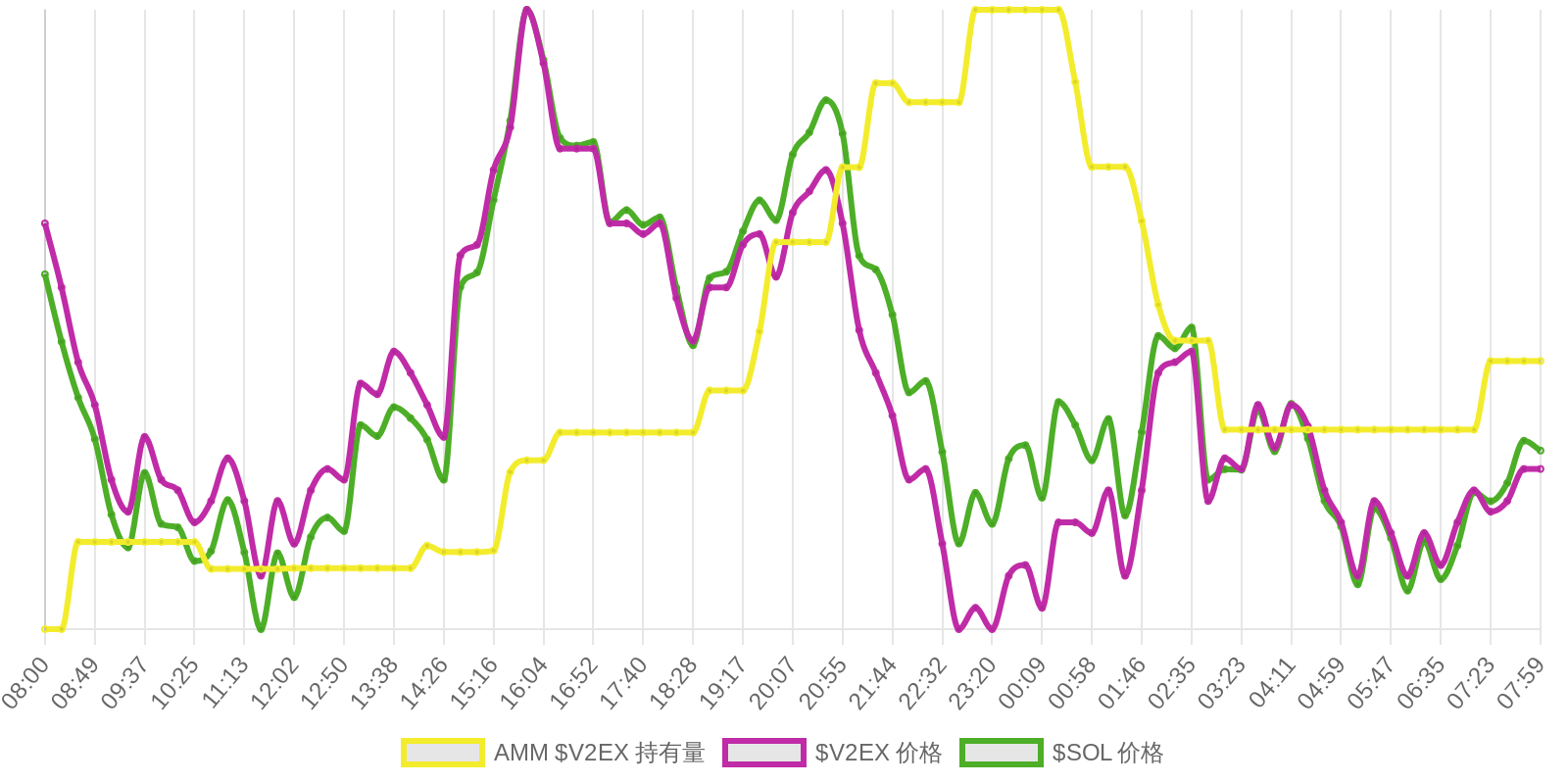
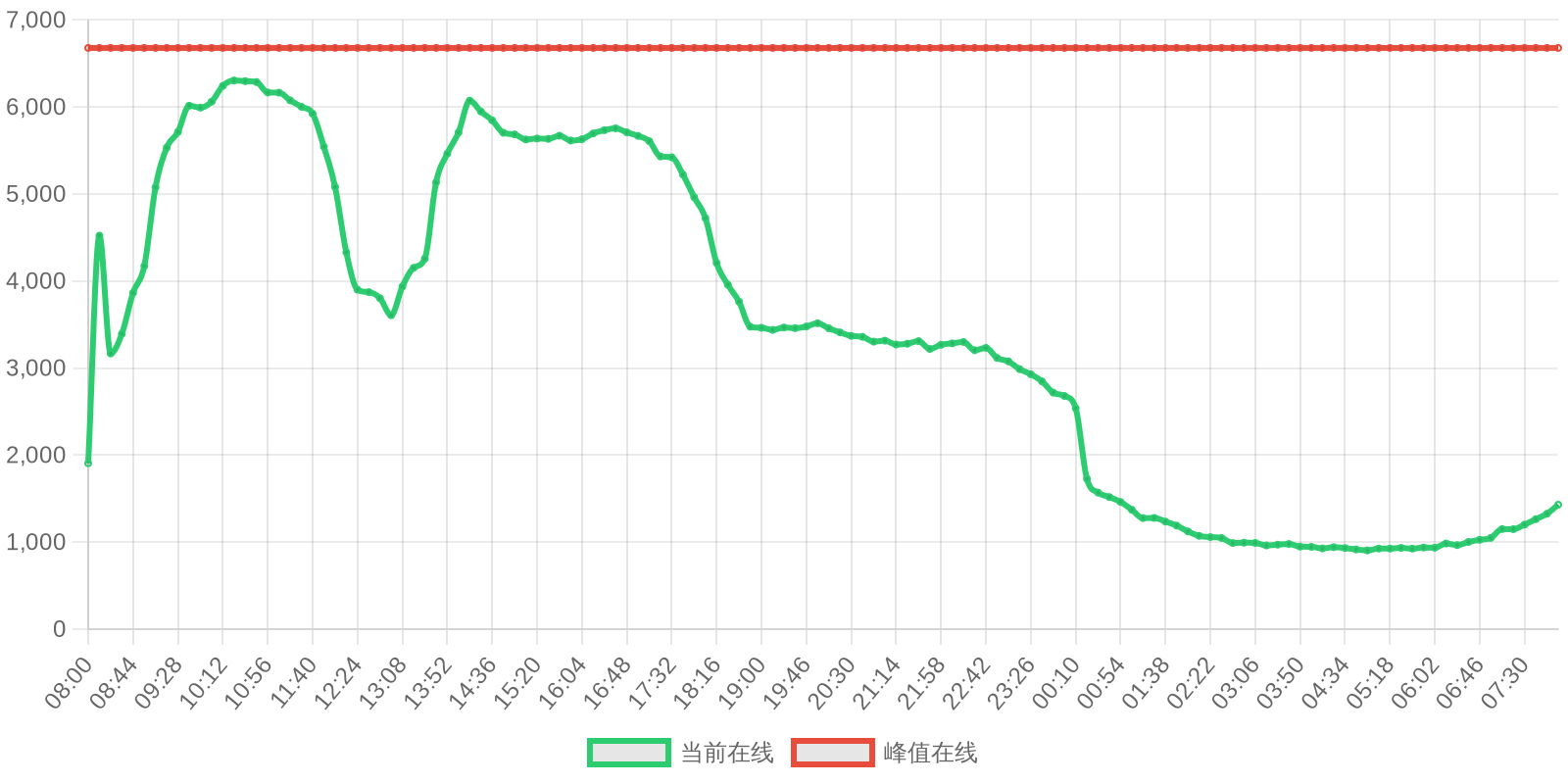
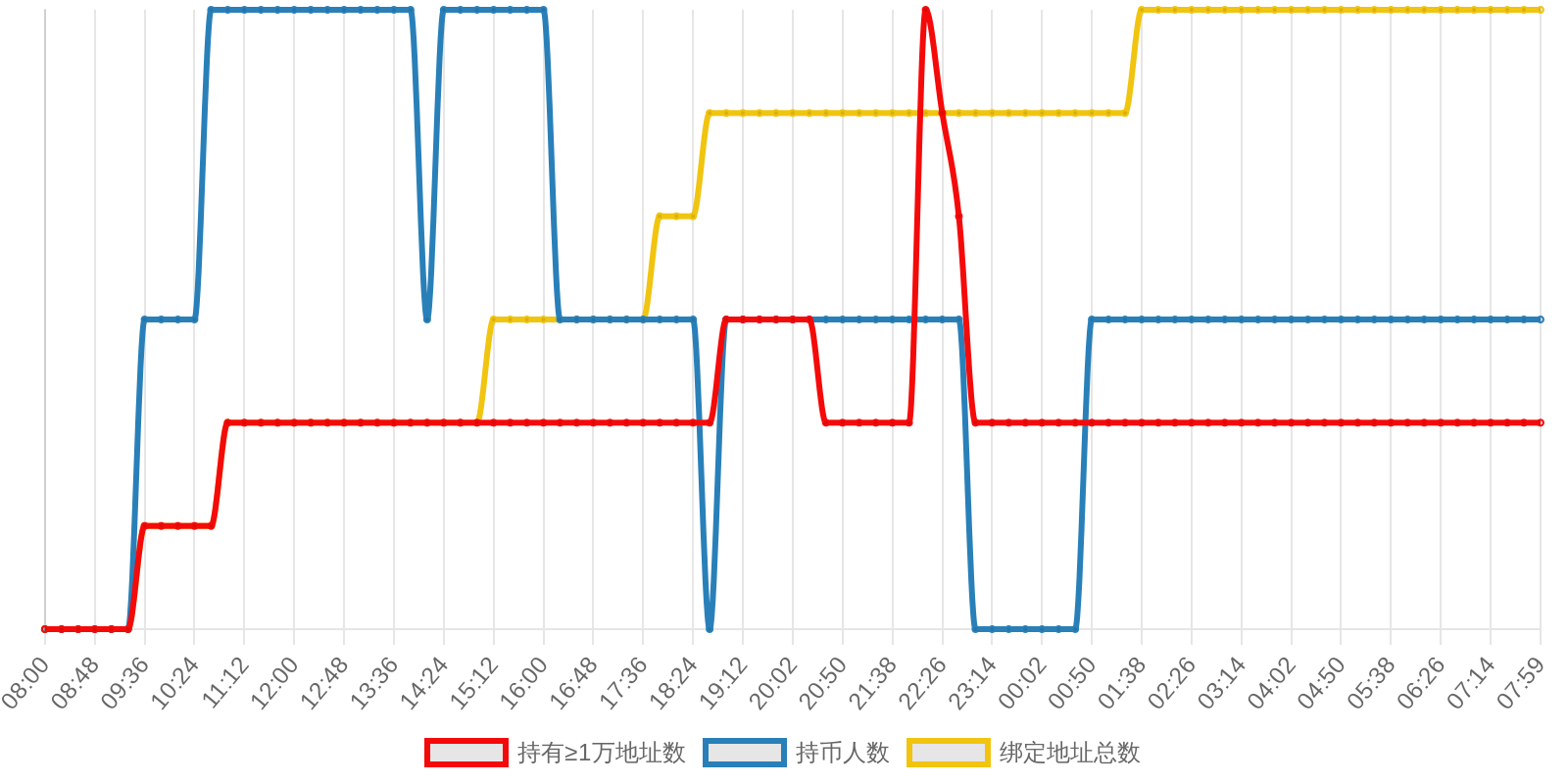
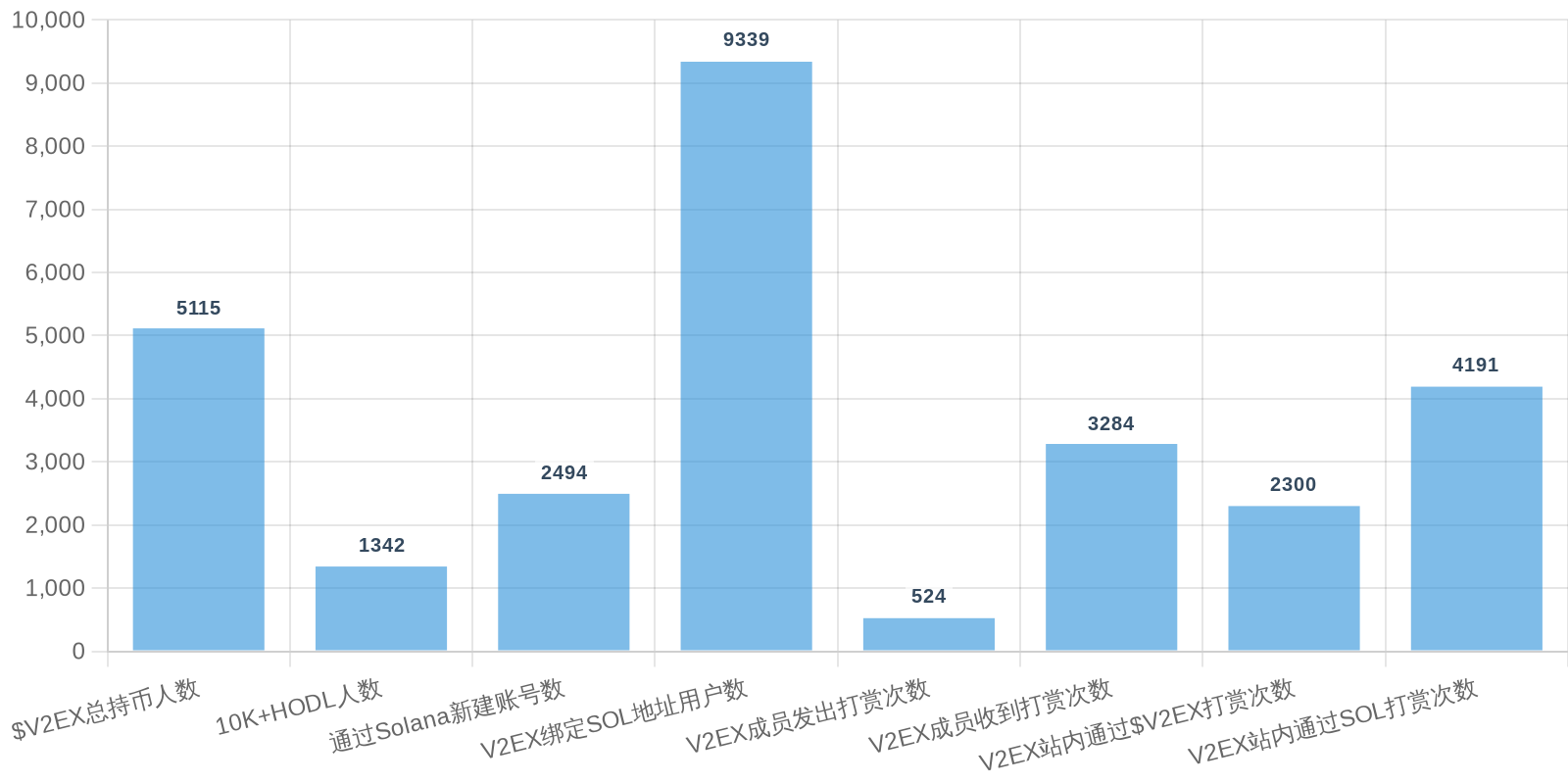
| 排名 | 地址 | 持有数量 | 持仓比例 | 排名变化 | 数量变化 |
|---|---|---|---|---|---|
| #2 | Pump.fun AMM (V2EX-WSOL) Pool | 52.44M | 5.24% | - | +0.10M |
| #5 | DdGV...aRkf | 7.02M | 0.70% | - | +2.30K |
| #9 | Meteora (V2EX-WSOL) Market | 5.03M | 0.50% | - | +19.8341 |
| #11 | Meteora (V2EX-PUMP) Market | 4.95M | 0.49% | - | +6.4322 |
| #17 | Livid | 2.59M | 0.26% | - | +7.16K |
| #40 | Meteora (V2EX-WET) Market | 0.87M | 0.09% | - | +3.56K |
TG 机器人订阅: 点我订阅
原始图表与数据存放于: 点我查看
此报告由 V2EX Info 提供数据, 由 Newsletter Report Bot 自动生成。
此报告仅供参考,不构成任何投资建议。投资有风险,入市需谨慎。
因为AI给大部分人造成的效率幻觉, 让人们觉得自己是超人, 通过AI快速出来了一个demo, 就迫不及待的来给大家推广安利
以期能够撞到蓝海或者风口, 实现一波暴富, 没错, 说的是我
好的产品往往需要细细的打磨, 对每一个环节的设计和实现, 都应该精益求精甚至苛刻.
每一步的交互, 每一个逻辑的实现, 都应该为提升用户体验来服务, 掌握每一行代码往往是做到这一点的前提.
但是在AI辅助开发的时代, 掌握每一行代码真的是太困难了, 需要太大的毅力和精力来处理AI的代码, 这是很多人不想做的一件事情, 当然也包括我
让AI来审核AI看似是一条解决之路, 把自己定位成管理者, 管理各种AI员工来工作, 自己只需要验证结果, 甚至结果也让AI来验证, 貌似没有什么问题, 但是这样会让事情逐渐的走向失控.
我对项目的了解越来越少, 甚至我都不知道一个功能需求是通过什么方式来实现的, 虽然这个功能运行良好.
随着迭代次数的增加, 这样的功能需求越来越多, 直到有一天, 我打开了项目, 想要排查一个线上的问题.
看着熟悉又陌生的代码, 我发现我已经无法掌控这个庞然大物, 所以排查线上的问题就直接扔给了AI员工来处理, 在AI员工给我汇报原因和解决方案的时候, 我甚至都不能确定这是不是问题的根源, 但是只能签字部署, 观察结果, 像极了我年轻时候的领导, 哈哈哈, 终归是活成了我最讨厌的模样.
以上, 是闲暇时的碎嘴, 但是在我和AI互帮互助的过程中, 确实产生了一些类似上述的问题, 也拍脑袋的做了很多的小玩具.
昨晚上睡前冥想的时候, 猛然警觉, 我现在使用AI做的这些玩具Demo, 除了消耗一些Token, 浪费大家一些流量带宽, 还有什么其他的意义吗? 答案是大部分都没啥意义, 纯粹是做出来玩一下, 博个眼球, 要些关注, 甚至有些玩具生成完连代码都没有看一眼.
今天上班骑行的路上, 我也在思考AI到底能不能做出优秀的作品来, 到现在大概得出了一个不成熟的结论:
决定作品是否优秀的从来不是框架、编程语言或者大模型, 而是做这个作品的人.
用AI也好, 用古法也罢, 只有静下心来, 专心打磨, 才有可能产出优秀的作品.
与诸君共勉!
早上好!以下为昨日摘要:
SOL - $89.15 PUMP - $0.0019 V2EX - $0.0019
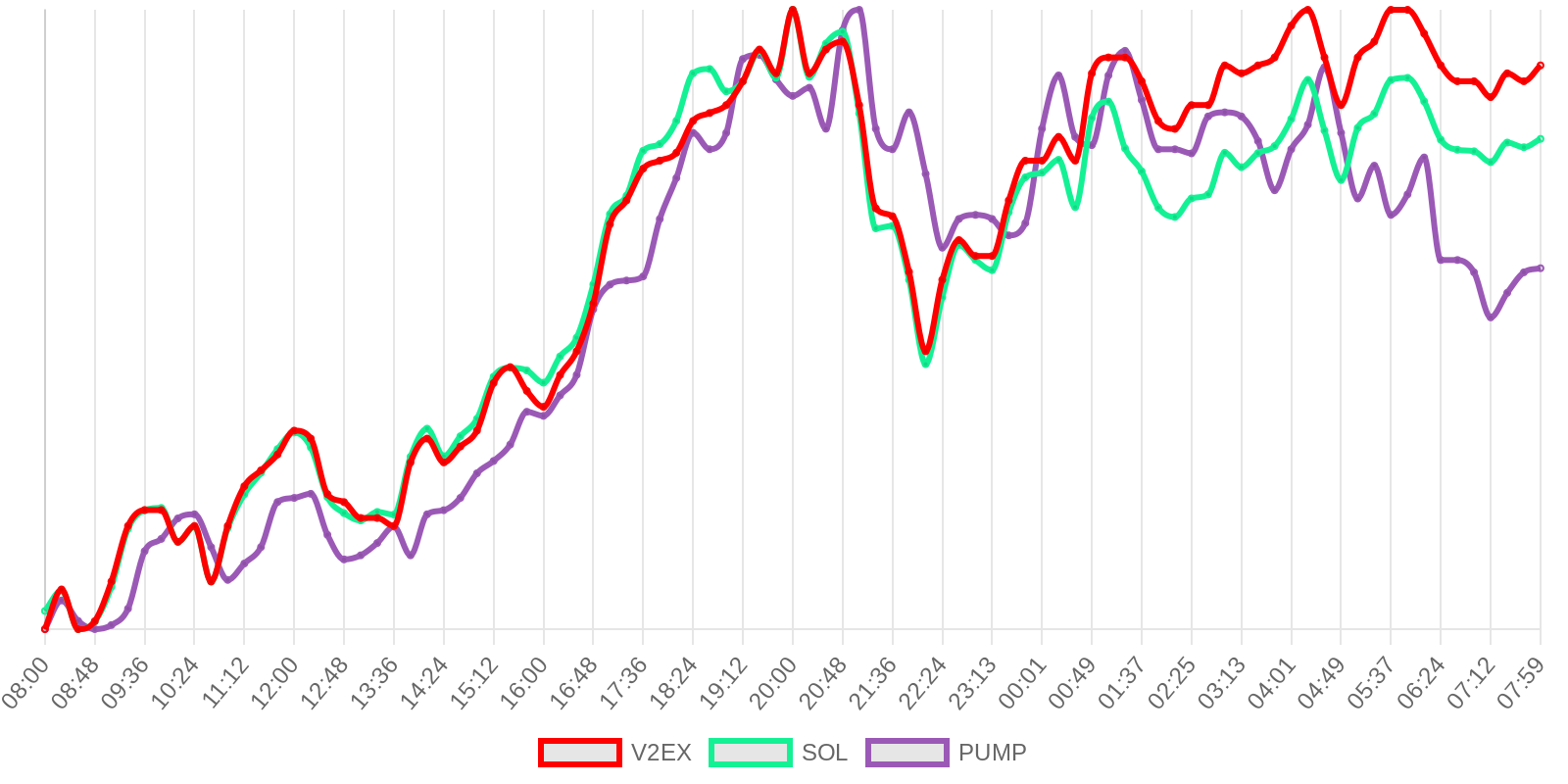
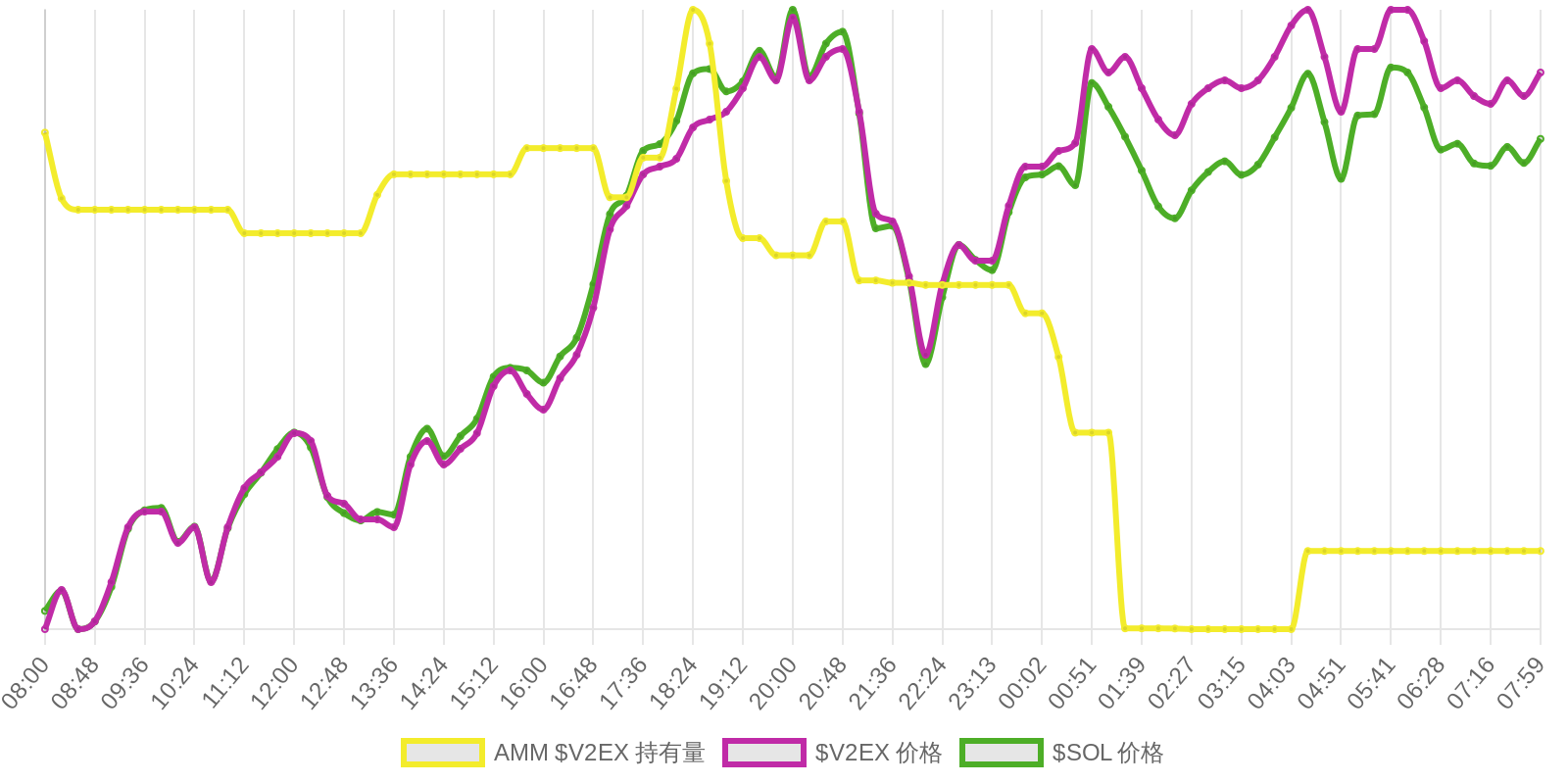
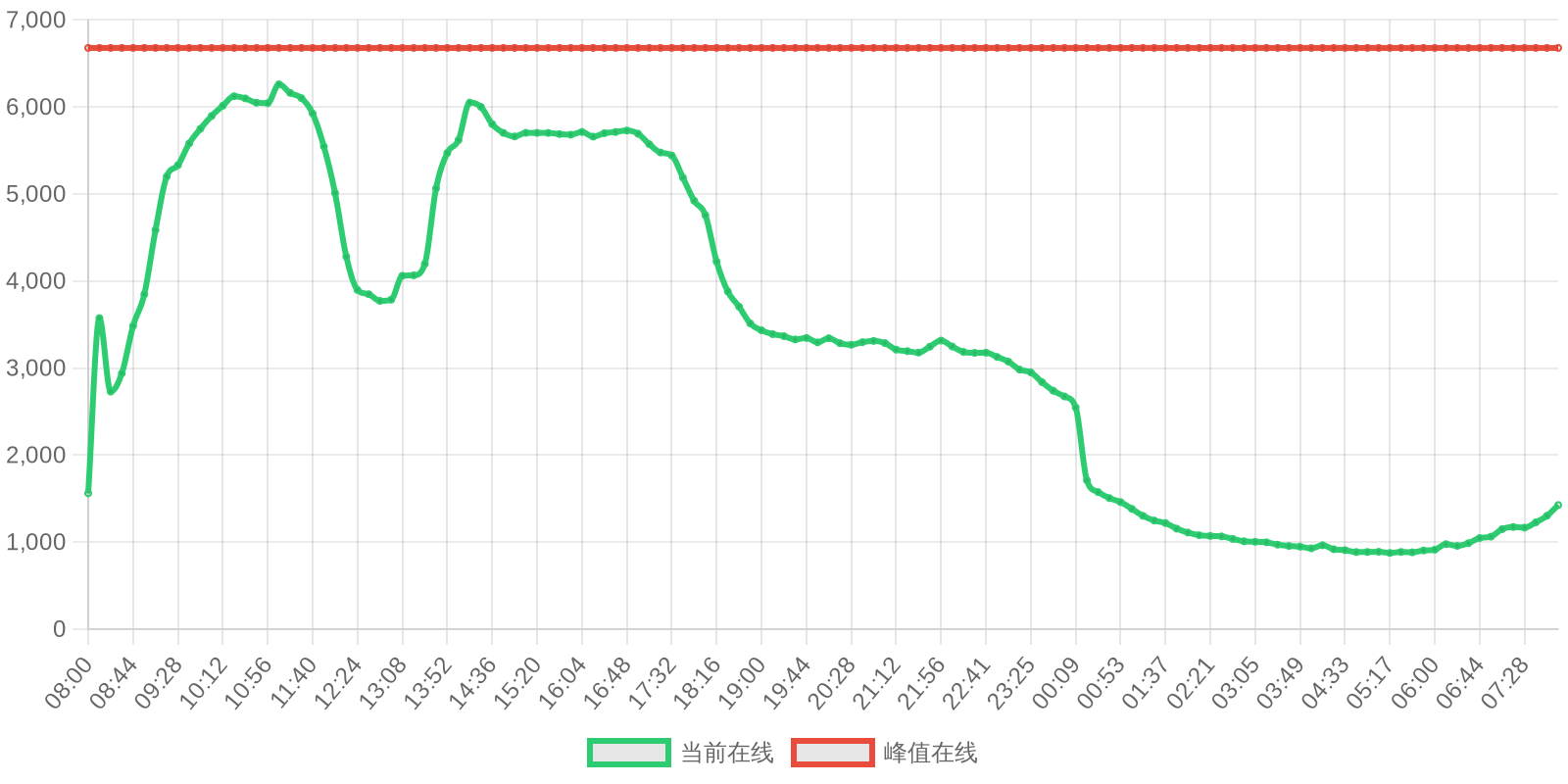
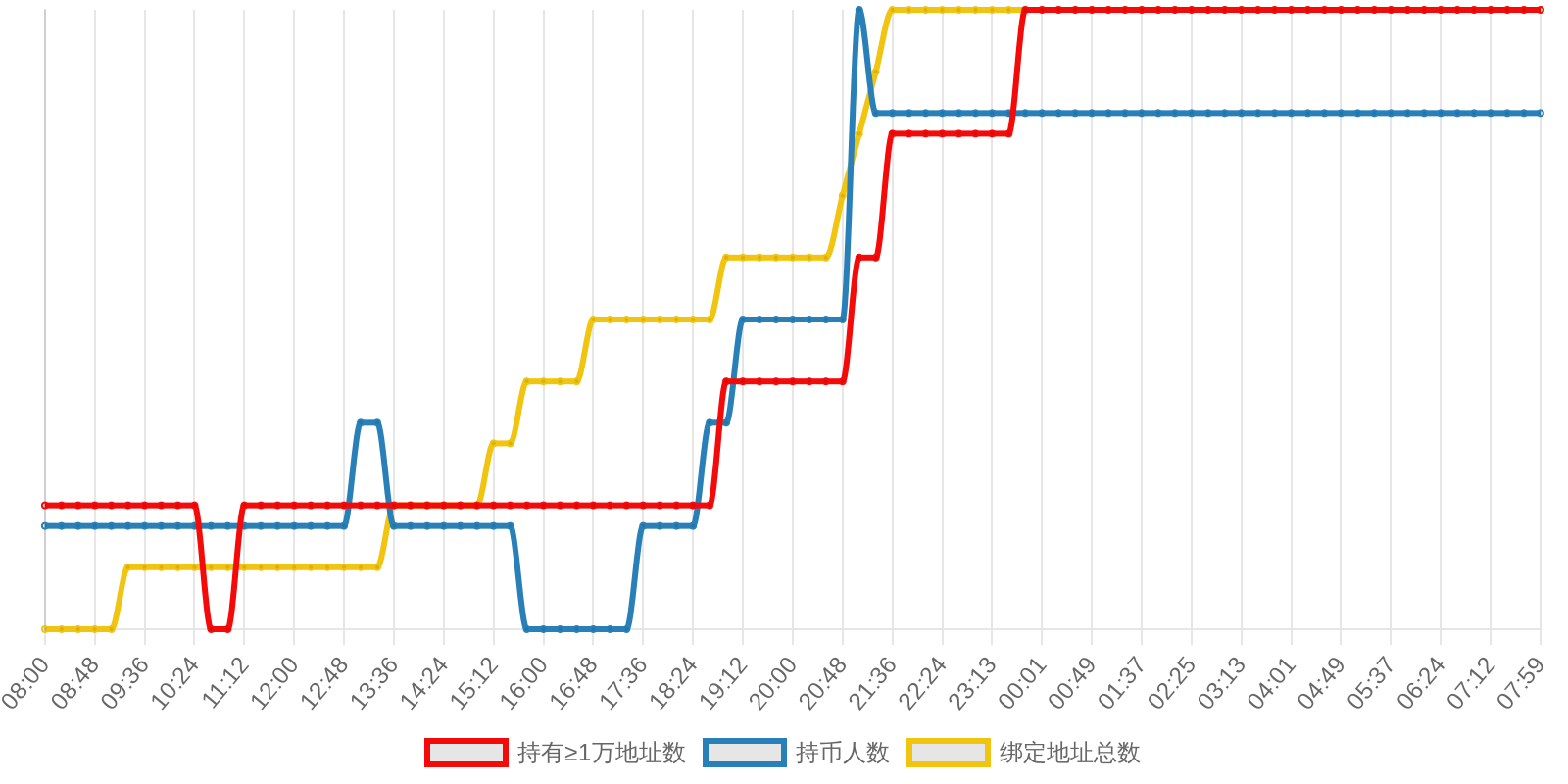
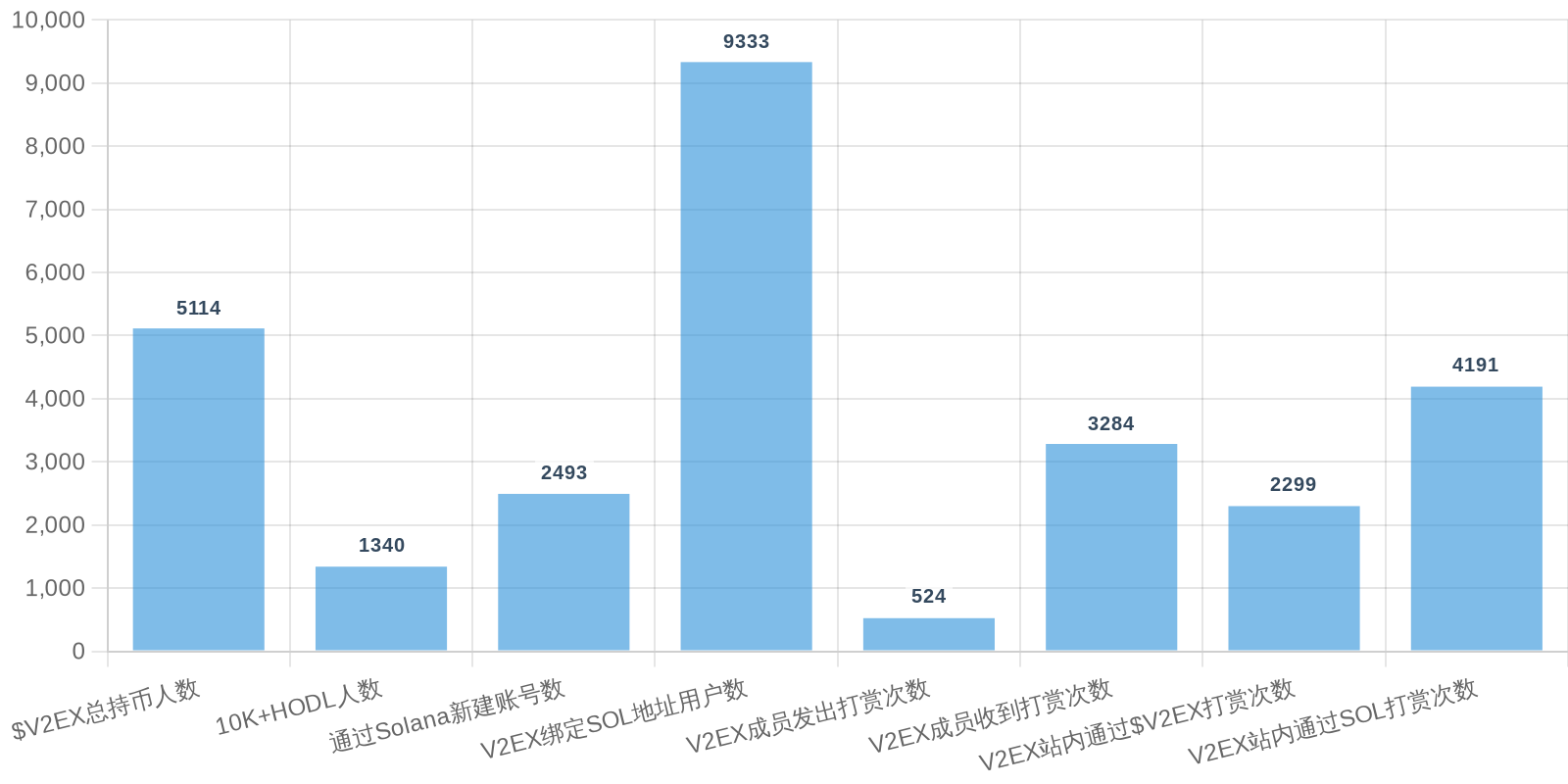
| 排名 | 地址 | 持有数量 | 持仓比例 | 排名变化 | 数量变化 |
|---|---|---|---|---|---|
| #2 | Pump.fun AMM (V2EX-WSOL) Pool | 52.34M | 5.23% | - | -0.19M |
| #9 | Meteora (V2EX-WSOL) Market | 5.03M | 0.50% | - | +19.8054 |
| #11 | Meteora (V2EX-PUMP) Market | 4.95M | 0.49% | - | +2.92K |
| #17 | Livid | 2.58M | 0.26% | - | +7.14K |
| #30 | BeCool | 1.18M | 0.12% | - | +4.72K |
| #40 | Meteora (V2EX-WET) Market | 0.87M | 0.09% | - | +565.05 |
TG 机器人订阅: 点我订阅
原始图表与数据存放于: 点我查看
此报告由 V2EX Info 提供数据, 由 Newsletter Report Bot 自动生成。
此报告仅供参考,不构成任何投资建议。投资有风险,入市需谨慎。
